使用 Radeon Developer Tool Suite 进行光线追踪简介
在此视频中,Can Alper 介绍了 RRA V1.0。他解释了如何使用 RDP 捕获游戏以及何时使用 RRA。
在几何体创建和场景组织方面,优化光线追踪管线与优化光栅化管线相比,具有截然不同的(并且经常相互冲突的)策略。Radeon™ Raytracing Analyzer (RRA) 可以帮助您研究这些新策略并缓解瓶颈。
本文将讨论开发者可能遇到的常见陷阱,如何使用 RRA 进行诊断,以及如何解决它们。以下所有示例追踪都可以在 RRA 的 公共 GitHub 页面 的 samples 文件夹中找到。
光线追踪中固有的权衡是 BVH(包围盒层级)构建时间和 BVH 遍历时间。通常,构建更高质量的 BVH 需要更多时间,但会带来更高效的光线遍历。驱动程序主要负责管理这种权衡,同时考虑到传递给图形 API 的构建标志,例如:
DirectX® 12 中的 D3D12_RAYTRACING_ACCELERATION_STRUCTURE_BUILD_FLAG_PREFER_FAST_TRACE 或 D3D12_RAYTRACING_ACCELERATION_STRUCTURE_BUILD_FLAG_PREFER_FAST_BUILD。
Vulkan® 中的 VK_BUILD_ACCELERATION_STRUCTURE_PREFER_FAST_TRACE_BIT_KHR 或 VK_BUILD_ACCELERATION_STRUCTURE_PREFER_FAST_BUILD_BIT_KHR。
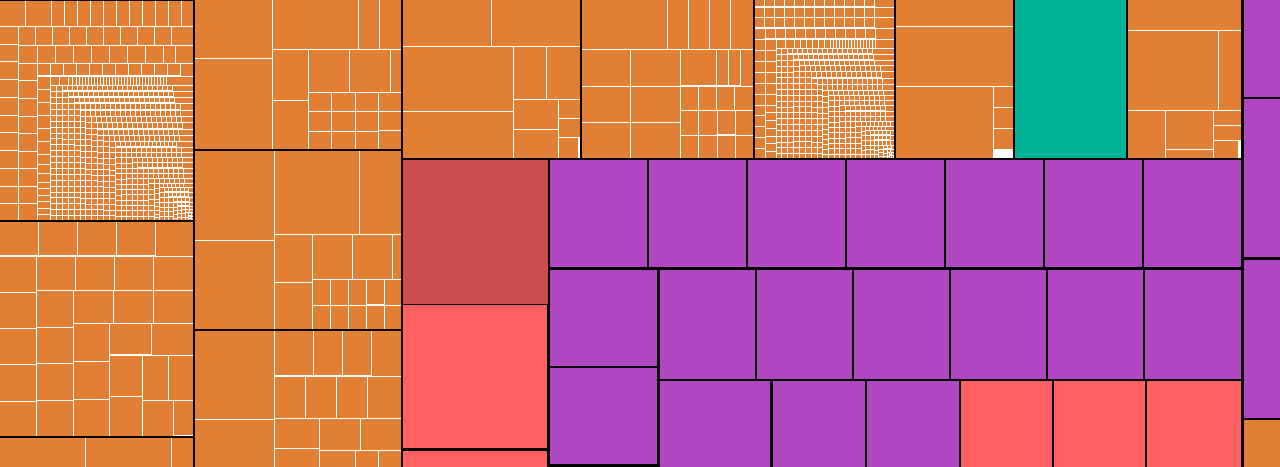
