AMD Radeon™ Developer Panel
RDP 提供了与 Radeon™ Adrenalin 驱动程序的通信通道。它生成 Radeon™ GPU Profiler (RGP) 使用的事件计时数据,以及 Radeon™ Memory Visualizer (RMV) 使用的内存使用情况数据。
如果您从事 GPU 开发,很可能在着色器性能的讨论中听过“占用率”这个词。您可能听说它有助于隐藏内存延迟,但不确定这具体意味着什么。如果是这样,您来对地方了!在这篇博客文章中,我们将尝试阐明这个指标究竟是什么。我们将首先讨论一些硬件架构,以了解这个指标的来源。然后,我们将解释在编译时和运行时限制占用率的因素。我们还将帮助您使用 Radeon™ GPU Profiler 等工具识别占用率受限的工作负载,并提供缓解问题的潜在方法。最后,最后一节将尝试总结本文中讨论的所有概念,并为实际问题提供实际解决方案。
然而,本文假定您对 GPU 的基本工作原理有所了解。主要而言,我们期望您了解从图形 API 的角度如何使用 GPU(绘制、分派、屏障等),并且工作负载在 GPU 上是以线程组的形式执行的。我们还期望您了解着色器使用的基本资源,如标量寄存器、向量寄存器和共享内存。
要理解占用率的概念,我们需要回顾 GPU 是如何分配工作的。从硬件架构的角度来看,我们知道 GPU 的计算能力在于其单指令多数据 (SIMD) 单元。SIMD 是您的着色器中所有计算和内存访问被处理的地方。由于 AMD RDNA™ 系列 GPU 的 SIMD 数据通路是 32 位宽的,GPU 以至少 32 个线程的组执行工作负载,我们称之为 wavefront(或 wave)。对于任何给定的总体工作负载大小,GPU 会将其分解为 wavefront,并将它们分派到可用的 SIMD。通常会有比可用 SIMD 更多的 wavefront 需要运行,这是可以的,因为每个 SIMD 可以分配多个 wavefront。从现在开始,我们将把一个 wave 分配给一个 SIMD 的行为称为“启动一个 wave”。在 RDNA1 中,每个 SIMD 有 20 个槽位可用于分配的 wavefront,而 RDNA 2 和 RDNA 3 每个 SIMD 有 16 个槽位。

虽然多个 wavefront 可以分配给单个 SIMD,但该 SIMD 一次只能执行一个 wavefront。然而,已分配的 wavefront 不必按顺序执行,也不必一次性完全执行。这意味着 GPU 可以自由地执行分配给它的任何 wavefront,并且可以逐个周期地切换它们,根据需要切换它们,就像它们在执行一样。
它通过跟踪 wavefront 的执行来了解每个着色器正在做什么,从而获得当前正在运行、正在使用和可用的资源视图,并知道下一步可以运行什么。它的主要工作是通过这样做来隐藏内存延迟,因为在着色器中访问外部内存成本很高,如果访问没有被缓存,可能需要数百个时钟周期。与其暂停正在运行的 wavefront 并等待任何内存访问(无论是否缓存),不如因为它管理着多个已分配的 wavefront,可以在此期间选择并启动另一个。
