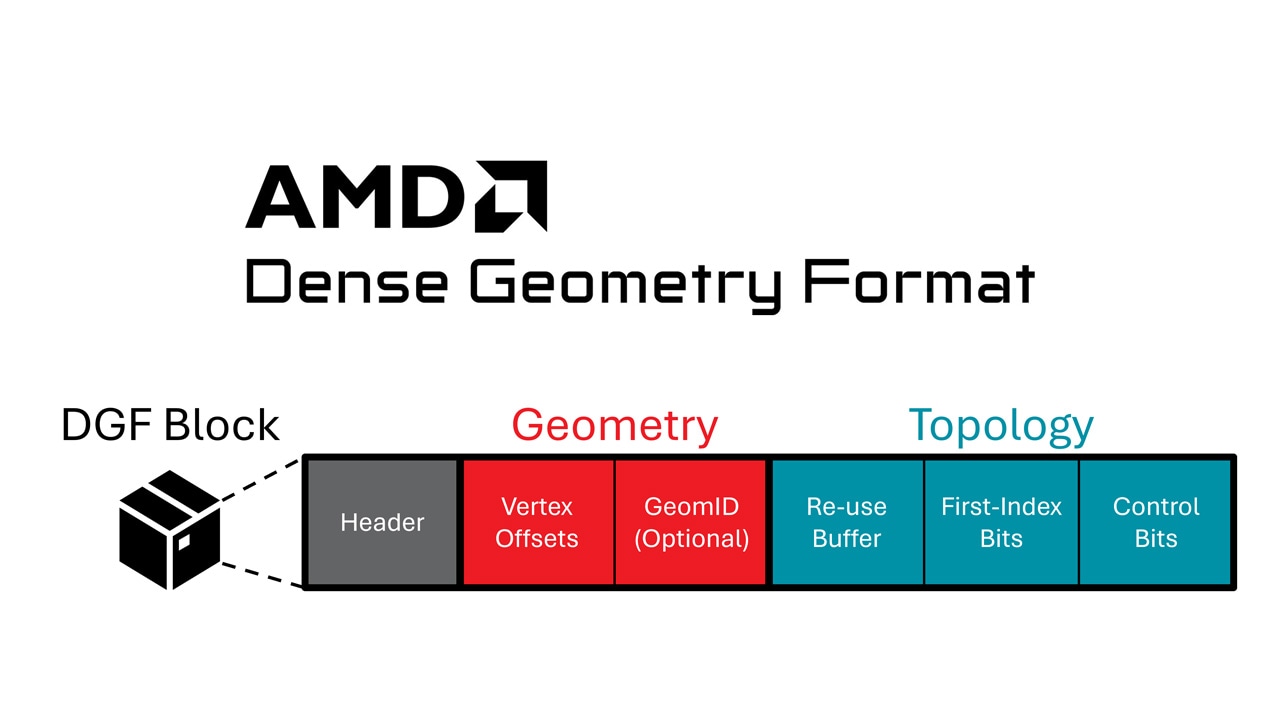
AMD FidelityFX™ Single Pass Downsampler (SPD)
AMD FidelityFX Single Pass Downsampler (SPD) 提供了一个 AMD RDNA™ 架构优化的解决方案,用于生成纹理的最多 12 个 MIP 级别。
更新 - RDNA/RDNA2
以下信息在 RDNA/RDNA2 架构方面仍然普遍适用,但解压缩发生的时间除外。
带宽一直是 GPU 上稀缺的资源。一方面,随着 HBM 等内存标准的不断发展,硬件取得了显著的进步;但另一方面,游戏以更高的分辨率、更大的缓冲区和更多的数据进行渲染,消耗了大量带宽。其中很大一部分带宽用于读取和写入渲染目标。尚未得到充分利用的是,渲染目标往往存储着缓慢变化的颜色数据。例如,天空是蓝色的,变化很小,但 GPU 会独立地处理每个像素,就好像它们包含所有唯一、不相关的值一样。
这种情况随着 Delta Color Compression(简称 DCC)的引入而改变。这是一种领域特定的压缩技术,它试图利用这种数据连贯性来减少所需的带宽。它在很多方面与典型的压缩器相似,但针对 3D 渲染进行了调整,是无损的。关键思想是处理整个块而不是单个像素。在一个块内,只有一个值以全精度存储,其余值以差值(delta)的形式存储——因此得名。如果颜色相似,差值可以比输入值使用更少的比特。DCC 在基于 GCN 1.2 或更新版本的独立 GPU 和 APU 上启用。实际的硬件实现比我刚才描述的要复杂得多。例如,它会根据访问模式(以及数据本身)调整其块大小,以优化潜在的随机访问。
新的压缩器位于 Color Block 中,允许图形像 Depth Block 压缩深度和模板目标一样压缩颜色渲染目标。这意味着不需要特殊的设置:如果目标表面被压缩,渲染就会直接通过压缩器。否则,管线不受影响。
压缩只是故事的一半,因为数据通常比写入时读取的次数要多得多。为了在读取时也能节省带宽,着色器核心已经具备了读取新的压缩颜色以及所有现有压缩表面的能力。这使得在渲染到纹理的场景中可以完全跳过解压缩操作——也就是说,从渲染目标到纹理的转换屏障实际上是一个无操作(no-op),不会触发昂贵的解压缩。