然而,开发者负责将应用程序的网格数据分组到包含在底层加速结构 (BLAS) 中的几何体中,并将它们的实例放置到顶层加速结构 (TLAS) 中。其包围盒占用大量空白空间或与其他实例的包围盒发生严重重叠的实例会损害遍历性能。一个常见的例子是,将游戏的整个地形视为一个大的 BLAS,其包围盒与场景中的所有内容重叠。

在上图中,我们可以看到房屋和城堡完全被地形的包围盒包围,而这个包围盒还占用了大量空白空间。

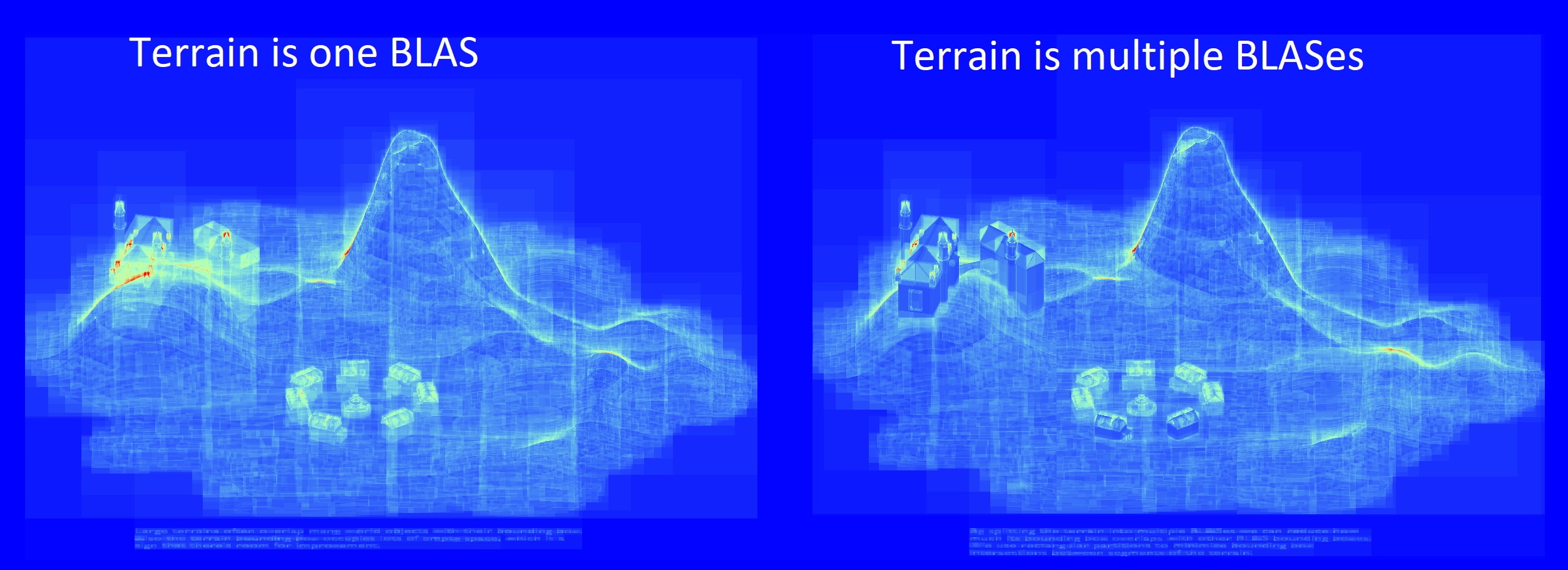
特别地,请注意当地形被分割成块时,城堡和最近的两座房屋的颜色要暗得多(表明遍历成本较低)。
这两座前景房屋比其他房屋受益更多的原因在于驱动程序如何决定构建 TLAS。这超出了开发者的直接控制范围,但通过减少实例重叠,这为驱动程序提供了构建更优化的加速结构的机会。
本质上,这个例子与上一个相同:尽量避免实例重叠。但以下是在 RRA 中诊断此问题的更通用方法。
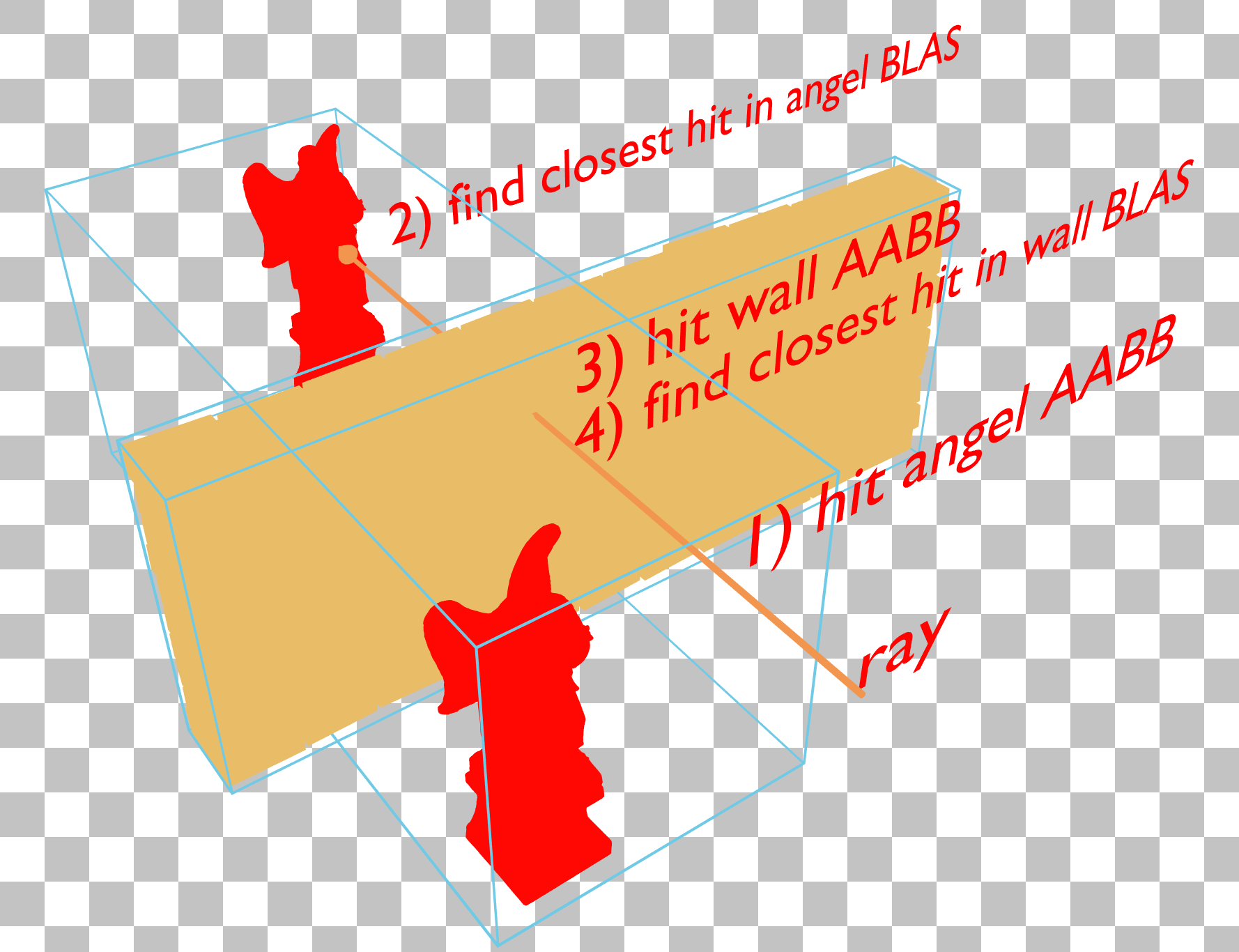

这种 X 射线效果,在遍历计数器模式下,远处的 the angel statue 可以穿过墙壁看到,这是需要避免的。这表明即使大部分被墙壁遮挡,远处的 the angel statue 仍然会产生遍历成本。
在此示例中,两个 the angel statue 位于同一个 BLAS 中,因此 the angel statue 和墙壁的蓝色包围体积发生了交叉,导致光线首先遍历 the angel statue 的 BLAS,然后遍历并被墙壁的 BLAS 终止。
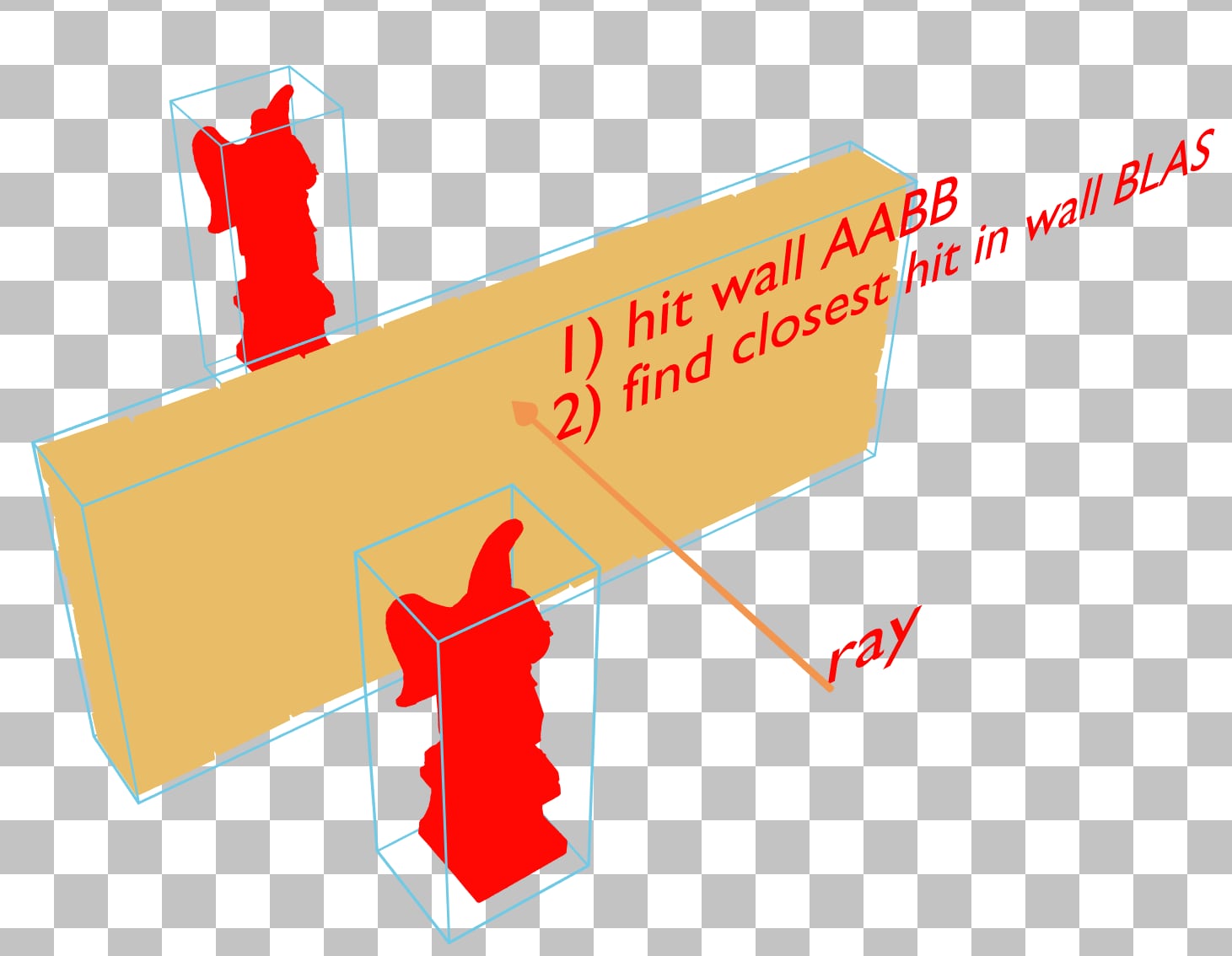