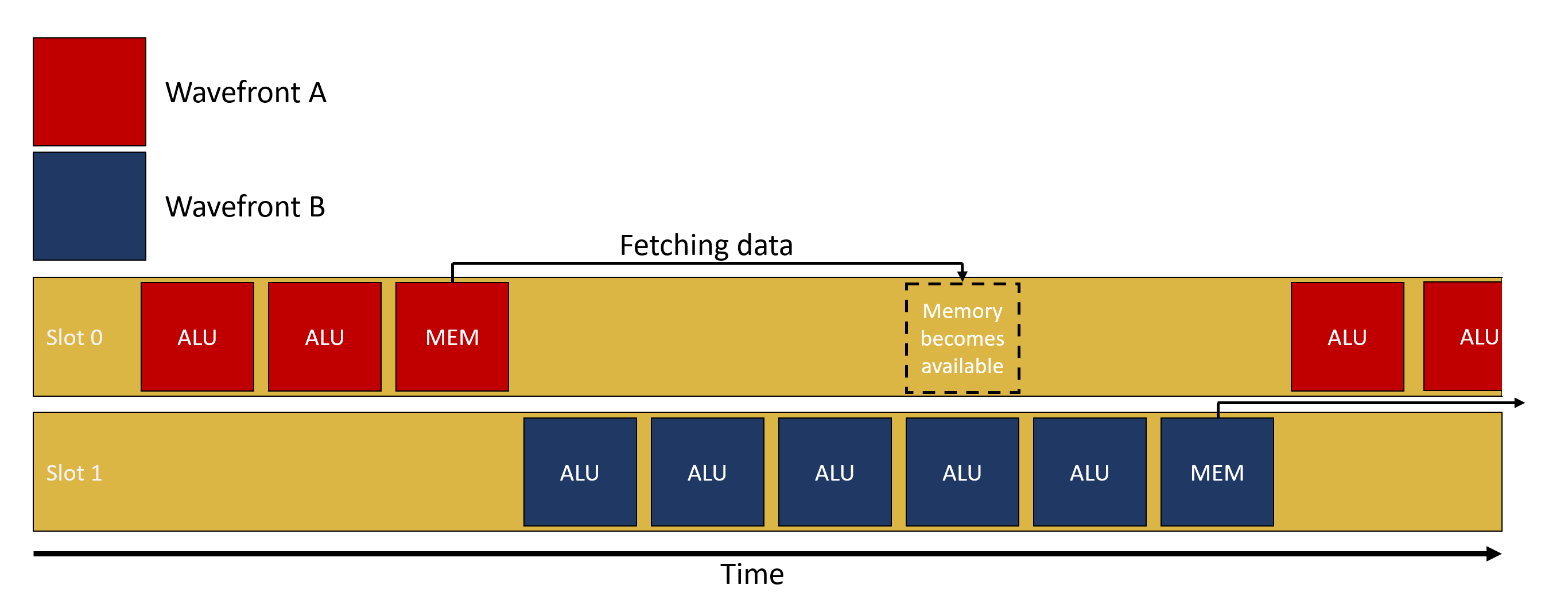
让我们举个例子,wavefront A 被 SIMD 选中,开始运行一些 ALU 计算,然后在某个时候,需要从内存中获取数据(例如,采样纹理)。根据该数据最近的访问时间,请求可能会通过整个缓存层次结构,进入内存,并最终返回。这可能需要最多几百个周期,如果没有多个 wavefront 正在进行,SIMD 将只是等待数据返回。有了多个 wavefront 正在进行,而不是等待结果返回,GPU 可以简单地切换到另一个 wavefront,比如 wavefront B,并执行它。希望 wavefront B 开始时进行一些 ALU 计算,然后再需要内存中的数据。所有这些用于运行 wavefront B 的 ALU 计算的时钟周期都隐藏了获取 wavefront A 数据的延迟。如果正在进行的 wavefront 中有足够的 wavefront 可以执行 ALU 操作,那么 SIMD 就可以永远不处于空闲状态。
隐藏延迟影响的一种可视化方法是使用 Radeon GPU Profiler (RGP) 并检查单个绘制或分派的指令时序。在下面的图像中,我们正在查看 GPU 执行的指令。在延迟列中,我们可以看到每条指令执行花费了多少个时钟周期。如果我们查看指令 435,我们可以看到它总共花费了约 850 万个时钟周期。因为这是一条内存等待指令,我们希望实际停滞等待的时间尽可能短,而是通过切换到另一个 wavefront 来隐藏延迟。这正是颜色编码向我们展示的内容。条形的第一个部分,其中大约 80% 是绿色,意味着等待的总时间中约 80% 实际上是通过执行来自不同 wavefront 的向量 ALU 操作来隐藏的。我们还可以看到,在绿色条形的开头有一些黄色阴影线,表示标量 ALU 操作也与这些向量 ALU 操作并行执行。

顺便说一句,此选项卡还以直方图的形式显示了所分析 wavefront 的长度分布。这种可视化有助于您认识到不同 wavefront 的执行长度在单个工作负载中可能存在很大差异。还可以通过使用其下方的控件选择直方图的某个区域来隔离某些 wavefront 进行指令时序分析。

只有当 GPU 能够快速切换正在运行的 wavefront 时,这种 wavefront 切换机制才能起作用;切换的开销必须低于 SIMD 可能花费的空闲时间。为了快速切换,wavefront 所需的所有资源始终可用。这样,在切换到不同的 wavefront 时,GPU 可以立即访问运行它所需的资源。
