
将《底特律:变人》从 PlayStation® 4 移植到 PC – 第二部分
Quantic Dream 和 AMD 联合发布的系列文章的第二部分,将重点介绍 PC 和 AMD 显卡上的非统一资源索引。

这是一个三部分系列,由 Quantic Dream 的 3D 引擎总监 Ronan Marchalot、3D 引擎资深开发人员 Nicolas Vizerie 和 Jonathan Siret,以及 AMD 的开发者技术工程师 Lou Kramer 联合撰写。
博客中包含的信息代表 AMD 或第三方作者在发布日期当时的观点。博客文章包含作者的个人意见,可能不代表 AMD 的立场、策略或观点。AMD 和/或第三方作者无义务更新任何前瞻性内容。GD-84
大家好,
本系列博客讨论了游戏《底特律:变人》从 PlayStation® 4 到 PC 的移植过程。该系列分三部分发布,现在第一部分的 末尾处 提供了所有三部分的链接。
《底特律:变人》于 2018 年 5 月在 PlayStation® 4 上发布。我们于 2018 年 7 月开始着手 PC 版本的工作,并于 2019 年 12 月发布。这是一款冒险游戏,拥有三个可玩角色和许多不同的故事情节。它具有非常强大的视觉效果,大部分技术都是内部开发的。
3D 引擎包含一些很棒的功能:

底特律:变人
该游戏最初是专为 PlayStation® 4 设计的 3D 引擎,当时我们并未考虑支持其他平台。因此,PC 版本对我们来说是一个巨大的挑战。
我们的引擎已经有一个 OpenGL® 版本,用于我们的工具。
我们觉得直接用 OpenGL® 发布游戏并不可靠。
由于我们大量使用无绑定资源,因此将游戏移植到 DirectX® 11 是不可行的。资源槽位不够用,而且如果需要重组着色器以使用更少的资源,要达到体面的性能将非常困难。
选择在 DirectX® 12 和 Vulkan® 之间进行,两者都提供了非常相似的功能集。Vulkan® 稍后将支持 Linux 和手机,而 DirectX® 12 将支持 Microsoft® Xbox。我们知道最终需要支持这两个 API,但对于这次移植,只专注于一个 API 更为明智。
Vulkan® 仍然支持 Windows® 7 和 Windows® 8。由于我们希望尽可能多的玩家能够玩到《底特律:变人》,这使得它比 DirectX® 12 更有吸引力。然而,这次移植花费了一年时间,随着 Windows® 10 的广泛使用,这个论点已经过时了!
OpenGL® 和 DirectX® 的早期版本提供了非常简单的 GPU 驱动模型。这些 API 易于理解,非常适合学习目的。它们依赖于驱动程序执行许多隐藏在开发者视线之外的工作。因此,要优化一个功能齐全的 3D 引擎可能非常困难。
相反,PlayStation® 4 的 API 非常轻量级,非常接近硬件。
Vulkan® 介于两者之间。仍然存在抽象层,因为它运行在不同的 GPU 上,但我们拥有更多的控制权。例如,我们负责处理内存或实现着色器缓存。由于驱动程序的工作量减少了,我们的工作量就增加了!然而,从 PlayStation® 平台过来的我们,对控制一切更为习惯。
PlayStation® 4 的 CPU 是 AMD Jaguar 8 核。它显然比最近发布的一些 PC 硬件慢;但 PlayStation® 4 具有一些主要优势,例如可以非常快速地访问硬件。我们发现 PlayStation® 4 的图形 API 比所有 PC API 都高效得多。它非常直接,开销非常低。这意味着我们可以每帧推送大量的绘制调用。我们知道,大量绘制调用可能会成为低端 PC 的问题。