通过将 the angel statue 的 BLAS 更改为仅包含一个 the angel statue 并对其进行两次实例化,the angel statue 的包围体积不再与墙壁的发生交叉。这使得驱动程序有机会构建一个 TLAS,可以在无需遍历远处 the angel statue 的 BLAS 的情况下更早地终止遍历。请记住,即使在减少实例重叠后,X 射线效果仍然可能持续存在,具体取决于驱动程序如何构建加速结构,但通过最小化重叠,总体 TLAS 质量预计会更高。
在光栅化管线中,三角形网格在其局部空间中的方向对性能没有影响。这在光线追踪管线中并不成立。
目前,BVH 构建方法使用轴对齐包围盒的层级供光线遍历。三角形与坐标轴(x、y 和 z 轴)的对齐程度越低,其包围盒就会越大,这会增加光线与包围盒相交但与三角形未相交的概率。这会导致找到最近命中的遍历次数增加,因为需要交叉更多的盒子。
在 RRA 中测量三角形在轴上对齐的程度,使用的是表面积启发式 (SAH),这是一个介于 0 和 1 之间的数字,与光线与三角形相交的概率成正比(给定光线与包围盒相交)。因此,0 表示不好,表示三角形不太可能相交;1 表示好,表示三角形很可能相交。
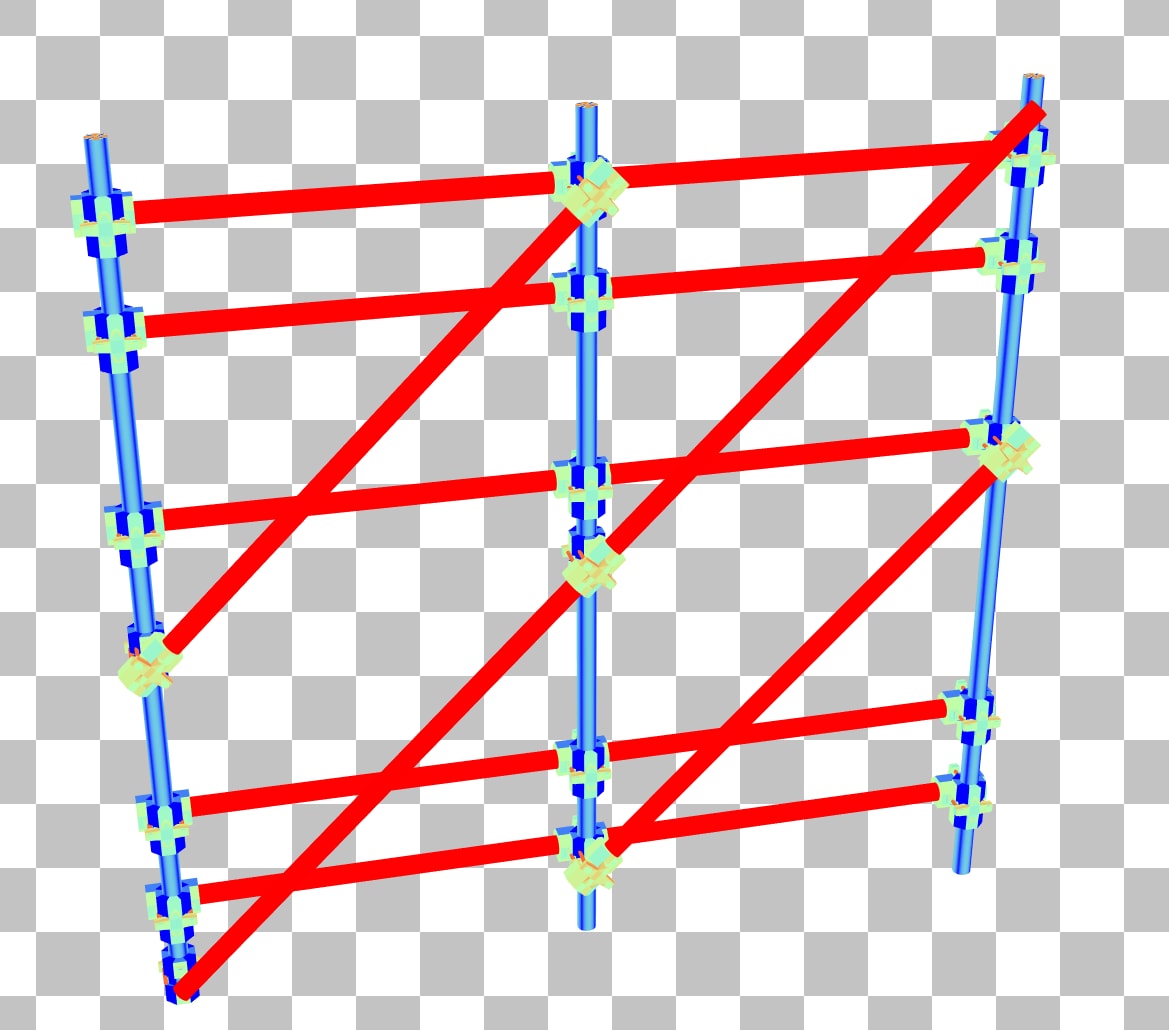
在三角形 SAH 着色模式下,此脚手架中的许多杆件呈亮红色,表明 SAH 非常低。这是 BLAS 可以在局部空间中更好地对齐的主要指示。
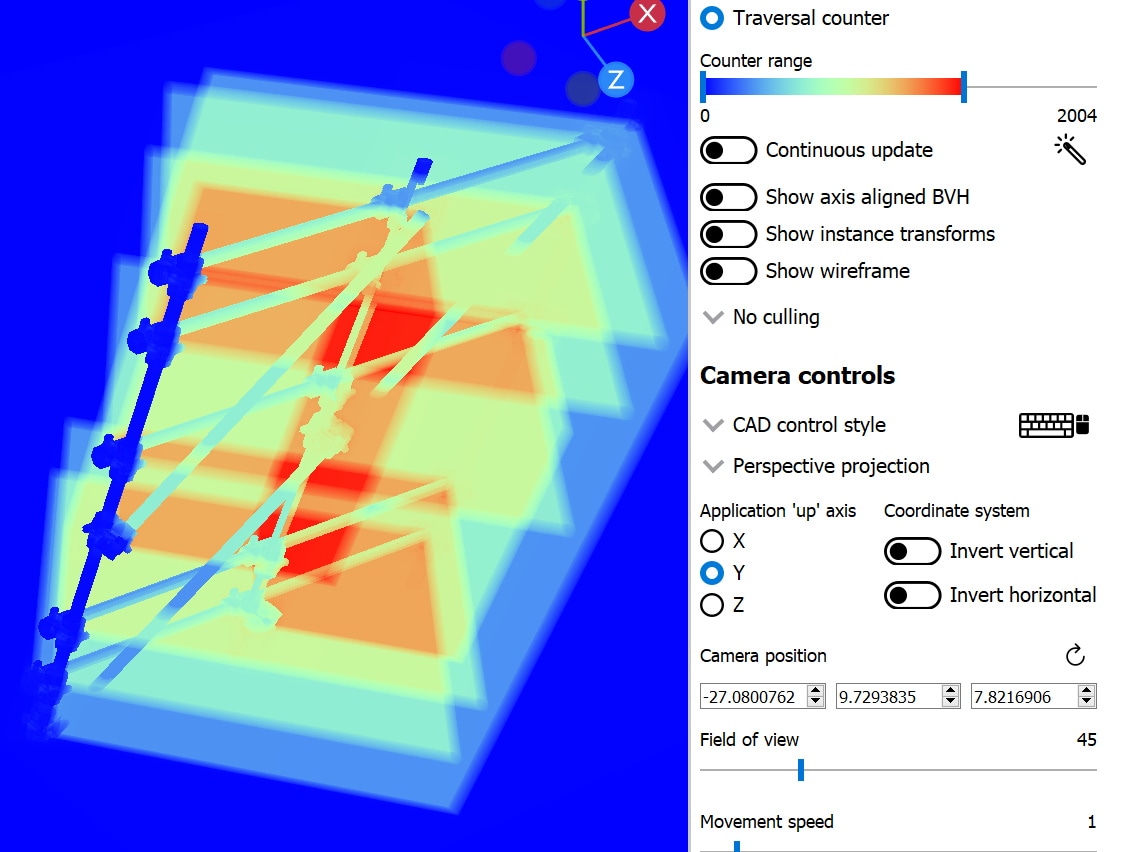
切换到遍历计数器模式,脚手架产生了超过 2000 的遍历计数,当它出现在应用程序的屏幕上时,很可能会导致帧率明显下降。