占用率是已分配 wavefront 与最大可用槽位的比率。在 RDNA2 及更高版本中,对于单个 SIMD,这意味着已分配 wavefront 的数量除以 16。举个例子,如果一个 SIMD 有 4 个 wavefront 正在进行,占用率就是 4 / 16 = 25%。占用率的另一种解释是 SIMD 隐藏延迟的能力。如果占用率为 1/16,则意味着如果 wavefront 需要等待某些内容,延迟就无法隐藏,因为没有其他 wavefront 分配给该 SIMD。在另一端,如果 SIMD 的占用率为 16/16,则它处于隐藏延迟的有利位置。
在深入研究占用率之前,现在可能是时候了解一下隐藏延迟(因此也包括占用率)何时与性能相关。由于增加占用率意味着增加 GPU 的延迟隐藏能力,因此不受延迟限制的工作负载不会从增加的占用率中受益。例如,ALU 密集型工作负载就是这种情况。如果 SIMD 已经以 100% 的利用率运行并且不花费任何时间等待,那么我们就无需增加每个 SIMD 的可用 wave 数量。
反过来说,唯一 *可能* 从增加占用率中受益的工作负载是那些受延迟限制的工作负载。大多数工作负载将遵循以下模式:加载数据,对数据进行一些 ALU 工作,存储数据。因此,一个可以通过添加更多 wave 来受益的工作负载将是 wave 的数量乘以运行 ALU 工作所需的时间低于加载数据所需的时间。随着更多 wave 的进行,我们增加了可用于隐藏加载数据延迟的总 ALU 工作量。
话虽如此,占用率并非万能药,也可能降低性能。在内存密集型场景中,增加占用率可能没有帮助,特别是如果负载和存储操作之间只有很少的工作。如果着色器已经受内存限制,增加占用率将导致更多的缓存抖动,并且无助于隐藏延迟。一如既往,这是一个平衡问题。
到目前为止,我们已经将占用率描述为内部调度机制的结果,所以让我们来谈谈可能影响它的具体组件。如前所述,为了能够快速地在 wavefront 之间切换,SIMD 会预先保留运行所有已分配 wavefront 所需的所有资源。换句话说,只有当有足够的资源可用时,GPU 才能将 wavefront 分配给 SIMD。通常,这些资源是向量通用寄存器(VGPR)、标量通用寄存器(SGPR)和“groupshared”内存,我们称之为本地数据共享(LDS)。然而,在 RDNA GPU 上,每个 wavefront 都分配了固定数量的 SGPR,并且总是有足够的 SGPR 来填充 16 个槽位。
着色器在 SIMD 上运行时所需的资源量在编译时进行评估。着色器编译器堆栈会将高级代码(HLSL、GLSL 等)编译成 GPU 指令,并评估着色器在 SIMD 上运行时所需的 GPR 和 LDS 的数量。在 RDNA GPU 上,它还将决定着色器应该以本地 wave32 模式运行,还是以 wave64 模式运行,其中 wavefront 包含 64 个线程。正如您可能猜到的,wave64 着色器在 2 个周期内运行每个 wavefront,并且资源需求更高。
对于计算着色器,线程组大小是理论占用率的另一个因素。编写计算着色器时,用户必须定义将作为一组执行的线程数。这一点很重要,因为单个线程组的所有线程可以通过一些称为本地数据共享(LDS)的共享内存共享数据。在基于 RDNA 的 GPU 上,LDS 是工作组处理器(WGP)的一部分。这意味着单个线程组的所有线程都必须在同一个 WGP 上执行,否则它们将无法访问相同的 groupshared 内存。注意:此限制仅适用于计算着色器。通常,分配给单个 SIMD 的并非所有 wavefront 都需要属于同一个绘制或分派。
