
将《底特律:变人》从 PlayStation® 4 移植到 PC – 第一部分
将 PS4® 游戏《底特律:变人》移植到 PC 带来了一些有趣的挑战。Quantic Dream 和 AMD 工程师联合撰写的系列文章的第一部分,将讨论使用 Vulkan® 的决定,并探讨着色器管线和描述符。

这是三部分系列文章中的第三部分,由 Quantic Dream 的 3D 引擎总监 Ronan Marchalot 以及 3D 引擎高级开发人员 Nicolas Vizerie 和 Jonathan Siret,以及 AMD 的开发者技术工程师 Lou Kramer 联合撰写。
博客中包含的信息代表 AMD 或第三方作者在发布日期当时的观点。博客文章包含作者的个人意见,可能不代表 AMD 的立场、策略或观点。AMD 和/或第三方作者无义务更新任何前瞻性内容。GD-84
大家好,欢迎阅读我们关于将《底特律:变人》从 PS4 移植到 PC 系列文章的第三部分。在 第一部分 中,Quantic Dream 的 Ronan Marchalot 解释了他们为何决定使用 Vulkan®,并讨论了着色器管线和描述符。在 第二部分 中,AMD 的 Lou Kramer 讨论了 PC 和 AMD 显卡上非统一资源索引的使用。
在第三部分中,Ronan Marchalot 讨论了着色器标量化,Nicolas Vizerie 讨论了多线程渲染列表、管线屏障处理和异步计算着色器,而 Jonathan Siret 则讨论了内存管理。
正如我们在上一章中所见,到处使用描述符索引可能会导致着色器性能非常低下,如果我们使用了过多的非统一寄存器。
这不是 Vulkan® 特有的问题,我们在 PlayStation® 4 版本中已经实现了这些优化。但值得在此提及一些技巧。大多数向量寄存器指令来自顶点着色器的输入或像素着色器的输入。在我们的着色器中,我们在着色器的两个重要部分强制进行了标量化。
曾经有一段关于 gl_InstanceID 标量化的段落。然而,事实证明此优化并不完全符合规范,因此我们决定将其完全移除。
Quantic Dream 的引擎使用簇前向渲染来执行光照计算。
您可以在 GDC 会议库中 查看有关簇前向渲染技术的更多详细信息。
基本上,所有灯光都存储在簇单元中,每个像素着色器必须在执行光照之前找到簇索引。一种简单的实现方式性能不高,因为相邻像素可能访问不同的灯光。因此,着色器使用了大量的向量寄存器,性能非常低下。
id Software 的 Tiago Sousa 和 Jean Geffroy 在 SIGGRAPH 2016 上展示了一种 强制光照标量化 的方法。
S_CLUSTER_CELL Cell = g_rbClusterCells[cellIndex];int iIndex = int(Cell.iLightCount);while (iIndex > 0){ uint uLightIndex = g_rbClusterIndices[Cell.iFirstLightIndex + iIndex]; uint uLightIndexWarpMax = subgroupMax(uLightIndex); if (uLightIndexWarpMax == uLightIndex) { --iIndex; // Compute lighting with the uLightIndexWarpMax light }}代码并不复杂。这似乎违反直觉,因为我们添加了一个分支,但由于向量寄存器使用量的减少,整个着色器会快得多。