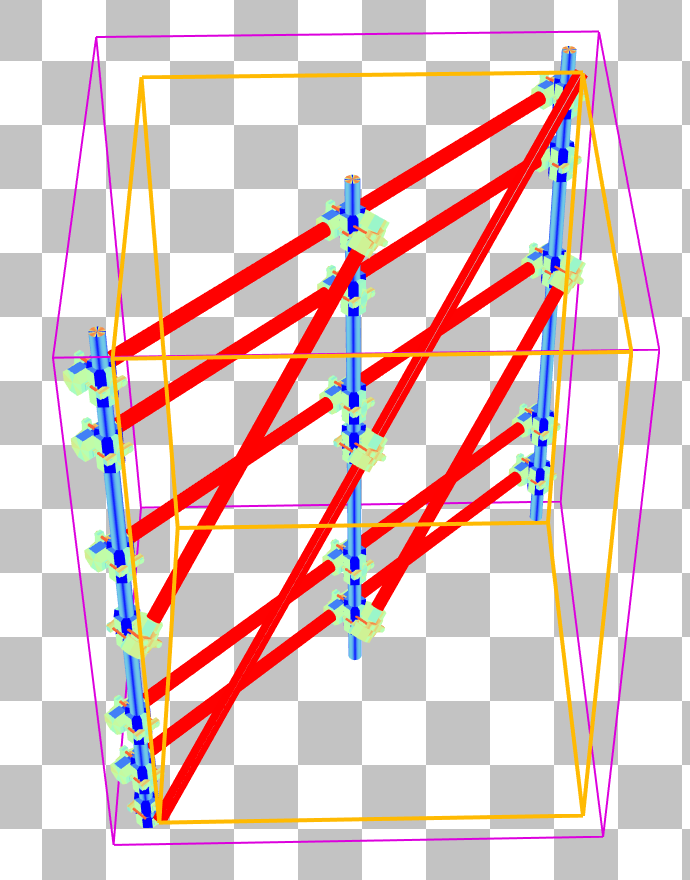
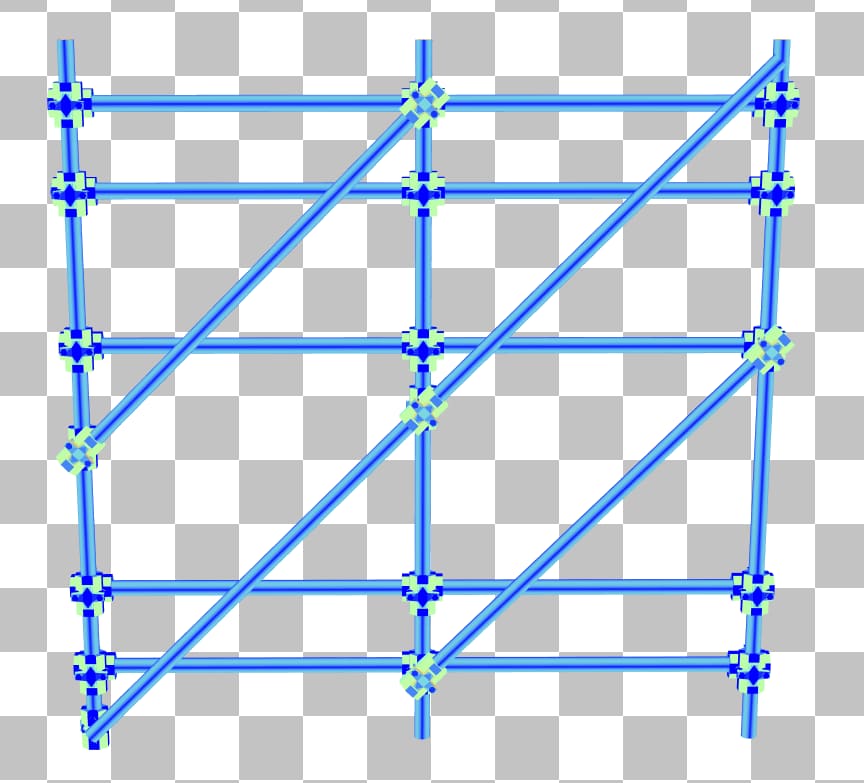
双击脚手架将进入 BLAS 面板,显示脚手架相对于 x 轴旋转了 45 度。选择对角线杆上的一个三角形会显示其包围盒不必要地大,几乎覆盖了整个 BLAS。
通过将脚手架网格在 BLAS 空间中旋转 45 度,使水平杆与 x 轴对齐,可以轻松地进行改进。这将产生以下 BLAS:
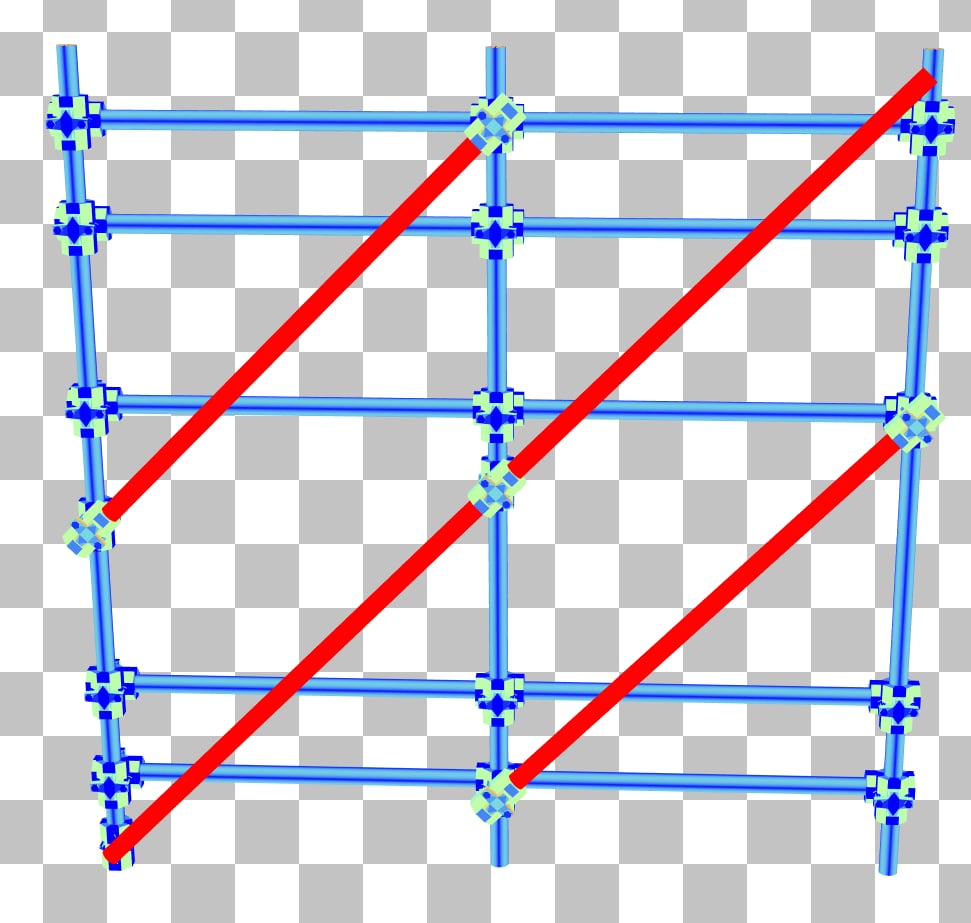
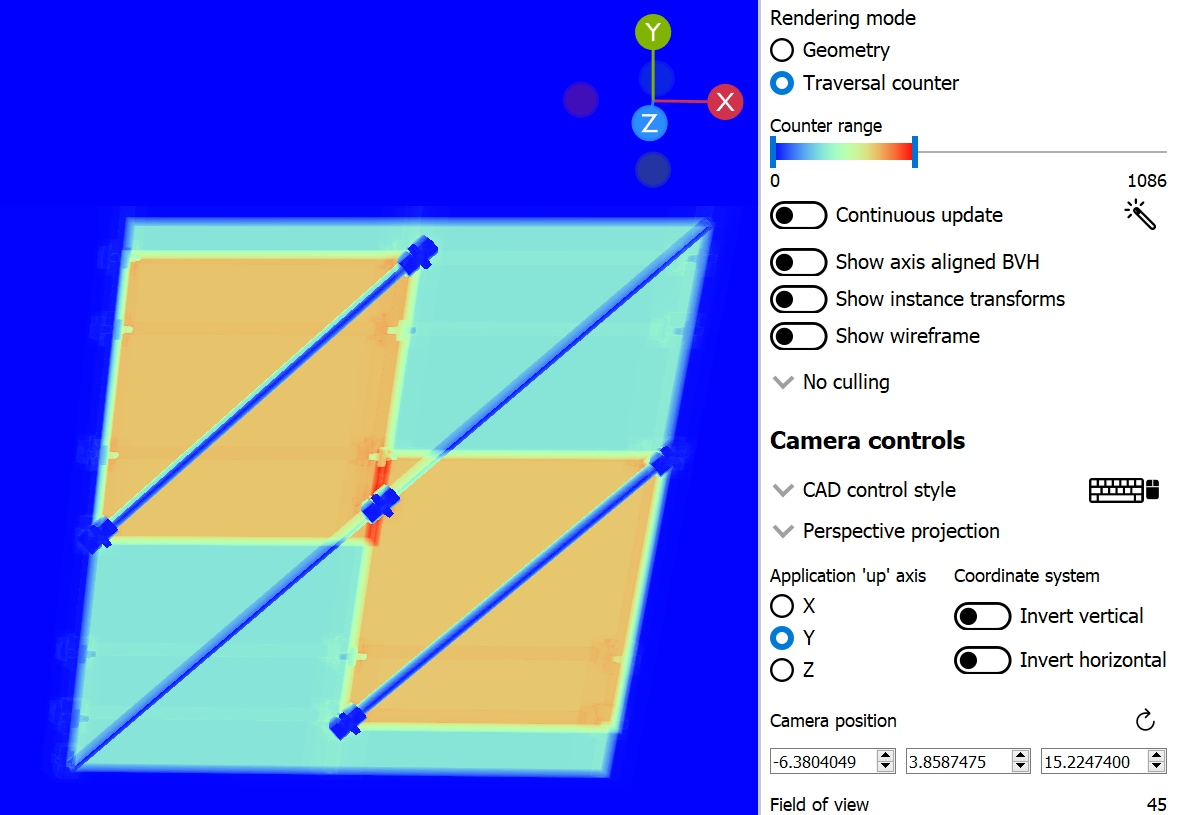
现在,垂直杆具有更好的 SAH,遍历计数器已显著下降至约 1000 次迭代。此调整没有任何权衡;它纯粹是有益的。
但对角线杆仍然存在问题,并且是导致此 BLAS 大部分遍历时间的原因。通过将脚手架分成多个 BLAS,在局部空间中对齐每个 BLAS,然后使用它们的实例变换将它们重新放置回原来的形状,可以得到以下结果:
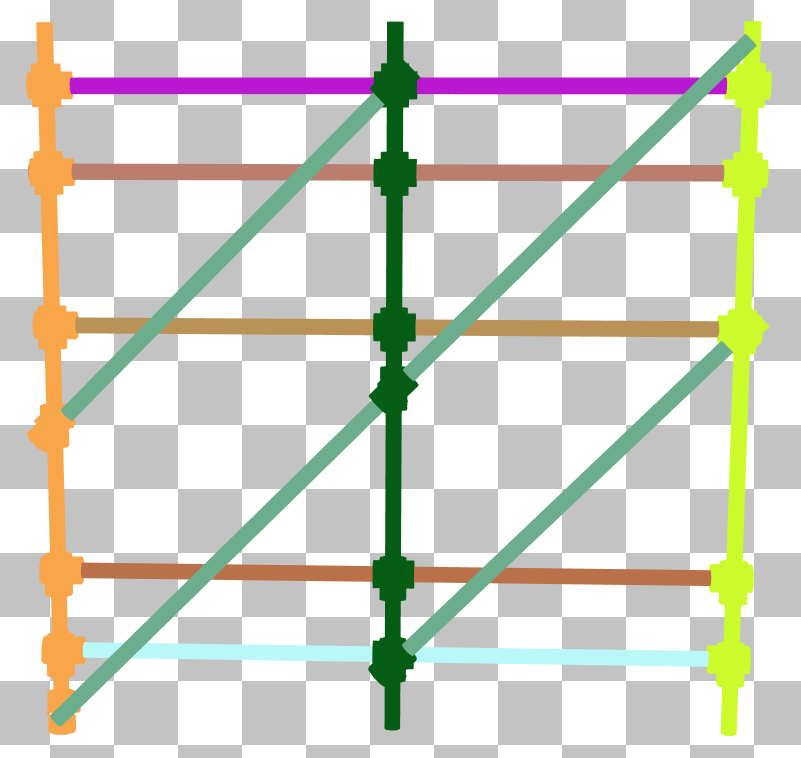
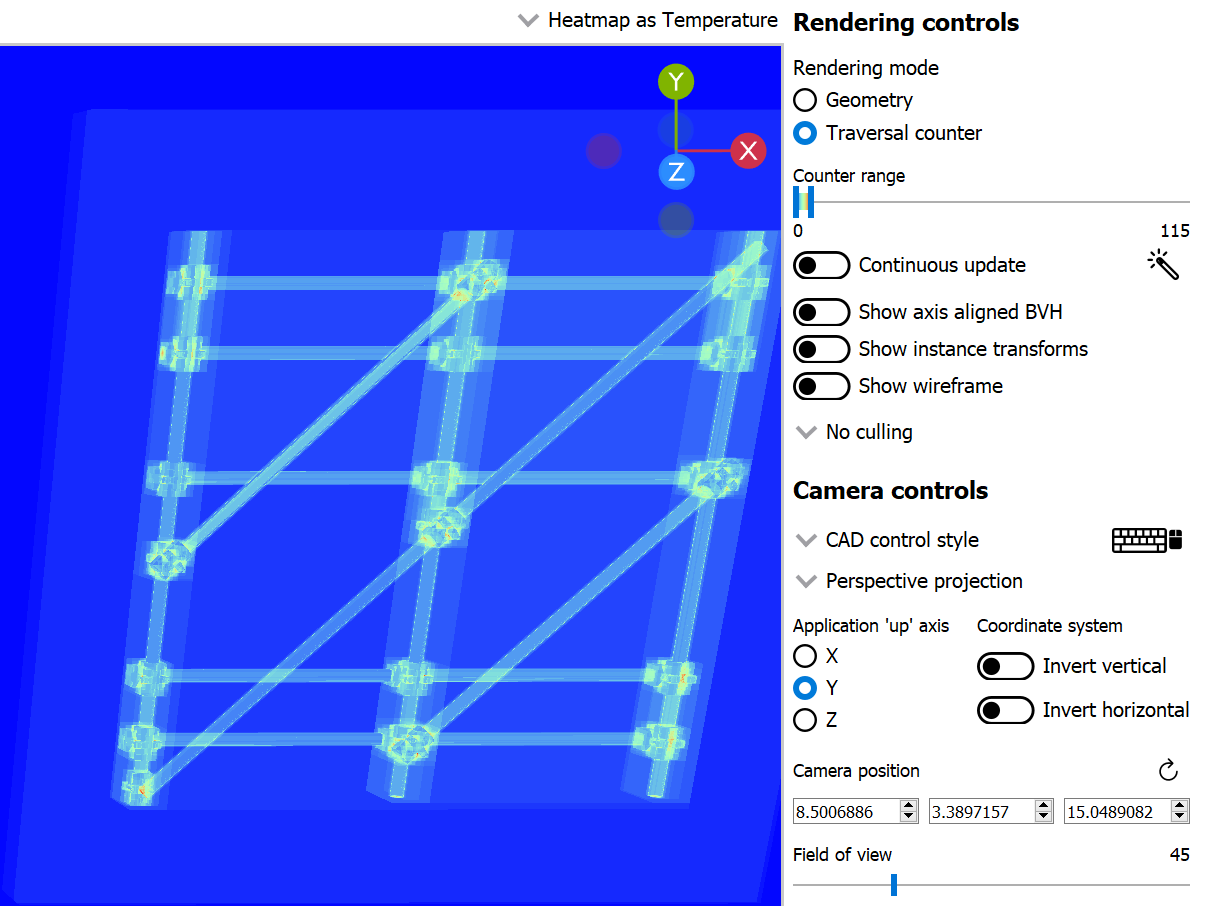
唯一的实例着色模式(左侧)显示了脚手架是如何被分成多个 BLAS 并实例化的。SAH 着色模式(中间)表明不再有任何有问题的三角形,遍历计数(右侧)下降了一个数量级。如果您决定采用这种方法,请谨慎行事,因为创建更多实例会增加 TLAS 的构建时间。请务必进行性能分析,以确定此权衡是否适合您的项目。此外,将 BLAS 分成多个 BLAS 通常会导致实例重叠,正如我们在下一个示例中将看到的,这有时会使遍历成本变得更糟,尽管 SAH 更好。