利用所有这些约束,您可以计算出着色器在给定 GPU 上的理论占用率,并知道哪个资源可能限制了它,但我们在 Radeon GPU Profiler (RGP) 的 Pipeline 选项卡中对此进行了简化,如下图所示。它显示了当前的理论占用率、限制因素以及需要减少多少才能将占用率提高 1。如果您愿意手动进行计算,Pipeline 选项卡仍然会显示着色器所需的资源数量、它正在运行的 wave 模式以及它是否为计算着色器。
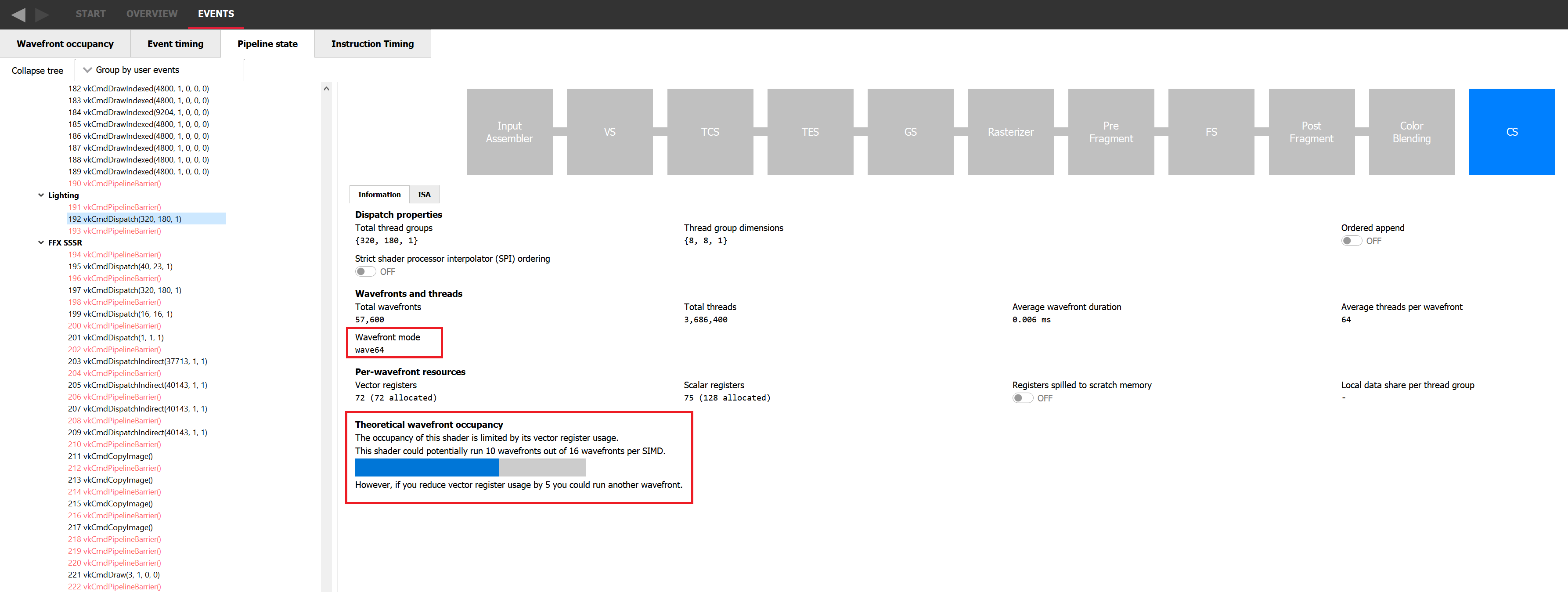
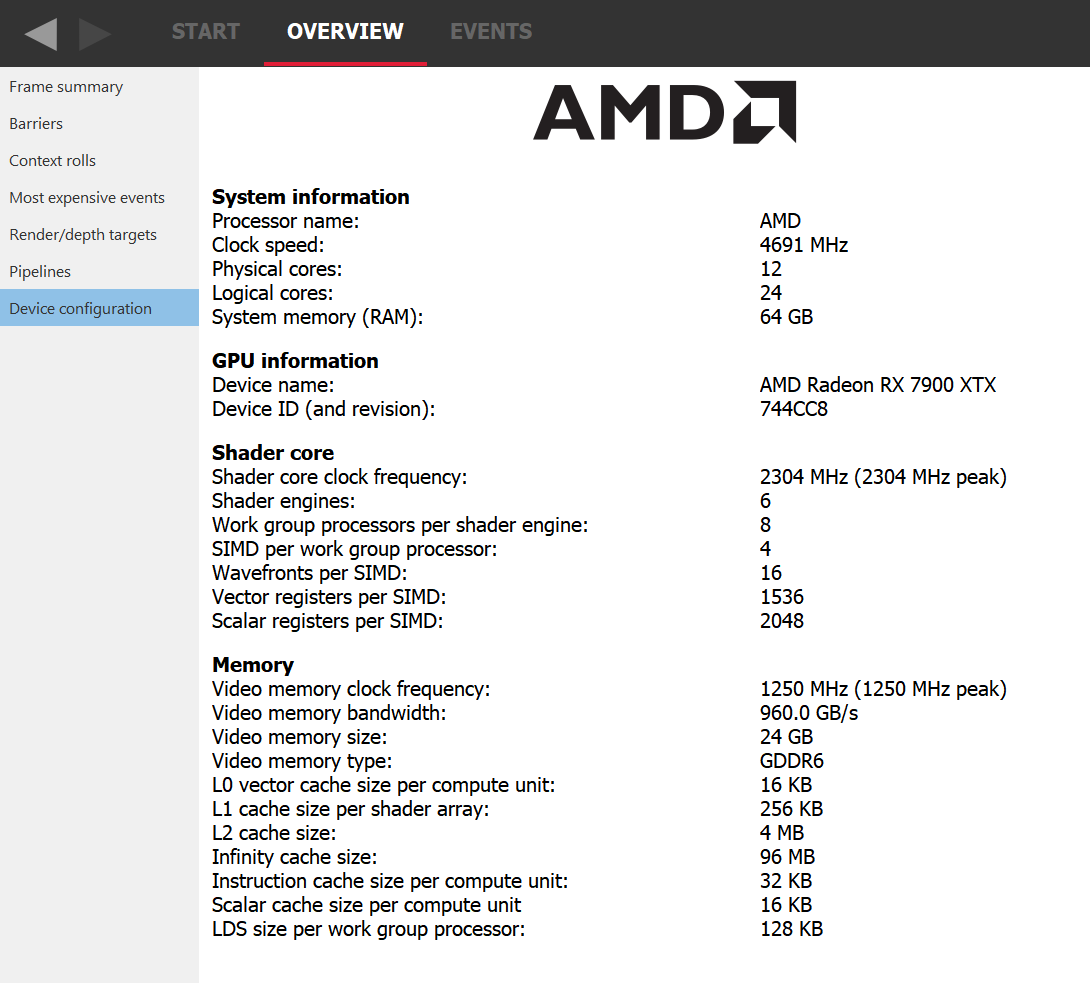
例如,我们考虑一个理论占用率受 VGPR 压力限制的示例。例如,让我们考虑一个需要 120 个 VGPR 且不受 LDS 限制的着色器。如果我们转到 RGP 的 Device Configuration 选项卡,我们可以看到对于 AMD Radeon RX 7900 XTX GPU,每个 SIMD 有 1536 个 VGPR 可用。这意味着在 wave32 模式下,由于 1536 / 120 = 12.8,我们可以将 12 个 wavefront 分配给一个 SIMD。这也意味着理论上,对于只需要 118 个 VGPR 的着色器,可以分配 13 个 wavefront。实际上,VGPR 的分配粒度大于 1,因此该着色器需要请求少于 118 个 VGPR 才能分配 13 次。块的大小取决于架构和 wave 模式,但 RGP 会准确告诉您需要节省多少 VGPR 才能分配一个新的 wave。在 wave64 模式下,我们需要节省更多的 VGPR 才能分配一个额外的 wavefront。
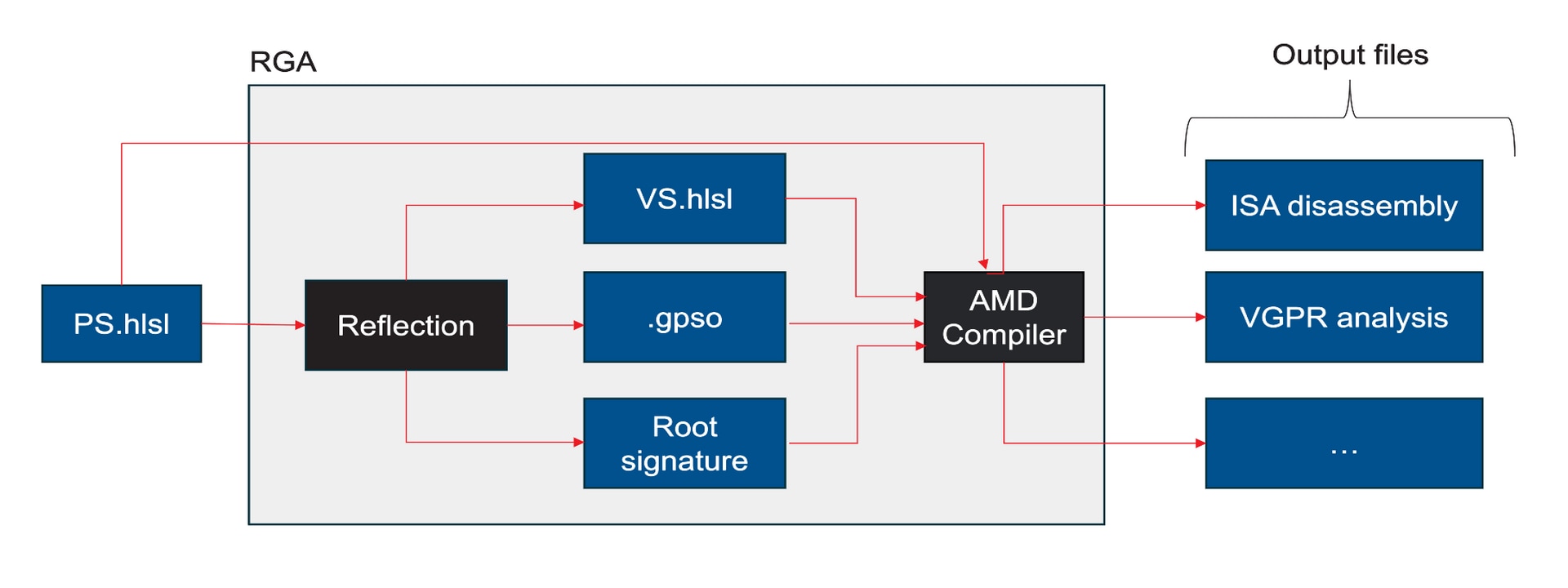
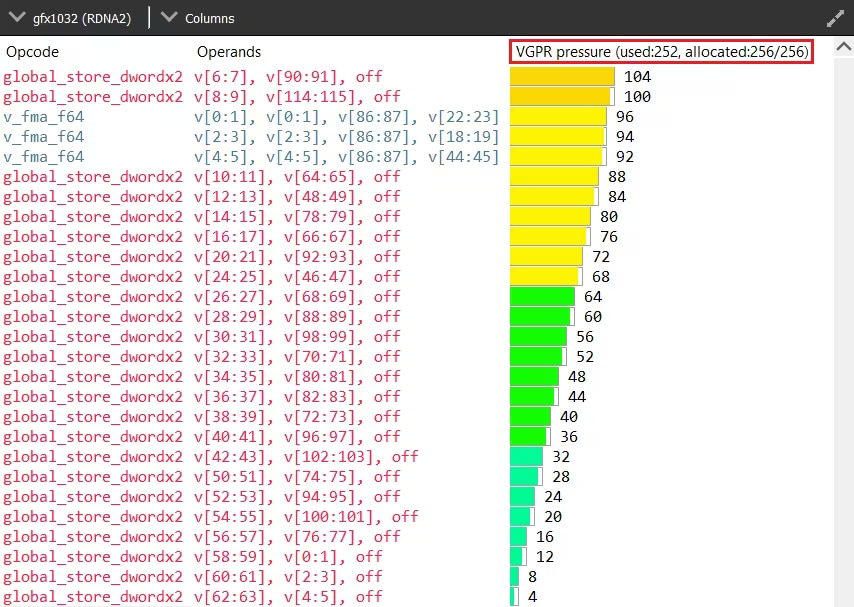
没有合适的工具,理解寄存器压力从何而来并非易事。幸运的是,Radeon GPU Analyser (RGA) 可以提供帮助。RGA 允许您从高级源代码编译着色器到 AMD ISA,并提供对由此产生的资源需求的洞察。例如,它可以显示程序在 ISA 级别上每个指令有多少 VGPR 是活动的。
这种可视化非常有助于识别特定着色器中潜在的 VGPR 使用高峰。由于 GPU 会为着色器中的最坏情况需求分配资源,因此在着色器的一个分支中的单个峰值可能会导致整个着色器需要大量的 VGPR,即使该分支实际上从未被采用。有关如何使用 RGA 的更多信息,请查阅专用的 GPUOpen RGA 页面 以及我们关于 Live VGPR Analysis 的指南:使用 RGA 进行实时 VGPR 分析 和 使用 RGA 可视化 VGPR 压力。