另一个主要优势是,所有着色器都可以离线编译到 PlayStation® 4 上,这意味着着色器加载几乎是即时的。在 PC 上,驱动程序需要在加载时编译着色器:由于需要支持的 GPU 和驱动程序的配置非常广泛,因此这不可能是一个离线过程。
在 PlayStation® 4 上开发《底特律:变人》期间,艺术家可以为所有材质设计独特的着色器树。这导致了数量惊人的顶点和像素着色器,因此我们从移植开始就知道这将是一个巨大的问题。
正如我们在 OpenGL® 引擎中所了解到的,在 PC 上编译着色器可能需要很长时间。在游戏制作过程中,我们生成了一个针对工作站 GPU 型号的着色器缓存。生成《底特律:变人》的完整着色器缓存需要一整夜!这个着色器缓存每天早上都提供给大家。但这并没有阻止游戏卡顿,因为驱动程序仍然需要将代码转换为本地 GPU 着色器汇编。
事实证明,Vulkan® 比 OpenGL® 更能解决这个问题。
首先,Vulkan® 不直接使用高级着色语言,如 HLSL,而是使用一种名为 SPIR-V 的标准中间着色语言。SPIR-V 使着色器编译更快,并且更容易为驱动程序着色器编译器进行优化。实际上,在性能方面,它与 OpenGL® 着色器缓存系统类似。
在 Vulkan® 中,着色器必须与 `VkPipeline` 关联。例如,一个 `VkPipeline` 可以由一个顶点着色器和一个像素着色器组成。它还包含一些渲染状态信息(深度测试、模板、混合等)以及渲染目标格式。这些信息对于驱动程序确保其拥有以最高效方式编译着色器所需的一切至关重要。
在 OpenGL® 中,着色器编译不知道着色器使用情况的上下文。驱动程序仍然需要等待绘制调用来生成 GPU 二进制文件,这就是为什么使用新着色器的第一个绘制调用在 CPU 上可能需要很长时间才能执行。
使用 Vulkan® 时,`VkPipeline` 提供了使用上下文,因此驱动程序拥有生成 GPU 二进制文件所需的所有信息,并且第一个绘制调用没有开销。我们还可以在创建 `VkPipeline` 时更新 `VkPipelineCache`。
最初,我们尝试在第一次需要时创建 `VkPipelines`。这导致了类似于 OpenGL® 驱动程序策略的卡顿。然后,`VkPipelineCache` 会得到更新,并且在下一次绘制调用时卡顿将消失。
然后我们预先在加载时创建 `VkPipelines`,但当 `VkPipelineCache` 未更新时,速度非常慢,以至于我们的后台加载策略受到了影响。
最后,我们决定在游戏第一次启动时生成所有 `VkPipeline`。这完全消除了卡顿问题,但现在我们面临一个新问题:`VkPipelineCache` 的生成需要很长时间。
《底特律:变人》大约有 99,500 个 `VkPipelines`!该游戏采用前向渲染方法,因此材质着色器包含所有照明代码。因此,每个着色器可能需要很长时间才能编译。
我们找到了一些优化此过程的想法:
最后,NVIDIA 的 Jeff Bolz 提出了一个重要的优化建议,这对我们非常有效。
许多 `VkPipelines` 非常相似。例如,一些 `VkPipelines` 可以共享相同的顶点和像素着色器,仅在模板参数等一些渲染状态上有所不同。在这种情况下,驱动程序可以在内部认为它是同一个管线。但如果我们同时创建它们,其中一个线程将只是等待另一个线程完成任务。我们的进程很自然地同时发送所有相似的 `VkPipelines`。作为解决方案,我们只是重新排序了 `VkPipelines`。“克隆”被放在了后面,它们的创建速度要快得多。