在上一个示例中,存在一种情况,即将一个 BLAS 分成多个组成 BLAS 可以通过在局部空间中对齐每个单独的 BLAS 来降低遍历成本。请谨慎并进行性能分析以决定是否采用此方法。除了更长的 TLAS 构建时间之外,这实际上也可能损害遍历时间,即使 SAH 得到改善。


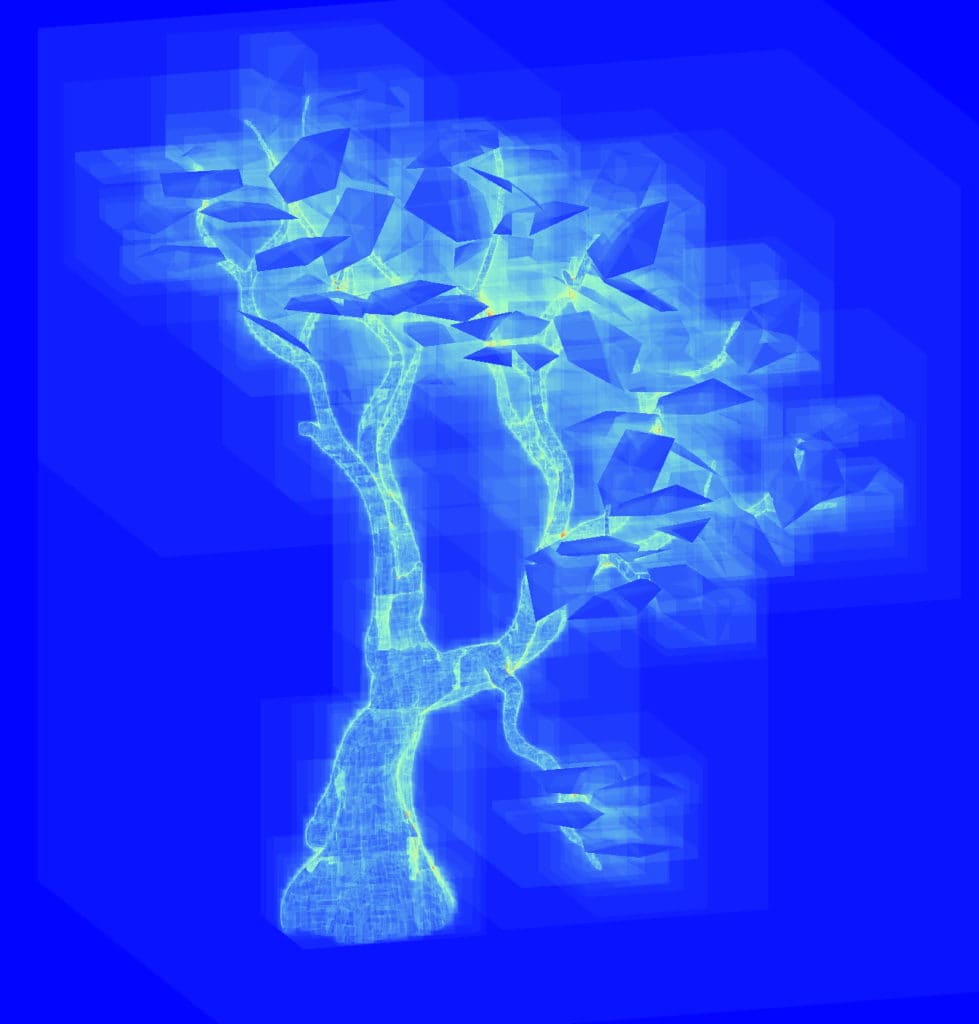
考虑上面的树,它是一个单一的 BLAS。树叶朝向所有方向,在局部空间中与轴的对齐程度不高,因此可能会诱使人根据树叶的朝向将其分成多个 BLAS,以降低其 SAH。



唯一的实例着色模式(左侧图像)显示了用于构建每个树的所有实例。在将树叶分成 6 个单独的 BLAS,根据方向将它们分组并在局部空间中旋转后,树叶的 SAH(中间图像)已降低,但由于所有实例的重叠,遍历计数(右侧图像)变差了,并且更多的实例也对 TLAS 的构建时间产生了负面影响。
一个常见的错误是将网格分成多个 BLAS,也许每种材质一个。


唯一的实例着色模式显示了网格按材质分成多个 BLAS(左侧)和包含在单个 BLAS 中的网格(右侧)。


几何体索引着色模式显示,多个 BLAS 版本(左侧)未使用的多个几何体索引,而单个 BLAS 版本(右侧)为每种材质有一个几何体索引。

切换到遍历计数器渲染模式,很明显,在 BLAS 中使用多个几何体比使用多个 BLAS 的版本具有更低的遍历成本,因为前者会导致显著的实例重叠。使用更少的实例对 TLAS 构建时间产生积极影响,这是一个额外的好处。
显着拉伸或倾斜底层 BLAS 的实例变换通常不是最优的,因为 BLAS 是相对于非变形网格构建的。