理论占用率或最大可实现占用率只是我们现在称之为测量占用率的上限。RGP 是探索测量占用率的绝佳工具,我们将在下一节中使用其专用的 wavefront 占用率选项卡。在此视图中,顶部的图表绘制了测量占用率,底部的条形图显示了不同的绘制和计算分派在 GPU 上的重叠情况。从现在开始,我们将使用“work item”(工作项)来指代两者。要获取有关特定工作项的更多信息,只需从底部的条形图选择它,然后在右侧查看详细信息面板。
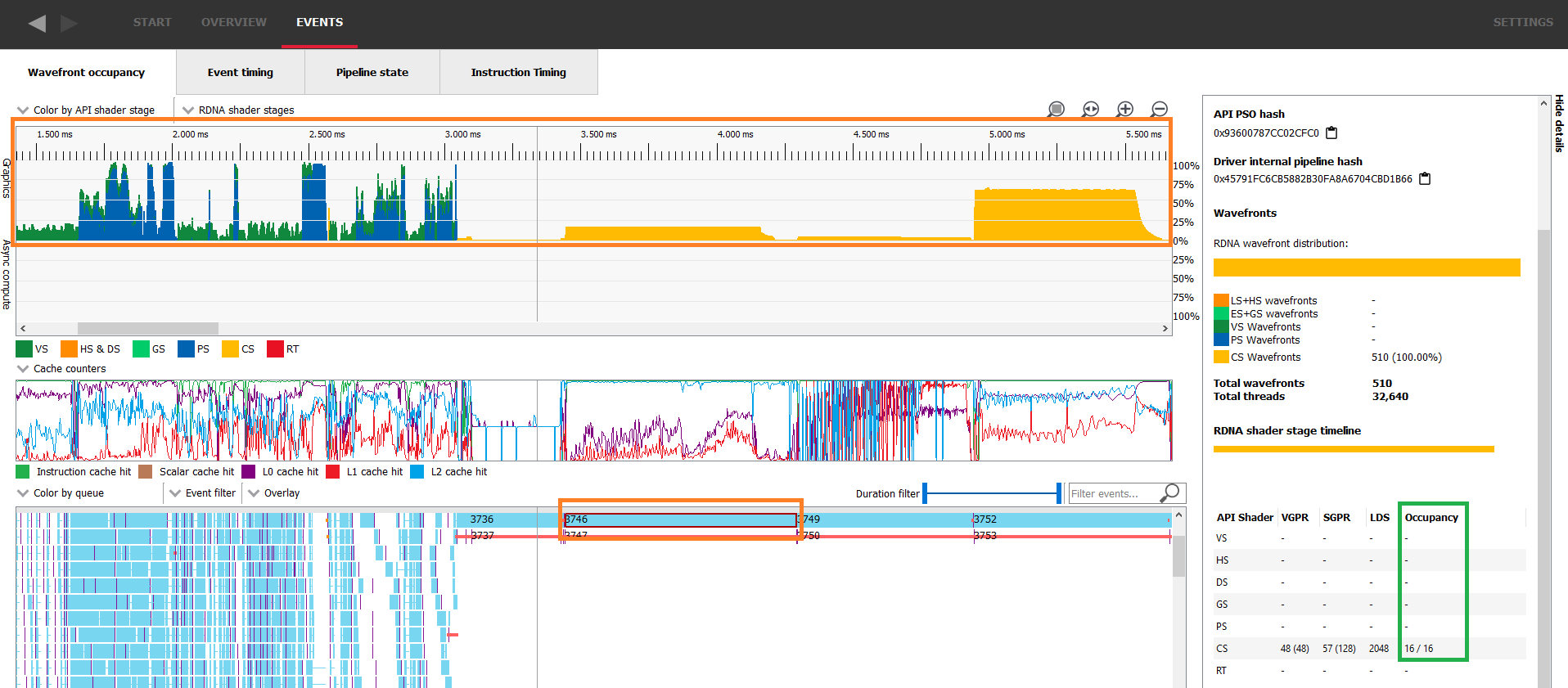
详细信息面板的占用率列显示了该特定工作项的理论占用率。在此捕获中,我们可以立即看到测量占用率不是恒定的,也不一定匹配理论占用率。在下面的图像中,测量占用率图位于蓝色矩形内,选定的工作项位于橙色矩形内,绿色矩形显示了详细信息面板中要查看理论占用率的位置。
测量占用率无法达到理论占用率主要有两个原因:要么工作量不足以填满所有槽位,要么 GPU 无法足够快地启动这些 wavefront。
AMD Radeon™ RX 7900 XTX 拥有 6 个着色器引擎 (SE),每个 SE 有 8 个工作组处理器 (WGP),每个 WGP 有 4 个 SIMD。这为您提供了总共 6 * 8 * 4 = 192 个 SIMD。因此,任何不足 192 * 16 = 3072 个 wavefront 的工作负载(请记住每个 SIMD 有 16 个 wavefront 槽位)都永远无法达到 100% 的占用率,即使 wavefront 从未受资源限制。这种情况通常非常罕见且易于检测。
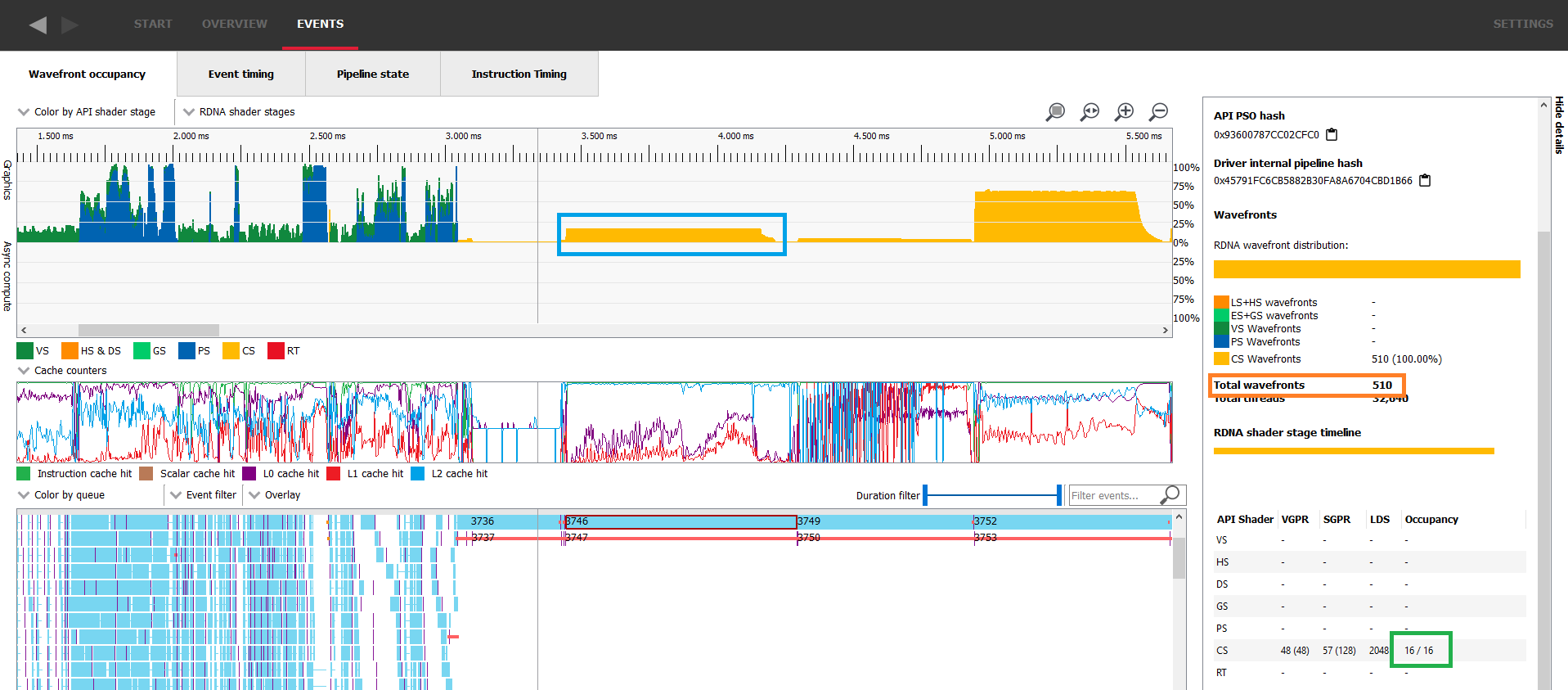
这种小型工作负载在 GPU 上的执行速度非常快,详细信息面板将显示总共分配了多少个 wavefront。在下面的图像中,选定工作项的理论占用率为 16/16(如详细信息面板中的绿色所示),但测量占用率甚至没有达到 4/16(如蓝色所示)。这是因为详细信息面板中橙色显示的只有 510 个 wavefront 正在进行。
另一个 GPU 中 wavefront 不足的经典场景是工作负载执行的末尾,此时大部分工作已经完成,只有少数剩余的 wavefront 需要执行。在下面的图像中,我们可以看到蓝色矩形中的分派 188 在 1.05 毫秒之前开始下降,并且在整个执行期间都没有保持其完整的占用率。一旦分派 188 的所有线程都已退休,分派 190 就会开始。这种情况发生是因为事件 189 是一个屏障,阻止了这两个分派重叠。
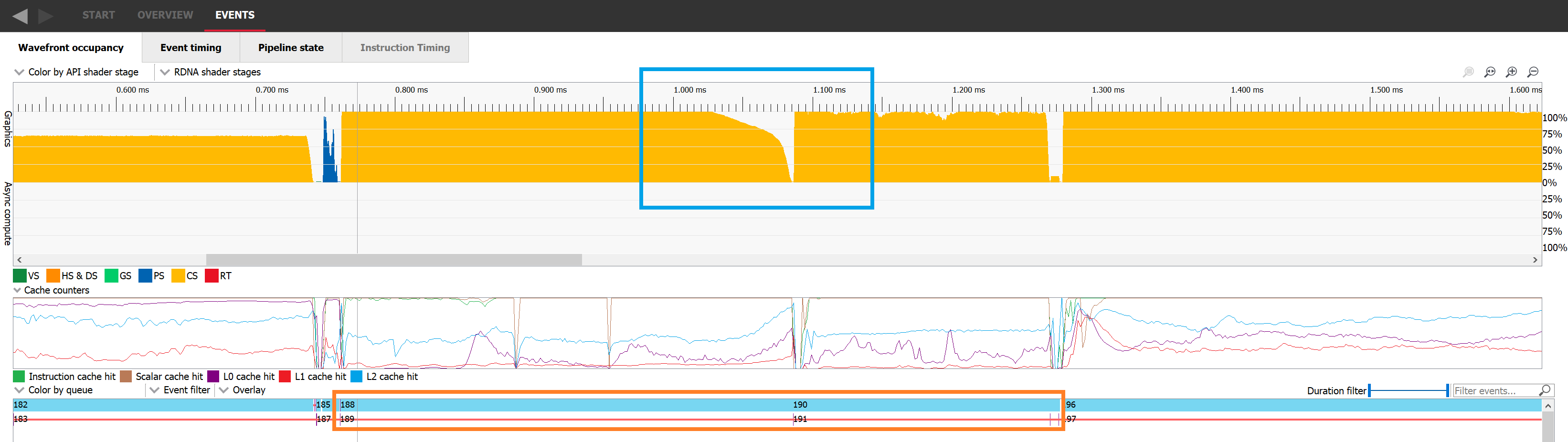
如果我们切换到 Event Timing 选项卡,我们可以按顺序查看事件。分派 188 被发出,然后发出资源屏障,这阻止了与下一个工作项重叠,最后发出分派 190。

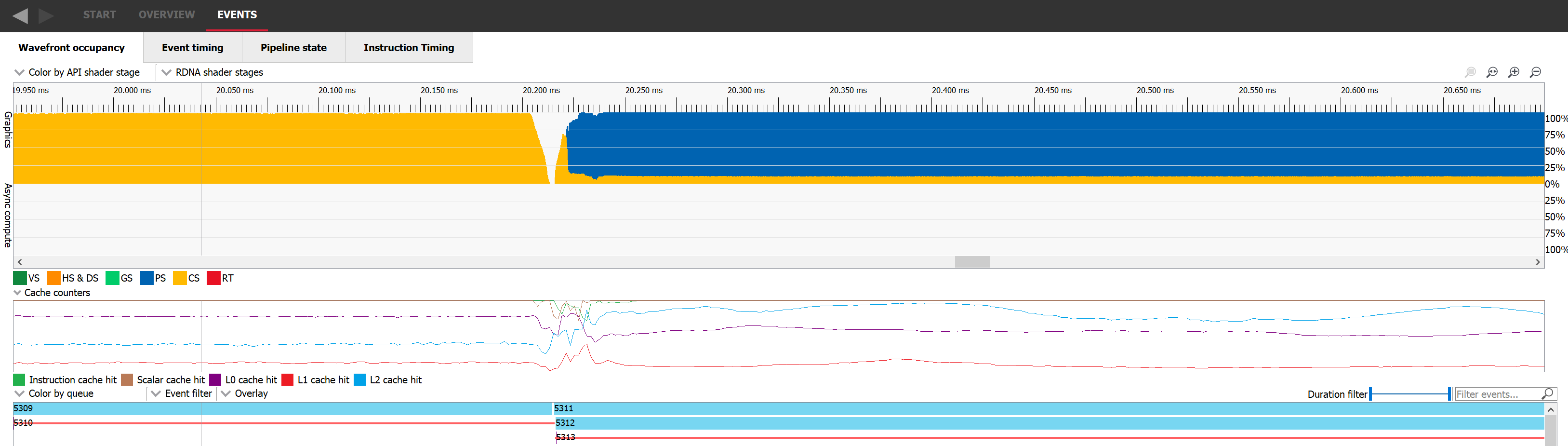
