自 2016 年以来,HIP 一直作为 CUDA 的跨平台替代品可用作 GPGPU 编程语言。在编译时,HIP 在 AMD 平台上编译时使用 AMD 的实现,而在 NVIDIA® 平台上编译时,则以几乎没有开销的方式将 HIP 调用转换为 CUDA 调用。虽然这允许您使用单一 API 来编译 AMD 和 NVIDIA GPU,但这仅在编译时实现。
为 NVIDIA 和 AMD GPU 编译 HIP 会要求为单个二进制文件维护一个独立的 CUDA 和 HIP 后端,或者分别在 NVIDIA 和 AMD 平台上编译两个独立的二进制文件。这并不总是理想的,而且可能难以维护。
因此,我们将 HIP 称为 AMD 平台,将 CUDA 称为 NVIDIA 平台。
Orochi 是一个在运行时动态加载 HIP 和 CUDA® 驱动程序 API 的库。通过将应用程序中的 CUDA/HIP 调用切换到 Orochi 调用,您可以编译一个单一的可执行文件,该文件可以在 AMD 和 NVIDIA GPU 上运行。这简化了 GPU 加速应用程序的部署,并使通过单一 API 提供跨平台支持变得容易,从而消除了为每个平台维护独立后端的开销。我们选择“Orochi”这个名字是因为它来源于日本传说中的八头巨龙,这与我们库的宗旨非常契合——允许一个库在运行时拥有多个后端。
工作原理
Orochi 的工作原理是在运行时动态链接相应的 HIP/CUDA 共享库。它会在您的 PATH 中查找共享库,然后从中加载所需的符号。如果您在 AMD GPU 上使用 HIP,它将加载在 Windows® 上的 AMD 驱动程序安装包中提供的库,或者在 Linux 上的 ROCm™ 安装包中提供的库。同样,它将为 NVIDIA GPU 加载相应的 CUDA 库。目前,Windows 和 Linux 都受到支持,并且有潜力在未来添加更多后端 GPU 平台。
要使用该库,只需将 Orochi.h 和 Orochi.cpp 包含在您的项目中,然后调用 oroInitialize() 来加载基于您选择的 CUDA 或 HIP API 的符号。
在此之后,只需将所有的“hip ..” 调用和 CUDA 驱动程序“cu ..” 或 CUDA 运行时“cuda …” 调用替换为“oro …” 调用。例如,hipInit() 和 cuInit() 调用可以被替换为 oroInit()。
以下是演示其工作原理的高级示意图
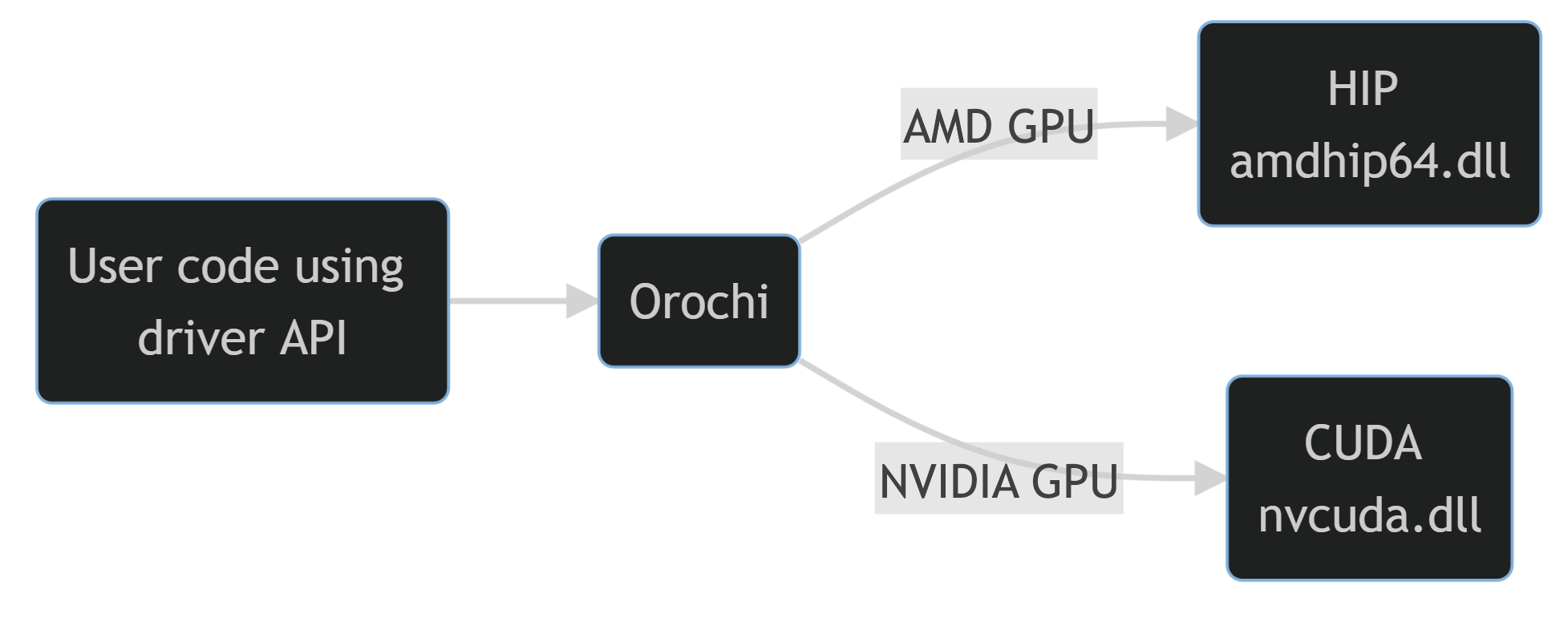
如您所见,调用 Orochi 函数(如 oroInit())的用户代码将根据在运行时提供给 Orochi 的后端,转而调用相应的 CUDA(cuInit)或 HIP(hipInit)函数。
如何使用 Orochi API
Orochi API 具有前缀:oro。如果您熟悉 CUDA 或 HIP 驱动程序 API,您将非常轻松地适应这些 API。
例如,假设我们有以下用于设备和上下文创建的 HIP 代码
#include <hip/hip_runtime.h>
hipInit( 0 );hipDevice device;hipDeviceGet( &device, 0 );hipCtx ctx;hipCtxCreate( &ctx, 0, device );使用 Orochi 重写相同的代码如下
#include <Orochi/Orochi.h>
oroInitialize( ORO_API_HIP, 0 );oroInit( 0 );oroDevice device;oroDeviceGet( &device, 0 );oroCtx ctx;oroCtxCreate( &ctx, 0, device );第二个示例将在运行时同时在 CUDA 和 HIP 上运行!
有关更详细的示例,请查看此 示例应用程序。
构建示例应用程序
Orochi 在其 GitHub 存储库中包含了一组示例应用程序。
要构建这些示例应用程序,请运行以下命令
./tools/premake5/win/premake5.exe vs2019这将生成一个包含所有三个项目的 .sln 文件。Test 示例应用程序提供了所需最少代码的示例。
所有这些示例应用程序默认在 HIP 上运行,但如果您想在 CUDA 上运行,只需在运行应用程序时添加 cuda 参数即可。
立即下载 Orochi!
您还在等什么?立即查看 Orochi!
在 GitHub 上查看 Orochi相关内容

致谢
NVIDIA 和 CUDA 是 NVIDIA Corporation 的注册商标。