在 PlayStation® 4 上,绘图调用速度非常快,我们只使用一个线程来处理它们。这就是我们的渲染线程。我们还有一个主线程和几个执行各种任务的工作线程。
在 PC 上,绘图调用的速度慢得多,我们通常会等待渲染线程完成。所有其他任务(动画、可见性、物理)都更快,因此我们有很多未使用的 CPU 核心。因此,线程的负载不均衡。渲染线程显然是引擎的瓶颈。
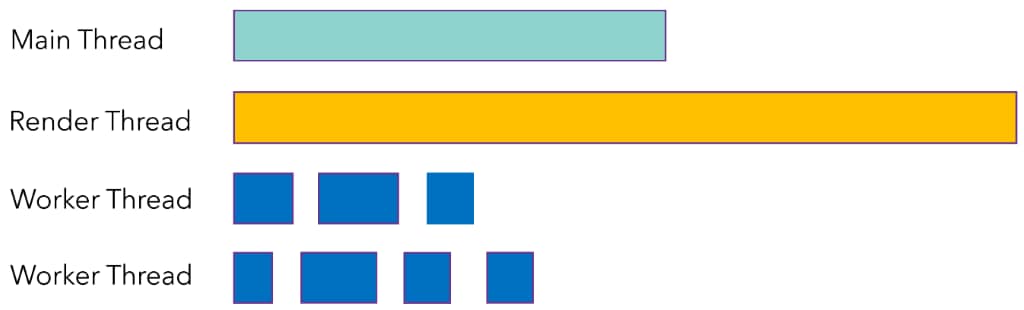
将渲染线程的工作转移到工作线程以优化帧率是一个非常自然的思路。使用 Vulkan®,我们可以在不同的线程中填充多个命令缓冲区。我们决定使用我们的作业系统来并行化渲染线程的工作。
Quantic Dream 的引擎使用我们称之为“渲染列表”的机制来显示对象。渲染列表将共享相同渲染目标的绘图调用分组在一起。
我们有不同的渲染列表
每个渲染列表由一个或多个作业处理,具体取决于绘图调用的数量。
每个作业将创建一个二次命令缓冲区。其中没有管线屏障、视口设置或渲染目标设置。它们只更新和绑定描述符、顶点和索引缓冲区,并发出绘图命令。
虽然这些命令缓冲区可以按任何顺序记录,但在调用 vkCmdExecuteCommands 之前,它们总是会被重新排序以保持与单线程通道相同的顺序。这对于透明对象尤其重要,因为它们的排序需要确定性。我们还为线程池中的每个线程创建了一个命令缓冲区池,这有利于性能并简化代码。这是因为在需要新的命令缓冲区时,对于给定的命令缓冲区池不存在并发访问。此外,我们会在可能的情况下回收它们。
我们使用了一个特性,允许我们在描述符集尚未完全指定时就绑定它,使用 VK_DESCRIPTOR_BINDING_UPDATE_AFTER_BIND_BIT_EXT 。当一个新描述符被分配或增量更新时,它会立即可用于绑定到其他渲染线程,而无需等待其更新。事实上,当资源数组在摄像机切换期间必须全部或几乎全部更新时,这可能会“长时间”阻塞。首先获取它的线程负责填充它。这被证明对于减少峰值很有用,这是端口期间的一个主要挑战,因为可能出现峰值的地方非常多。
此优化非常有效。它极大地减少了对渲染线程的等待。
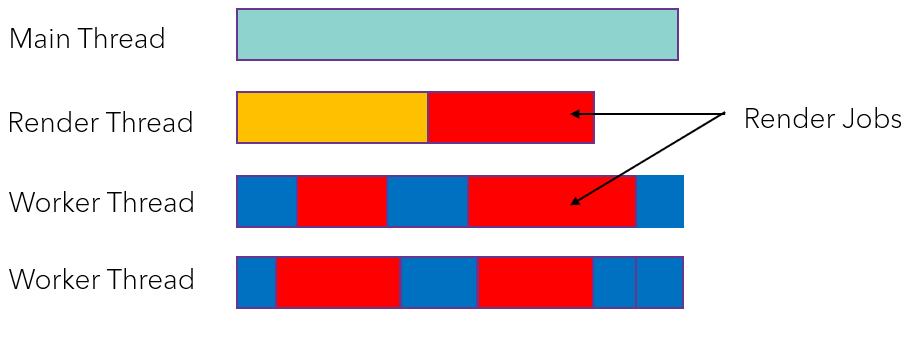
正如其他开发者所报告的,这是实现起来的困难部分。我们选择了自动管理资源。在这种情况下,复杂性与多种功能的组合有关(异步计算着色器、多线程渲染、“无绑定”资源、资源别名支持)。
此外,在开发《底特律:变人》期间,除了验证层检测到的错误之外,没有任何框架允许我们检查这些代码的正确性。在某些情况下,只有渲染的伪影才会暗示问题,其发生概率会因 GPU 和使用的驱动程序而异。最近为 Vulkan® 同步增加了 验证层支持,它支持单个命令缓冲区;这将来应该会很有帮助。
我们使用了“屏障上下文”的概念。屏障上下文将计算所有屏障和布局更改,并发出单个调用。每个资源都维护一个“屏障资源状态”,有助于检测内存冲突、别名转换和队列族转换。
由于时间限制,此功能不如其 PlayStation® 4 的对应功能先进。目前,灯光簇和 HBAO 计算着色器的填充是异步完成的。在 PlayStation® 4 上,帧末的后处理通道也与下一帧异步重叠。这对于 Vulkan® 渲染器也是可能的,但尚未实现。
总的来说,收益是适度的但并非可以忽略不计,考虑到目前只有一小部分已并行化。该实现相当严谨,因为它会检查每个资源是否被多个队列族错误地同时使用(仅限非零售版本)。这使我们能够放心地使用此功能,而且由于我们发现需要大量调整才能充分利用它,因此在开发过程中这是一个受欢迎的安全网。