提高这两种场景占用率的方法是找到重叠工作的方法。如果我们能够使两个占用率受限的工作负载并行执行,那么 GPU 的整体占用率很可能会提高。要实现这一点,我们需要选择两个彼此之间没有任何依赖关系的工作负载,并将它们发出到命令列表中,中间没有任何屏障。在下面的图片中,我们可以看到分派 5311(占用率以黄色表示)与绘制 5312(占用率以蓝色表示)很好地重叠。遗憾的是,这并非总是可能的。
弄清楚何时由于 GPU 无法足够快地启动波形(waves)而导致占用率受限,这有点棘手。最明显的情况是两个工作负载之间存在依赖关系。GPU 需要先完成第一个工作负载的卸载,然后才能开始第二个工作负载。一旦第二个工作负载从一个空 GPU 开始,测得的占用率会随着 GPU 加载工作而上升。这通常只会持续很短的时间,是不可避免的。在这种情况下,唯一的解决方案是移除依赖关系,使两个工作负载重叠,就像我们在上一段中所描述的那样。
然而,在某些工作负载执行过程中,如果该工作负载的波形执行速度快于 GPU 启动它们的速度,也可能发生同样的情况。这不是理想情况,占用率将受限于 GPU 启动波形的速度。启动一个新的波形比简单地将其分配给一个 SIMD 以便运行更复杂。需要进行一些工作来设置各种寄存器的内容,以便执行可以开始,而每种着色器类型都有特定的要求。
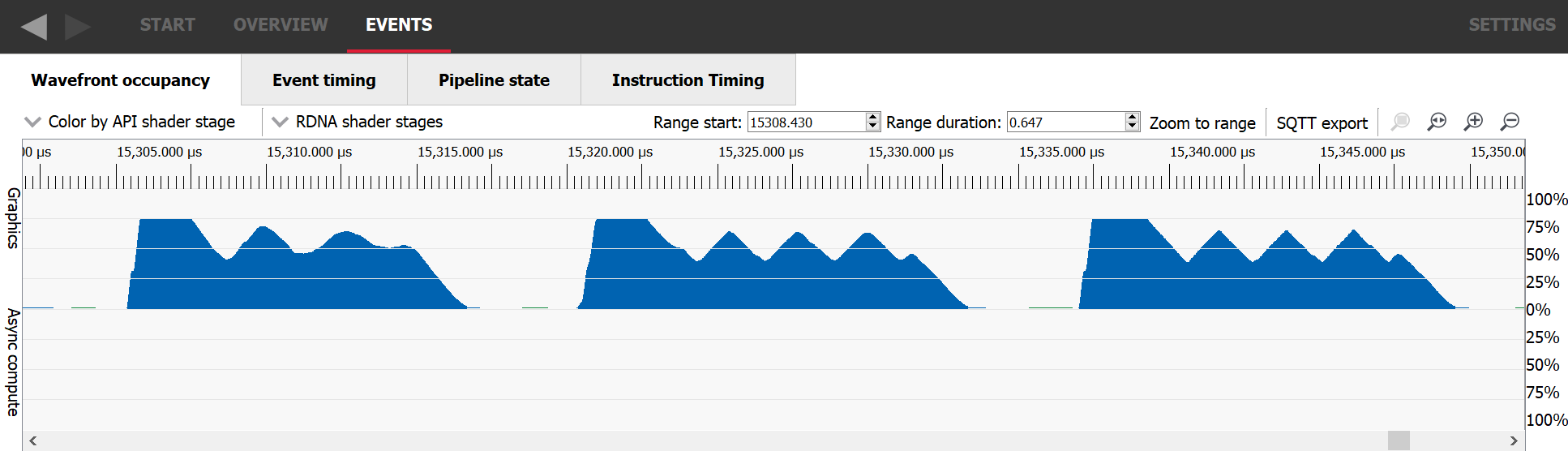
在 RGP 捕获中检测启动速率受限占用率的最简单方法是寻找一个启动时占用率非常高,然后下降并且再也无法达到峰值占用率的工作负载。它通常会振荡,然后稳定到其平均值。在这些工作负载开始时,GPU 会启动许多波形,但随后会因等待某些初始数据可用而停滞。一旦执行波形所需的数据至少部分缓存,它们执行的速度就会比 GPU 启动更多波形的速度快,导致占用率下降,依此类推。
对于像素着色器,如果之前描述的任何情况似乎都不适用于您的工作负载,那么 GPU 可能正在耗尽 LDS 来存储从 VS 发送到 PS 的插值器。不幸的是,PS 所需的 LDS 量无法在编译时进行评估。它取决于单个波形(wavefront)处理的独立图元的数量,该数量在运行时进行评估。在这种情况下,应该调查正在渲染的几何图形的类型。如果绘制了大量微小三角形,每个波形最终都会处理多个图元。缓解此问题的一种方法是调整游戏级别的细节(LOD)系统。
在前面的段落中,我们试图让大家了解占用率限制器是什么以及为什么存在。然而,在实际调查占用率时,最好有一个工具来为您识别帧的哪些部分受占用率限制以及由哪个限制资源限制。这正是 Microsoft® PIX 的 AMD 插件所暴露的“WaveOccupancyLimiters”所提供的。您可以在概览选项卡的底部直接请求这些。
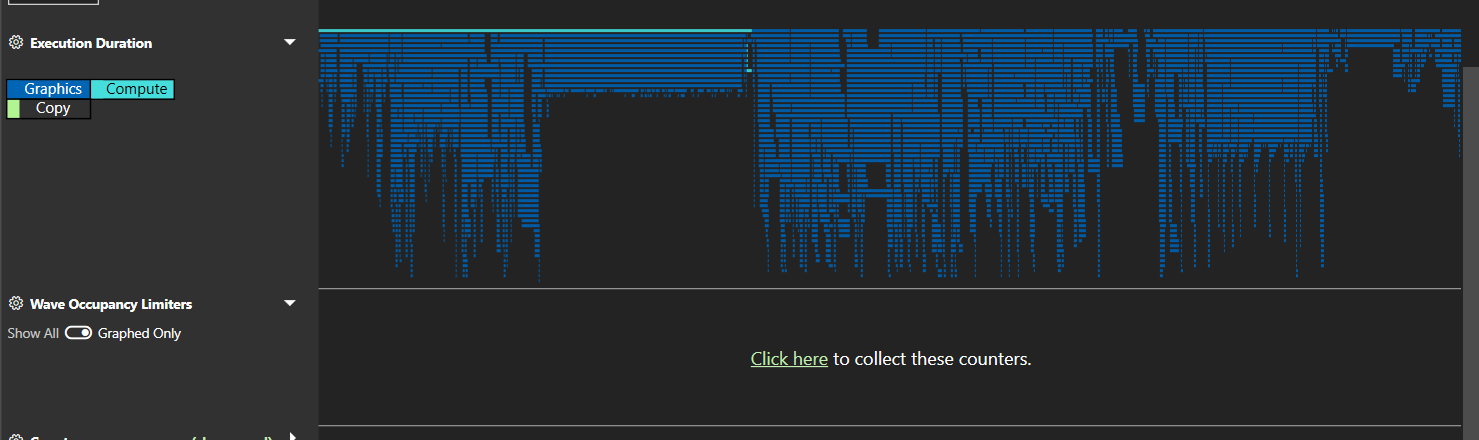
一旦捕获了计数器,PIX 就会像其他计数器一样将它们绘制成时间图。

如果我们查看计数器列表,我们可以看到,尽管它们是按波形类型专门化的,但大多数可以分为 4 类。