这里是局部空间中的两个 BLAS。它们是相同的网格,只是左侧的在 y 轴上进行了缩小。
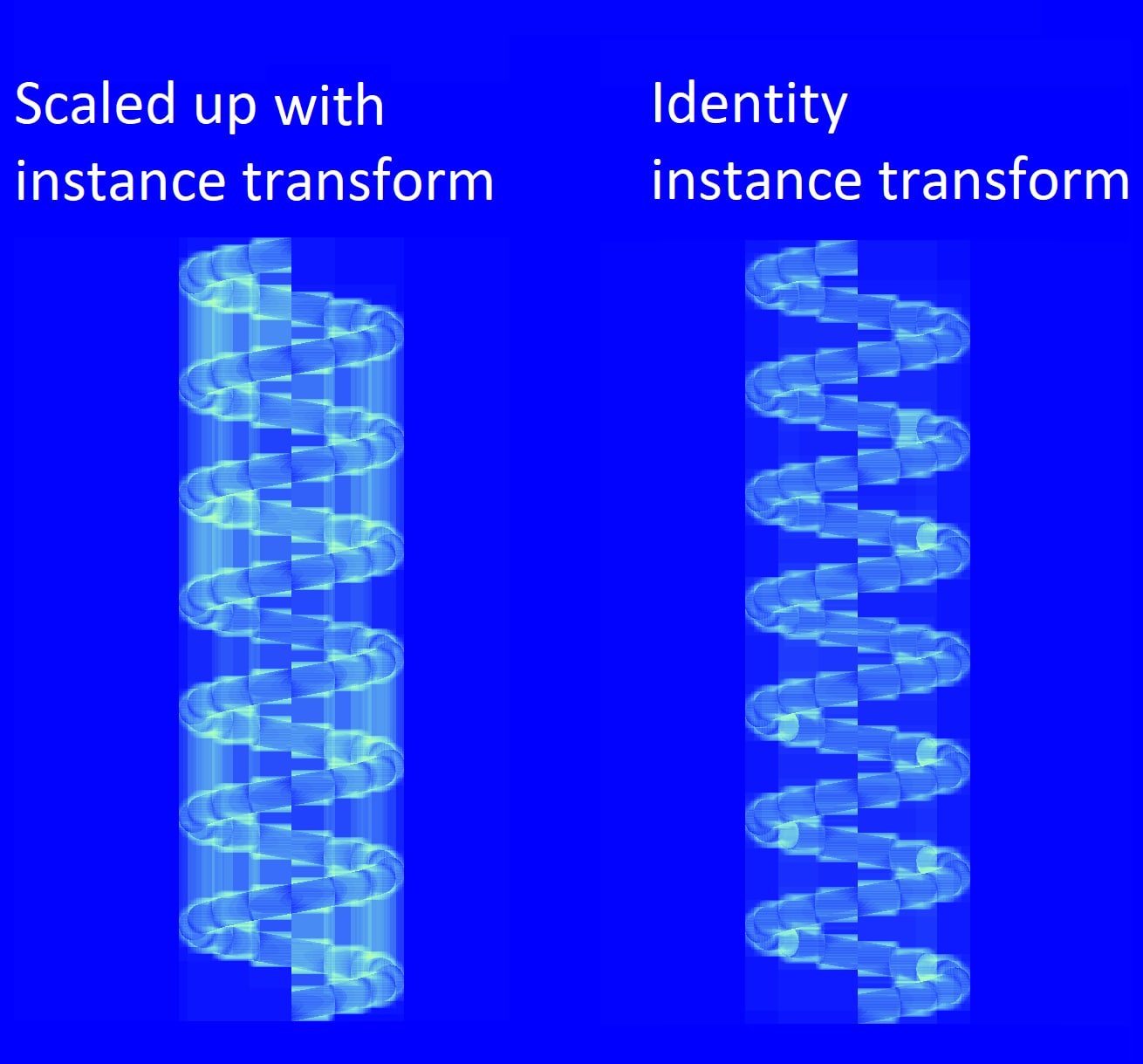
在全局空间中,左侧的弹簧在 y 轴上进行了缩放,并使用实例变换来补偿其在局部空间中的缩小,因此两个弹簧看起来完全相同。但是,具有身份实例变换的弹簧的遍历计数更好,因为它的 BLAS 是相对于此变换构建的。
在光栅化管线中,正面/背面剔除是一种优化。在光线追踪管线中,启用任何一种都会损害光线遍历性能,因为任何被剔除的三角形仍然需要进行测试。它只是不会被视为最近命中的候选者,因此遍历算法不会像没有剔除时那样提前终止。
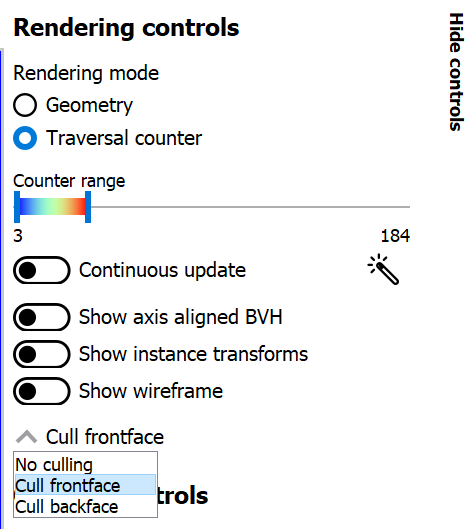
在几何体渲染模式下,剔除下拉菜单仅影响视口渲染器,并不反映捕获的应用程序。另一方面,在遍历渲染模式下,剔除模式扮演了着色器中传递给 trace ray 调用的正面/背面剔除标志的角色。这意味着可以通过实例标志为每个实例覆盖或修改剔除行为。通过选择正面剔除,实例之间的遍历成本差异变得明显。

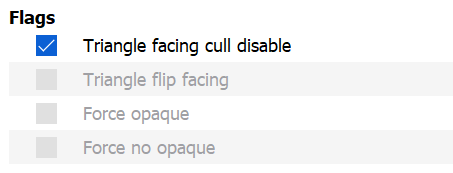
有两个实例,其中一个启用了“三角形面剔除禁用”标志。此标志优先于 trace ray 标志(或在这种情况下,剔除模式下拉菜单)。
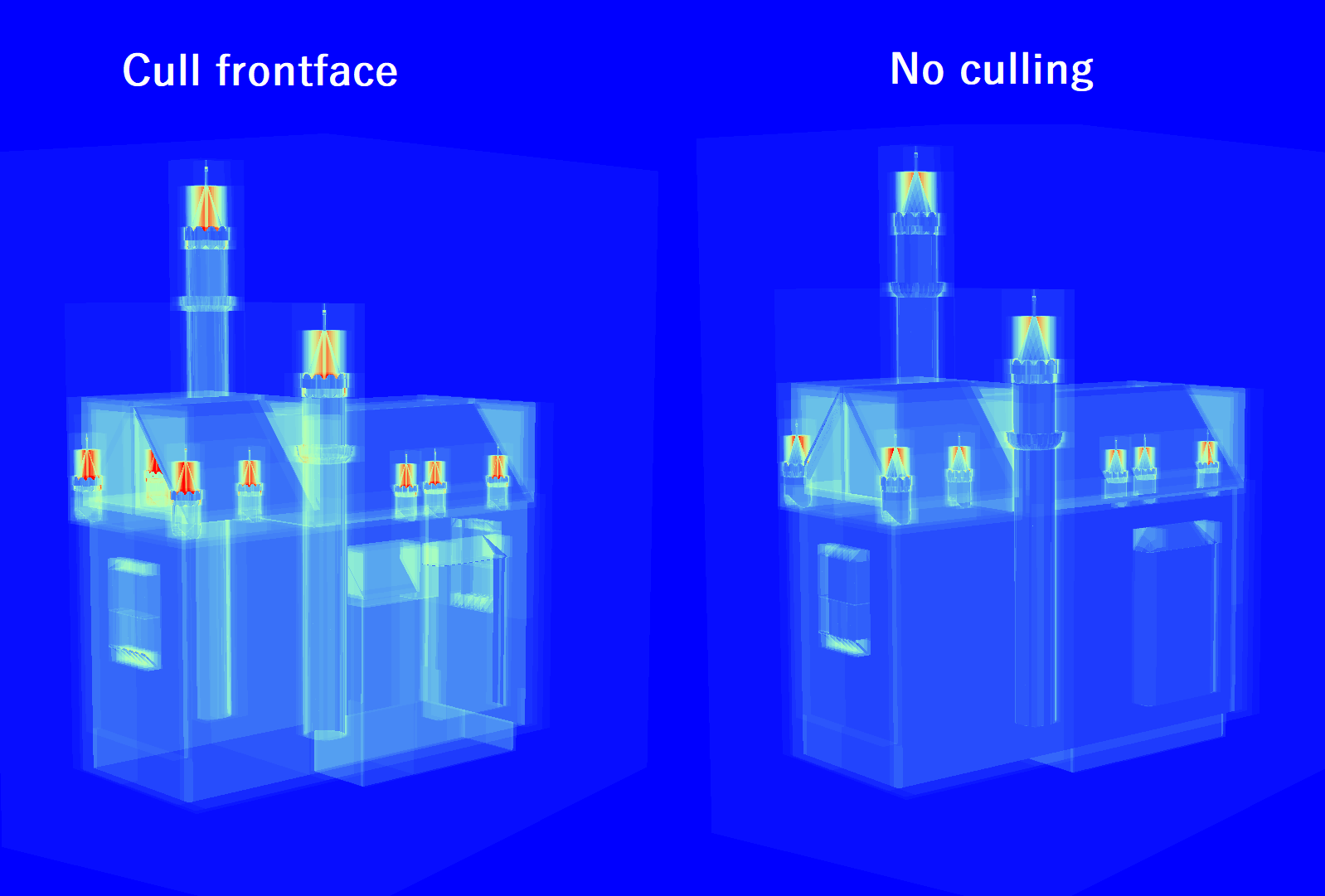
切换到遍历计数器渲染模式显示,禁用剔除的实例具有较低的遍历成本。