虽然 DCC 是一种“透明”功能,意味着它不需要开发者进行特定的设置,但仍有一些需要注意的细节才能最好地利用它。
清零到 0.0 和 1.0 等常见值会比任意值更快,并且能节省更多带宽。
当已知着色器不会读取它们时,可由着色器读取的目标压缩效果不如那些不需要被读取的目标。正如前面提到的,着色器核心已得到扩展,可以直接访问压缩数据,但如果禁止着色器核心访问,还有额外的压缩选项可用。MSAA 深度目标如果不需要被标记为“着色器资源”,则会受到最严重的影响,因为它们否则可以被极好地压缩。
当用作着色器资源时,D32F 实际上可能比 D16 压缩得更小,并且在不是着色器兼容时压缩方式完全相同。它们仅在分配大小和解压缩时的带宽上有所不同,而解压缩通常不那么频繁(但当一个具有许多微小三角形的密集网格渲染到一个小屏幕区域时可能会发生)。D32F 还允许您使用反向 Z 以增加精度,这样可以几乎免费地利用。请记住,在 GCN 上,没有真正的 24 位深度目标。在底层,它们被处理为 32 位,只是丢弃了 8 位精度——因此从 D24 切换到 D32 目标没有成本。
稀疏读取本来就不好,因为它们会使缓存产生抖动。压缩会使稀疏读取更糟,因为现在它会使两个缓存产生抖动。您是否曾发现更少的飞行波次或每个波次的有效线程更少会提高性能?一个可能的原因是缓存被抖动了。特别是,我们有时会观察到,在启用压缩的情况下,从阴影贴图过滤的稀疏读取性能会急剧下降。这尤其发生在以“超”图形质量模式渲染时,因为设置通常会调到最高。如果阴影看起来有噪声和锯齿,说明缓存正在被抖动!预滤波或选择较低分辨率会看起来更好,运行也更快。
部分写入需要特别小心。在非压缩数据的情况下,可以简单地屏蔽写入。对于压缩数据,这不起作用,因此必须先读取、解压缩、更新,然后写回以保留未触及的通道。为了有效利用压缩,最好在数据不再需要混合时完全覆盖底层数据,因此如果可能,请同时写入所有通道。
如果将字段任意打包到 G-Buffer 中,请将高度相关的位放在每个通道的最高有效位 (MSBs) 中,并将噪声数据放在最低有效位 (LSBs) 中。这将压缩得更好,因为它响应典型的数据模式类似。
即使您已遵循了上述所有规则,DCC 有时仍可能被禁用,因为并非 GPU 的所有部分都能读取和写入压缩数据。在这些情况下,屏障会导致解压缩。理解这些情况何时可能发生很重要。