前三个我们之前已经见过。为了在 SIMD 上启动波形,调度器需要提前预留它们可能需要的所有执行资源,包括 VGPR 和 LDS。对于计算着色器,必须有足够的这些资源供整个线程组使用。因为您定义了线程组的大小,所以您可以影响这个资源需求。
至于屏障,GPU 可以跟踪每个 SIMD 对多达 16 个正在进行的屏障。提醒一下,每个 SIMD 可以分配 16 个波形,总共是每个 SIMD 对 32 个波形。运行计算着色器时,运行整个线程组所需的资源将被一起分配和释放,这意味着 GPU 需要能够在线程组执行结束时同步构成该线程组的波形。这种同步需要一个屏障,因此在最坏的情况下,有可能用完所有屏障资源。
只有当线程组由至少 2 个波形组成时,才需要屏障。因此,我们最多可以有 32 / 2 = 16 个需要屏障的线程组。这非常完美,因为我们有 16 个屏障资源。但是,如果一个波形完成,它会释放 SIMD 上的一个插槽,但它不能释放其所需的执行资源,因为它必须等待其线程组的第二个波形也完成。由于现在有一个可用的波形插槽但无法填充,因此我们受占用率限制。在这种情况下,我们受线程组大小限制,因为我们需要 2 个波形插槽来分配一个单独的线程组。
现在,如果该线程组的第二个波形完成,我们就不再受占用率限制了。这个线程组所需的插槽、资源和屏障将被释放。但是,如果来自不同线程组的波形完成,我们现在有 2 个可用的插槽,可能足够运行另一个线程组的资源,但没有可用的屏障来启动它。在这种情况下,我们受屏障资源限制,占用率受到限制。这是一个非常特殊的情况,在实践中会非常罕见。
由于 PIX 将这些计数器绘制成时间图并以百分比显示计数器的值,因此很自然地会认为百分比越低,着色器受占用率限制的程度就越小。可悲的是,事实并非如此。这些计数器主要应作为二进制指标来确定哪个资源限制了占用率。要理解为什么会这样,我们需要了解它们是如何收集的。每时钟周期,如果存在可用的波形插槽,调度器将尝试启动新的波形。如果不可能,相关的占用率限制器计数器将被递增。只要有可用的波形插槽且 GPU 无法调度新波形,这种情况每时钟周期都会发生。在工作负载结束时,我们将这些计数器除以工作负载总时钟数,以确定该工作负载中有多少百分比实际上受这些限制器的约束。
需要理解的重要一点是,无论百分比是多少,它都不能说明任何关于占用率的信息。运行在特定占用率下的工作负载是否受到限制,对其隐藏延迟的能力没有影响。所有重要的是是否有足够的占用率来隐藏任何延迟。限制器百分比将根据波形的执行时间而变化。如果波形是长运行的,调度器可能不会经常找到新的波形来启动,因此会为该限制器计数许多时钟周期。另一方面,如果波形非常短,通常有新的插槽可用,因此 GPU 较少失败启动新波形。限制器百分比可以让我们对 GPU 启动波形的方式有所了解,但它不会提供关于占用率的额外信息。如果其中一个计数器大于 0,那么它就是一个限制器,仅此而已。