在禁用不需要的光线追踪功能(如面剔除)时,最好使用编译时射线标志来禁用它们。这允许编译器优化着色器。例如,不将 RAY_FLAG_CULL_BACK_FACING_TRIANGLES 标志传递给 HLSL 中的 TraceRay(),而是通过实例标志传递标志并禁用剔除,这样做更好。同样,将 RAY_FLAG_FORCE_OPAQUE 传递给 TraceRay() 比在每个实例上启用“强制不透明”实例标志能够带来更多的编译器优化。强制不透明的好处是消除了昂贵的 AnyHit 着色器调用。
在构建 BLAS 时,DirectX 12 和 Vulkan 允许您从头开始构建一个,或者使用类似的现有源 BLAS 来构建新的目标 BLAS。使用更新模式可以加快 BLAS 构建速度,因为它可以在源 BLAS 中重用部分。
一个常见的用例是角色动画或网格变形,因为从一帧到下一帧的 BLAS 变化很小。考虑弓被拉动的动画情况。
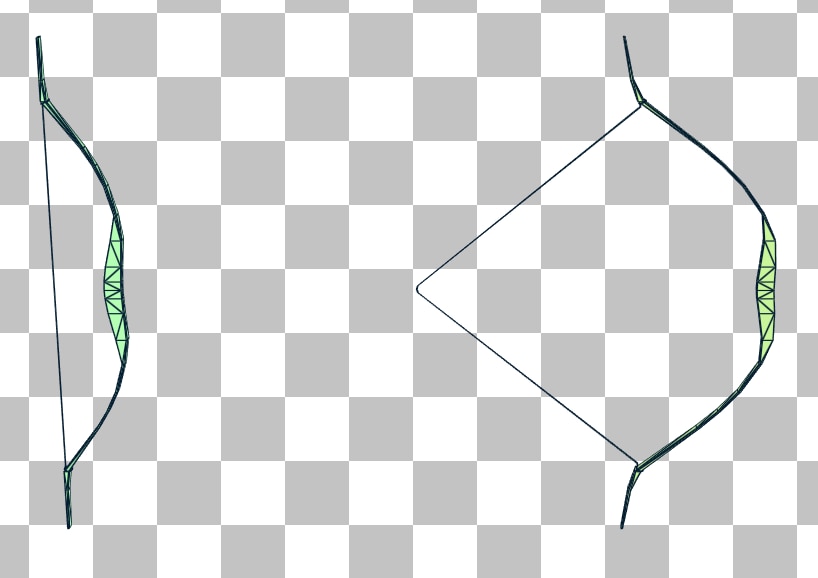
现在,让我们比较一下使用构建模式与使用更新模式(以未拉伸的弓作为源)构建的拉伸弓的 BVH 质量。
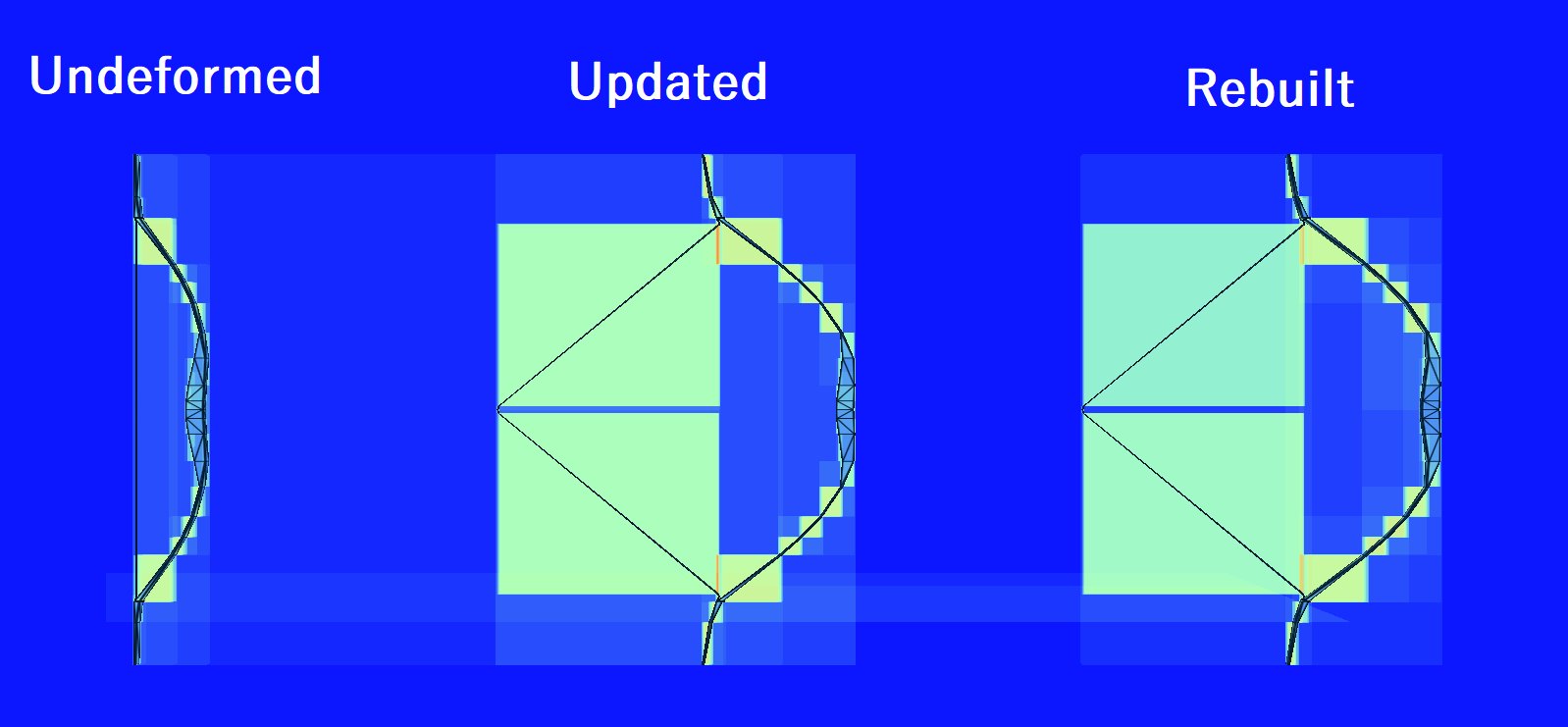
遍历计数器模式显示,更新与重新构建的 BLAS 的射线遍历所需时间没有显着差异,但在构建时间上节省了时间。
现在考虑打开门的动画。
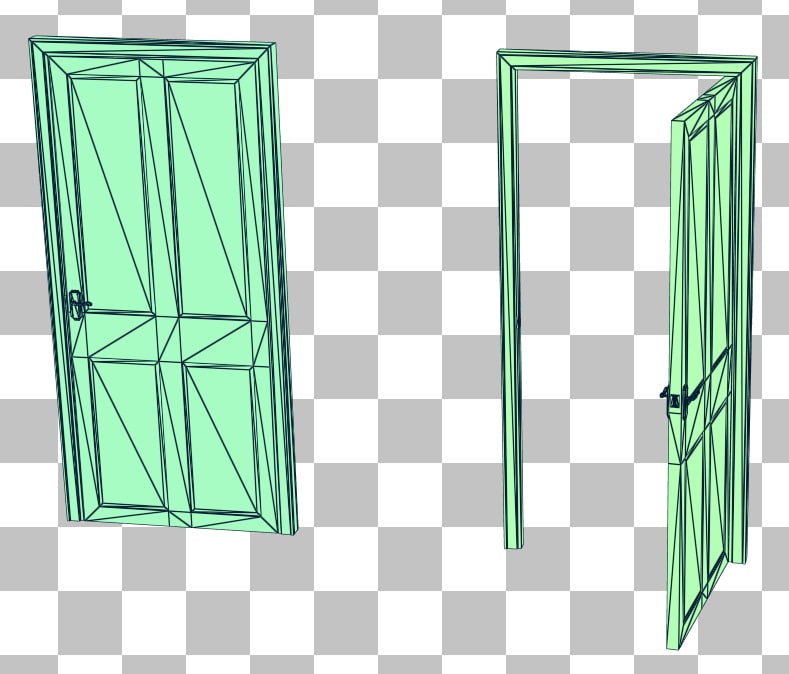
我们再次比较更新和重新构建的 BLAS 之间的 BVH 质量。
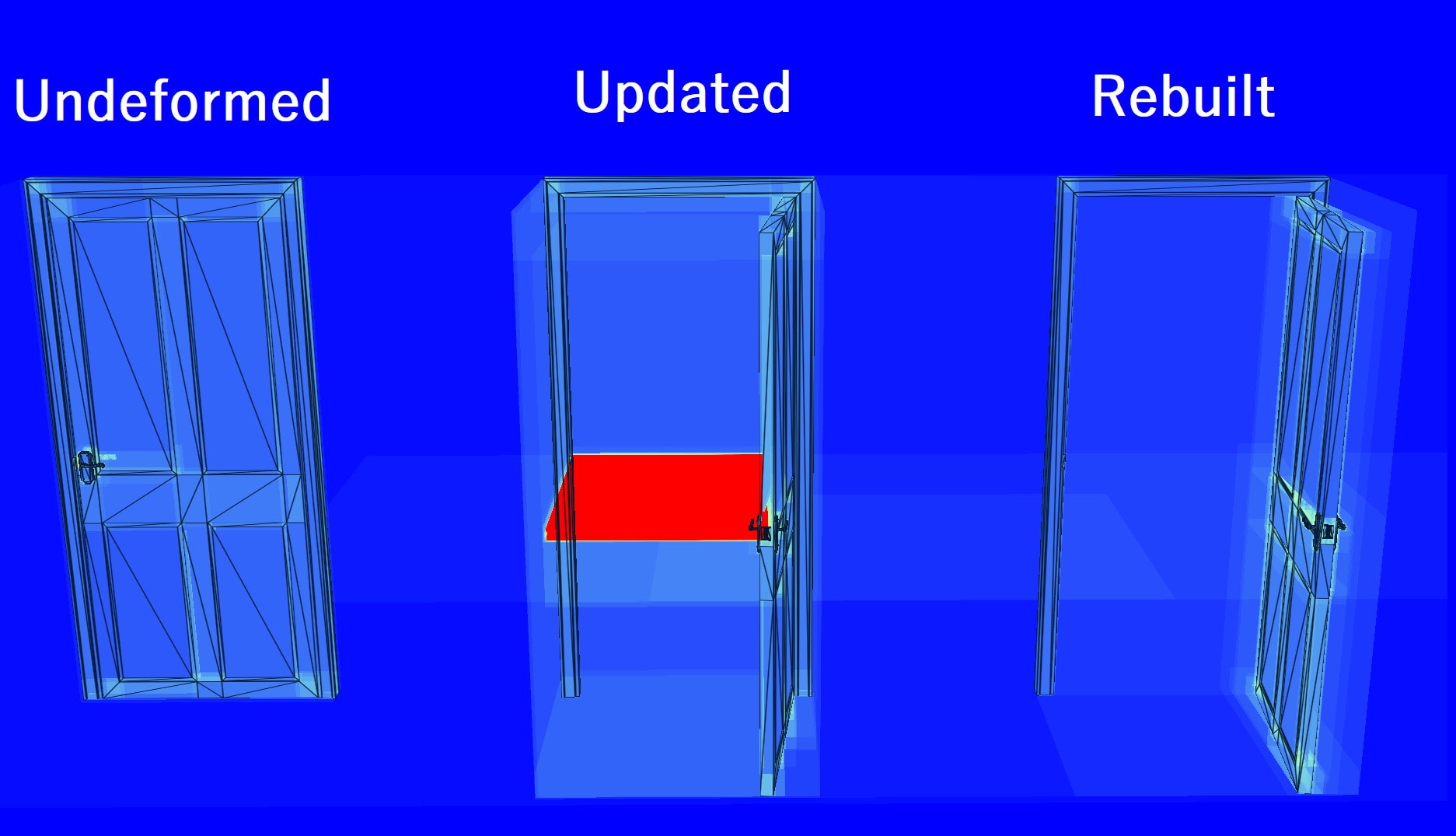
哪里出错了?更新的 BLAS 中有一个很大的区域消耗了大约 1100 次遍历步骤。为什么弓和门之间会有如此大的差异?