`VkPipelines` 的创建性能变化很大。特别是,它很大程度上取决于可用硬件线程的数量。使用拥有 64 个硬件线程的 AMD Ryzen™ Threadripper™,可能只需要两分钟。但在低端 PC 上,不幸的是可能需要超过 20 分钟。
最后一种情况对我们来说仍然太长了。不幸的是,进一步缩短此时间唯一的方法是减少着色器的数量。这要求我们改变创建材质的方式,尽可能多地共享它们。这在《底特律:变人》中是不可行的,因为艺术家必须返工所有材质。我们计划在下一款游戏中实现真正的材质实例化,但对于《底特律:变人》来说已经太晚了。
为了优化 PC 上绘制调用的速度,我们使用描述符索引配合 `VK_EXT_descriptor_indexing` 扩展。原理很简单:我们可以创建一个包含帧中使用的所有缓冲区和纹理的描述符集。然后我们可以通过索引访问缓冲区和纹理。主要优点是所有资源每帧只绑定一次,即使它们被许多绘制调用使用。这与 OpenGL® 中的无绑定资源非常相似。
我们为使用的所有类型的资源创建了资源数组:
我们只有一个主缓冲区,它在绘制调用之间变化(实现为环形缓冲区),其中包含一个引用正确的材质缓冲区和正确矩阵的描述符索引。每个材质缓冲区包含使用纹理的索引。
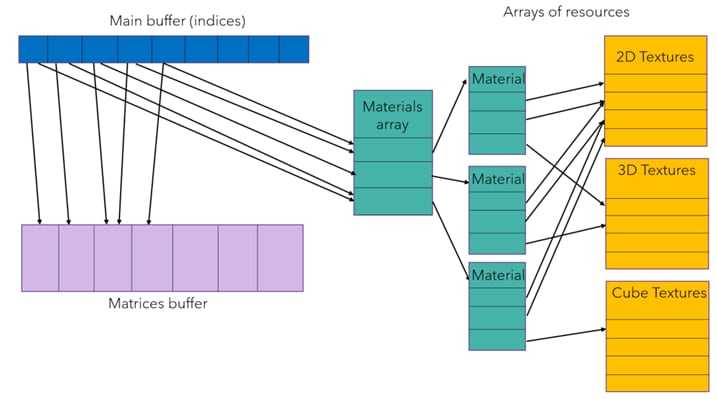
通过这种策略,我们可以使用少量描述符集,这些描述符集由我们所有的绘制调用共享,并包含绘制帧所需的所有信息。
即使数量很少,描述符集的更新仍然是一个瓶颈。如果一个描述符集包含许多资源,更新它可能会非常昂贵。例如,在《底特律:变人》中,一帧可能包含超过 4,000 个纹理。
我们实现了描述符集的增量更新,通过跟踪哪些资源在给定帧中变得可见,以及哪些资源退出可见性。这还限制了描述符数组的大小,因为它们只需要有能力处理给定时间内的可见资源。可见性跟踪是轻量级的,因为我们不使用昂贵的 `O(n.log(n))` 的相交算法。相反,我们使用两个列表,一个用于当前帧,一个用于前一帧。将仍然可见的资源从一个列表移动到另一个列表,并检查第一个列表中剩余的资源,有助于识别哪些资源进入和离开视锥体。
计算出的增量会保留四帧——我们使用三缓冲,并且骨骼对象的运动矢量计算需要另外一帧可用。一个描述符集至少应保持不变四帧,然后才能再次使用,因为 GPU 可能仍在对其进行处理。因此,我们将增量分批应用四帧。
最终,这项优化将描述符集更新时间减少了一个或两个数量级。
使用描述符索引允许我们使用 `vkCmdDrawIndexedIndirect` 将许多图元批处理到一个绘制调用中。我们使用 `gl_InstanceID` 来访问主缓冲区中的正确索引。图元可以批处理,如果它们共享相同的描述符集、相同的着色器管线和相同的顶点缓冲区。这非常高效,尤其是在深度和阴影通道中。绘制调用的总数减少了 60%。
第一部分到此结束。何不继续阅读?
在 第二部分 中,AMD 开发者技术工程师 Lou Kramer 将讨论 PC 和 AMD 显卡上特有的非统一资源索引。
在 第三部分 中,您将看到 Ronan Marchalot 讨论着色器标量化,Nicolas Vizerie 讨论多线程渲染列表、管线屏障处理和异步计算着色器,以及 Jonathan Siret 讨论内存管理。






