在我们继续讨论了解 GPU 占用率的实际意义之前,值得了解一下占用率最重要的一些实际方面,您在分析和优化着色器性能时可能会遇到。我们已经讨论了哪些 intra-WGP 共享资源会限制占用率,这可以让我们直观地认为,着色器程序员的工作是通过限制这些共享资源的使用来最大化占用率。
然而,在 GPU 的其余部分,还有一些共享的——而且通常稀缺的!——资源,您的着色器在内存方面会大量使用。每次外部内存访问都必须通过 GPU 的缓存层次结构,希望在途中被缓存服务,从而节省宝贵的内存带宽并减少执行延迟。在任何现代 GPU 中,每次访问都需要通过这个层次结构的多个级别。
由于来自同一着色器程序的波形倾向于一起运行,大致在同一时间执行大致相同的事情,因此每当它们访问内存时,它们就会倾向于成组访问。根据执行的内存访问形状以及从着色器写入或读取的数据量,有可能使层次结构中的缓存失效。
因此,占用率的增加可能意味着性能的下降,因为在充分利用 GPU 执行资源的同时,还需要平衡其服务内存请求和在缓存层次结构中良好吸收它们的能力。作为 GPU 程序员,这是一个很难影响和平衡的问题,尤其是在 PC 上,问题空间涵盖了许多不同供应商的 GPU,并且着色器编译器栈为编译您的着色器所做的选择可能会随着驱动程序更新而改变。
在最后一部分,我们希望将本文中试图传达的所有知识集中在一个更易于解析的格式中,以便再次查阅本文。我们将首先回答一些关于占用率的经典问题,然后提供一个小型指南,说明如何解决给定工作负载的占用率改进问题。
问:更好的占用率是否意味着更好的性能?
答:不,只有当 GPU 能够利用占用率来隐藏延迟,同时平衡缓存层次结构的可用性能时,它才会提高性能。
问:我什么时候应该关心占用率?
答:主要是在工作负载以某种方式对内存性能敏感时。
问:最大占用率是否意味着我的着色器的所有内存访问延迟都被隐藏了?
答:不,这只意味着 GPU 最大化了隐藏它的能力。
问:较低的理论占用率是否总是对性能不利?
答:就像最大占用率会损害性能一样,较低的占用率也可以帮助性能,但务必进行性能分析,并始终检查低占用率着色器是否将寄存器溢出到内存(参见下面的最后一段)。
当我们描述理论占用率时,我们首先解释了它与波形执行所需的资源量之间的关系。我们还提到,如果资源不足,则无法启动波形,但就 VGPR 使用而言,这并不完全正确:着色器编译器有一个机制,可以“溢出”寄存器到内存。
这意味着,它不是要求着色器使用大量寄存器,而是可以决定减少该数量,并将其中一些放在内存中。访问存储在内存中的数据比访问存储在物理寄存器中的数据具有更大的延迟,这通常会对性能产生巨大影响。虽然这严格来说与占用率无关,但当着色器具有较低的理论占用率且受 GPR 压力限制时,值得检查它是否正在溢出。RGP 的管线选项卡将告诉您,对于给定的工作项,着色器编译器是否不得不将寄存器溢出到内存。

我要感谢 Pierre-Yves Boers、Adam Sawicki、Rys Sommefeldt、Gareth Thomas 和 Sébastien Vince 审阅了本文并提供了宝贵的反馈。