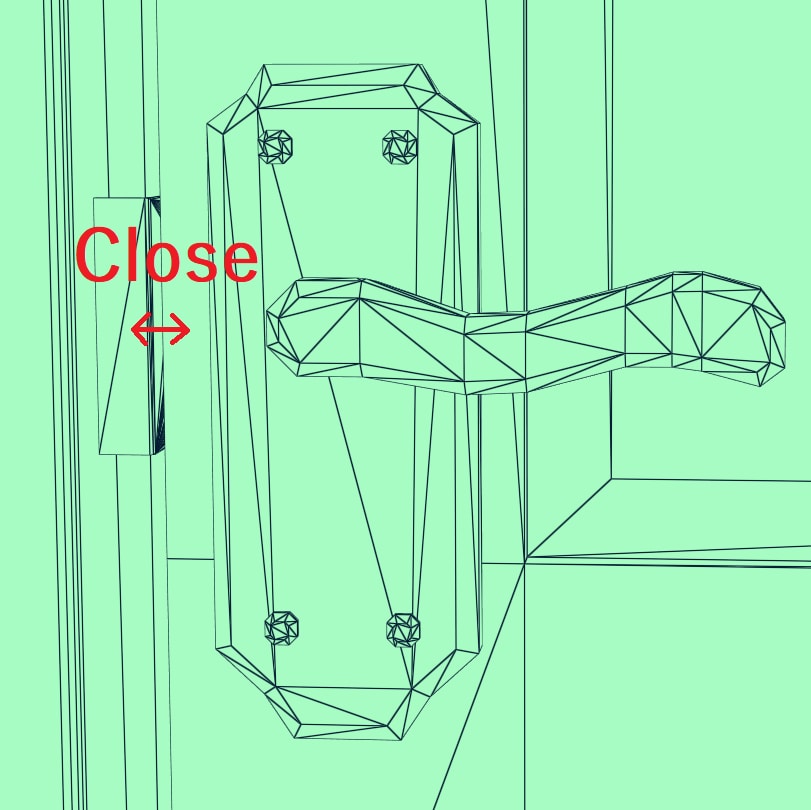
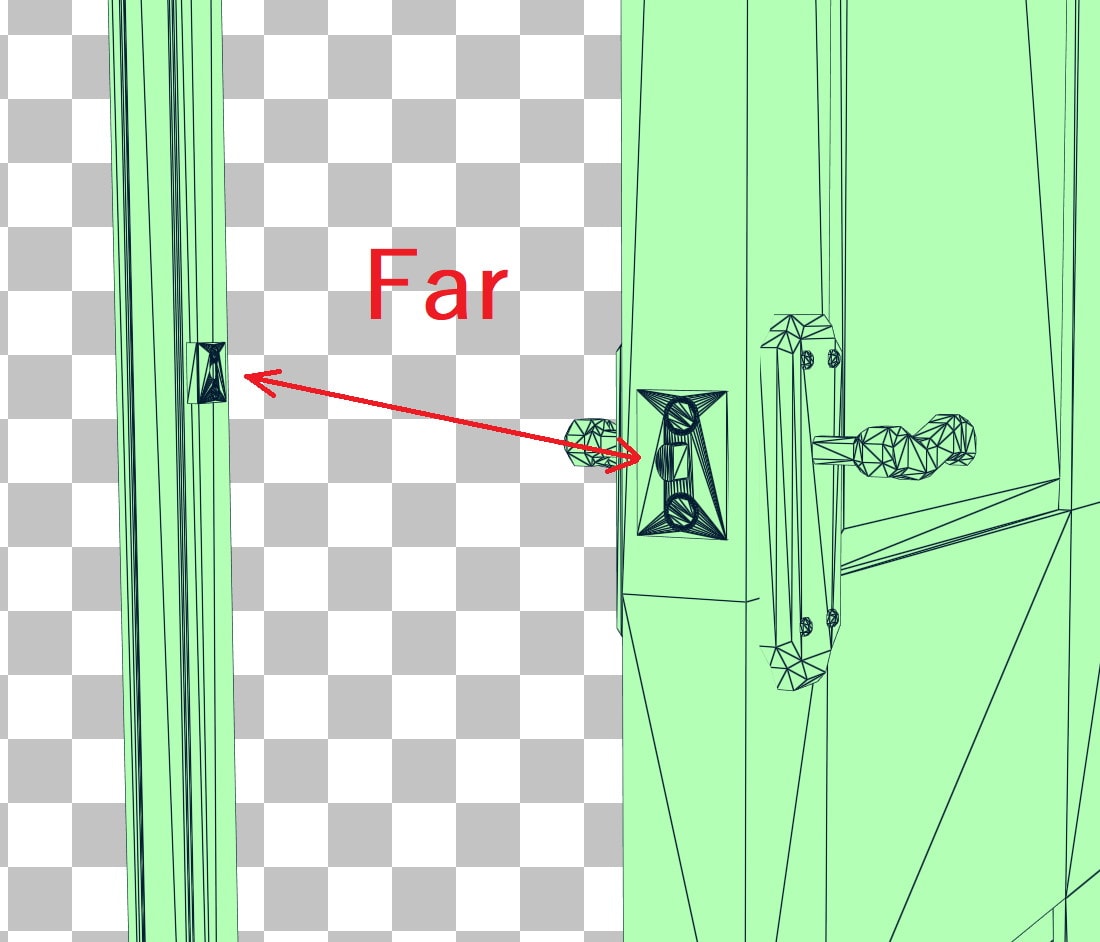
在未变形的源 BLAS 中,门闩和门锁(拧到门框上的金属件)有许多非常接近的三角形,但在变形的目标 BLAS 中,由于门已打开,这些三角形变得相距很远。起始近而结束远的三角形是使用更新模式的糟糕候选者,因为它会导致如此不优化的 BVH。
被更新的良好候选者具有这样的属性:在未变形状态下彼此靠近的三角形在变形状态下仍然彼此靠近。实际上,这将是平滑的变形,如弓的拉伸或手臂的弯曲,但不是三角形被撕裂的变形,如门的门闩或布料撕裂。
一个可能的解决方案是每隔 n 帧重建一次,并更新所有其他帧。这有助于避免 BVH 过度不优化,同时无需为每帧重建付费。
此示例未使用 RRA,但它足够重要,仍然值得提及。考虑以下反射球场景。

这是使用 16 次弹跳进行光线追踪的。在光线追踪着色器中,可以递归或迭代地实现它。
在递归情况下,raygen 着色器为每个像素投射一条射线,与球体相交的射线将触发一个 closest-hit 着色器,该着色器将依次投射另一条射线。该示例使用以下 payload:
struct Payload { vec4 color; int depth; /* Stack depth needed to terminate recursion. */};弹跳次数存储在 payload 中,以便一旦发生 16 次弹跳就可以终止递归。这是离线渲染的常见做法,但对于实时游戏来说通常过于昂贵。在 Radeon RX 6700 XT 上以 1080p 分辨率使用 RGP 进行性能分析得到了以下结果:

对于迭代实现,所有射线都从 raygen 着色器在 for 循环中进行投射。您应该通过在 DirectX 12 中将 D3D12_RAYTRACING_PIPELINE_CONFIG::MaxTraceRecursionDepth = 1,在 Vulkan® 中将 VkRayTracingPipelineCreateInfoKHR::maxPipelineRayRecursionDepth = 1 来完全禁用递归。删除 payload 中用于跟踪递归深度的 depth 成员,并将其替换为 origin、direction 和 missed 成员。
struct Payload { vec4 color; vec3 origin; /* Ray origin of the next ray to be cast. */ vec3 direction; /* Ray direction of the next ray to be cast. */ bool missed; /* Whether the ray invoked the miss shader. */};origin 和 direction 由 closest-hit 着色器设置,而不是自己投射射线。当控制权返回到 raygen 着色器时,它使用这些成员来投射另一条射线。当 miss 着色器被调用时,missed 成员会设置为 true,这样当射线终止时,raygen 着色器就可以提前跳出循环。在 GLSL 中,raygen 着色器如下所示:
primary_payload.color = vec4(0.0, 0.0, 0.0, 1.0);primary_payload.origin = camera.origin.xyz;primary_payload.direction = direction;primary_payload.missed = false;
for (int i = 0; i < 16; ++i){ traceRayEXT( TLASES[0], /* topLevel */ gl_RayFlagsNoneEXT, /* rayFlags */ 0xFF, /* cullMask */ 0, /* sbtRecordOffset */ 0, /* sbtRecordStride */ 0, /* missIndex */ primary_payload.origin, /* origin */ 0.01, /* Tmin */ primary_payload.direction, /* direction */ 1.0 / 0.0, /* Tmax */ 0 /* payload */ );
if (primary_payload.missed) { break; }}在此示例中,未调用 miss 着色器而弹跳 16 次的射线将保留其默认的黑色。使用 RGP 进行性能分析结果如下:

迭代方法仅使用了递归方法的 69.6% 的时间[1],并且 GPU 空闲百分比有所提高,这意味着 GPU 可以更自由地处理我们提交给它的其他工作。
Linux 和 Windows 的独立软件包均可下载。有关 RMV 的更详细信息,请参阅 在线文档。
下载 Radeon Developer Tool Suite (Windows®) 下载 Radeon Developer Tool Suite (Linux)[1] 在配备 AMD Ryzen 7 5800X 8 核处理器、64 GB RAM 和 Radeon RX 6700 XT 的系统上,以 1080p 分辨率和每像素一个主射线进行了测试。
将地形分割成块可以大大减少与其他实例的包围盒的重叠,并且包围体积现在也能更紧密地围绕地形。这里的权衡是,更多的实例意味着更长的 TLAS 构建时间,但对于像地形这样影响游戏中大多数帧的遍历时间的内容来说,这通常是可以接受的权衡。仍然建议使用 Radeon GPU Profiler 来分析 TLAS 的构建时间,以确保其可接受。
通过在 RRA 中切换到遍历计数器渲染模式,可以更清晰地看到射线遍历时间的优势。
© 2022 Advanced Micro Devices, Inc. 版权所有。
本文档中提供的信息仅供参考,可能包含技术性错误、遗漏和印刷错误。本文包含的信息可能会发生更改,并可能因多种原因而变得不准确,包括但不限于产品和路线图变更、组件和主板版本变更、新型号和/或产品发布、不同制造商之间的产品差异、软件变更、BIOS 刷新、固件升级等。任何计算机系统都存在安全漏洞的风险,这些风险无法完全预防或缓解。AMD 不承担更新或以其他方式更正或修改此信息的义务。但是,AMD 保留修改此信息以及不时对本文内容进行更改的权利,且 AMD 无义务通知任何人进行此类修订或更改。此信息“按原样”提供。AMD 不对本文内容的准确性、错误或遗漏作出任何陈述或保证,并且不承担任何责任。AMD 特别声明不提供任何隐含的非侵权、适销性或特定用途适用性的保证。在任何情况下,AMD 均不对因使用本文档中的任何信息而引起的任何依赖、直接、间接、特殊或其他后果性损害承担任何责任,即使 AMD 已被明确告知存在此类损害的可能性。
AMD、AMD Arrow 标志及其组合是 Advanced Micro Devices, Inc. 的商标。本出版物中使用的其他产品名称仅用于标识目的,可能是其各自公司的商标。