在本篇博文中,我们介绍了 HIP RT v2.2。此版本的主要变更是 HIP RT 现在支持多级实例。
多级实例
在某些情况下,将场景组织成两个以上的级别可能是有益的。多级实例可以显著降低内存需求。例如,代表苹果的单一几何体可以实例化为树的一部分,而树可以实例化形成一片森林(请参见下图)。我们还可以语义上组织场景:网格组织成对象,对象组织成场景。此功能对于在内存有限的情况下渲染大型场景至关重要。
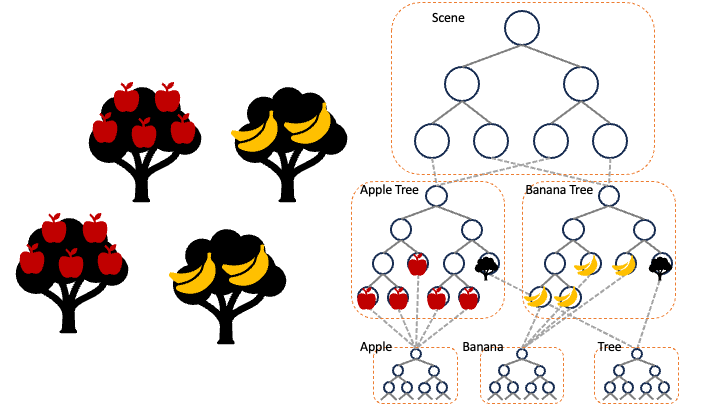
为了在 HIP RT 中支持多级实例,我们引入了一个新的结构来表示 HIP RT 中的实例,这样我们不仅可以实例化几何体,还可以实例化场景。
struct hiprtInstance{ hiprtInstanceType type; union { hiprtGeometry geometry; hiprtScene scene; };};在构建输入结构中,实例化几何体的数组被实例数组替换。
struct hiprtSceneBuildInput{ /* A device array of 'hiprtInstance' objects */ hiprtDevicePtr instances; ...};要遍历两个以上级别的层次结构,我们需要一个额外的堆栈来回溯到上层(每个额外的实例级别有一个条目)。默认的遍历对象隐式包含这个具有四个条目(最多五个级别)的实例堆栈。对于具有自定义堆栈的遍历对象,我们必须显式指定实例堆栈。
...hiprtSharedStackBuffer sharedInstanceStackBuffer{};hiprtGlobalInstanceStack instanceStack(globalInstanceStackBuffer, sharedInstanceStackBuffer);hiprtSceneTraversalClosestCustomStack<hiprtGlobalStack, hiprtGlobalInstanceStack> tr(scene, ray, stack, instanceStack);全局实例堆栈缓冲区可以通过 HIP RT API 创建。
hiprtGlobalStackBufferInput instanceStackBufferInput;instanceStackBufferInput.type = hiprtStackTypeGlobal;instanceStackBufferInput.entryType = hiprtStackEntryTypeInstance;instanceStackBufferInput.stackSize = InstanceStackSize;instanceStackBufferInput.threadCount = MaxThreads;
hiprtGlobalStackBuffer globalInstanceStackBuffer;hiprtCreateGlobalStackBuffer(context, instanceStackBufferInput, globalInstanceStackBuffer);实例堆栈管理为遍历循环带来了额外的逻辑,使用了比两级遍历更多的寄存器。由于实例堆栈类型是一个模板参数,通过传递 hiprtEmptyInstanceStack,编译器将实例化不包含多级逻辑的代码。
对于多级实例,我们不再只有单个实例 ID,而是有多个 ID(每个实例级别一个)。第一个 ID 对应顶层,第二个 ID 对应下一层,以此类推。
struct hiprtHit{ union { uint32_t instanceID = hiprtInvalidValue; uint32_t instanceIDs[hiprtMaxInstanceLevels]; }; uint32_t primID = hiprtInvalidValue; hiprtFloat2 uv; hiprtFloat3 normal; float t = -1.0f;};我们还扩展了变换查询函数以处理多个实例 ID。
hiprtFrameSRT hiprtGetObjectToWorldFrameSRT(hiprtScene scene, const uint32_t (&instanceIDs)[hiprtMaxInstanceLevels], float time = 0.0f);hiprtFrameSRT hiprtGetWorldToObjectFrameSRT(hiprtScene scene, const uint32_t (&instanceIDs)[hiprtMaxInstanceLevels], float time = 0.0f);hiprtFrameMatrix hiprtGetObjectToWorldFrameMatrix(hiprtScene scene, const uint32_t (&instanceIDs)[hiprtMaxInstanceLevels], float time = 0.0f);hiprtFrameMatrix hiprtGetWorldToObjectFrameMatrix(hiprtScene scene, const uint32_t (&instanceIDs)[hiprtMaxInstanceLevels], float time = 0.0f);有一个概念上的变化需要提及。在之前的版本中,命中了结构中返回的法线是世界空间中的。在内部,我们不得不在遍历循环后手动将此法线转换为世界空间。对于多级场景,这要复杂得多,会引入不可忽略的开销。我们还注意到,大多数用户应用程序根本不使用此法线。因此,我们决定返回 **对象空间中的法线**。如果需要,我们引入了以下函数,可用于将法线转换为世界空间:
hiprtFloat3 hiprtNormalObjectToWorld(hiprtFloat3 normal, hiprtScene scene, uint32_t instanceID, float time = 0.0f);hiprtFloat3 hiprtNormalObjectToWorld(hiprtFloat3 normal, hiprtScene scene, const uint32_t (&instanceIDs)[hiprtMaxInstanceLevels], float time = 0.0f);在 AMD GPU 上由 PBRT-v4 渲染的 Moana Island Scene
我们的团队还致力于在 AMD GPU 上运行 PBRT-v4。具体来说,它有另一个 GPU 后端,该后端已移植到 HIP 和 HIPRT。我们的 PBRT-v4 分支可以在 此处找到。多级实例是允许在 VRAM 有限的 GPU 上进行渲染的重要功能之一。下图是 Moana Island Scene 在配备 48GB VRAM 的 AMD Radeon™ PRO W7900 上渲染的,场景在内存中。该场景组织成三个级别,包含 156 个独特的图元和 310 亿个实例化图元。

另一个关键特性是 HIPRT v2.1 中引入的批量构造,它加速了大量小几何体的 BVH 构建。这对于由数百万根头发组成、每根头发都表示为单一几何体的发型模型特别有用。


其他更改
除了多级实例,我们还为几何体和场景添加了压缩功能,创建了内存占用更小的结构副本。我们还显著优化了构建速度,特别是对于快速和平衡的构建。
下载
HIP RT v2.2 的下载链接可在 HIP RT 页面上找到。PBRT HIP 移植版本可在 GPUOpen Github 上找到。
如果您正在寻找有关 HIPRT 入门指南,请查看 HIP RT SDK 教程仓库和 HIP RT 文档页面。
免责声明
Moana Island Scene
版权所有 2017-2022 Disney Enterprises, Inc. 保留所有权利。
此场景描述由 Walt Disney Pictures “按原样”提供,并免除任何明示或暗示的保证,包括但不限于适销性和特定用途适用性的暗示保证。在任何情况下,Walt Disney Pictures 均不对因使用此场景描述而产生的任何直接、间接、附带、特殊、惩戒性或后果性损害(包括但不限于采购替代商品或服务;使用、数据或利润损失;或业务中断)承担任何责任,无论其如何引起以及基于任何责任理论,无论是合同、严格责任还是侵权(包括疏忽或其他),即使已告知可能发生此类损害。