我们使用了排他的资源共享,但这使得实现更加复杂。这是因为需要“队列传输所有权屏障”,它们用于在传输、图形或计算队列之间转换资源。由于我们的渲染器基于之前的代码,因此在开始异步部分时,我们无法推断将要使用的资源。这意味着有时需要进行一些来回的“修补”才能插入这些屏障。这也暗示了渲染图谱将极大地简化这部分工作。显然,Vulkan® 是为这种引擎架构设计的。
与其他引擎一样,我们选择了更渐进、更安全的方法来过渡到 Vulkan®。这对于《底特律:变人》的 PC 移植来说效果很好,否则由于已存在的较高层渲染代码的数量,将无法在我们的时间预算内完成。这也意味着仍有改进的空间。
我们使用了 AMD 的 Vulkan® 内存分配器,并且对此非常满意。
我们遇到的唯一问题是 GPU 内存的碎片整理。VMA 文档中建议的策略是等待所有命令缓冲区完成移动分配后再将它们更新到内存中的新位置。这非常安全,但会导致 FPS 峰值。我们开始修改代码以实现异步碎片整理。但当我们开始实现这个功能时,VMA 已经更新了类似的解决方案!
我们最终回滚了我们的代码并升级了 VMA,以避免未来升级时出现问题。我们需要仔细选择当前未被删除或传输到 GPU 内存的分配,并将它们发送给 VMA 进行碎片整理。并且,在等待队列完成后,我们在两个帧之后更新分配到其新位置。之前的内存将在更新后删除,并在之后几帧删除。
当然,这种解决方案意味着在碎片整理期间,分配在内存中会存在两次。但由于它只涉及少量分配,内存峰值几乎不明显。即使发送给 VMA 的分配数量只占总分配的一小部分,规律且频繁的碎片整理也会在有限的帧数内覆盖所有分配。
还需要进行其他修改以确保所有分配都已正确复制到内存中。在 VMA 中,最初只发出了缓冲区复制命令。这会导致平铺图像(我们的大部分纹理)出现问题,这些图像具有多个 mipmap 级别和/或面(立方体贴图)。这些命令缓冲区的创建已从 VMA 中移除,并实现了以确保缓冲区和图像分配都使用相应的复制命令进行复制。
碎片整理已在我们的补丁 3.0 中启用。它每两帧执行一次,并大大减少了 GPU 内存使用量。
对于我们的大多数渲染目标(缓冲区、阴影贴图等),这些目标取决于分辨率和图形选项,我们决定不将它们放入内存池中。它们仅在玩家更改分辨率或图形选项时才会更改,我们不想在碎片整理中移动大量内存。
当玩家更改分辨率时,我们会销毁所有渲染目标,并等待所有命令缓冲区完成。这样,我们可以在内存释放时创建新的渲染目标,而不会超出 GPU 预算。如果我们不这样做,有时会有为两个不同分辨率分配的渲染目标。这不算什么大问题,因为如果驱动程序没有物理内存,它可以尝试使用虚拟内存,但它会在几帧内减慢游戏速度,并且非常明显。
碎片整理的实现还促使我们仔细分析 GPU 内存使用情况。VMA 可以将 VmaAllocator 的所有分配转储到文件中。然后可以使用 VmaDumpVis 将转储结果汇总成一张图片,使我们能够分析 VMA 使用的池和专用分配。此转储还可用于跟踪内存泄漏,这些泄漏在《底特律:变人》中退出关卡返回主菜单或前往下一个关卡时尤其存在(每个分配都可以标记一个名称以便于识别)。
下图显示了启用或禁用碎片整理的区别。这些结果是在从任务返回主菜单后生成的。分配数量相同(约 950 个),但在未启用碎片整理时总分配内存更高(图 1)。更重要的是,我们可以看到一些分配散布在六个 128 MB 的块之间。分配的块并没有丢失,但块中间的分配可能会干扰新的分配。例如,一个 96 MB 的分配将需要一个新的块,因为它无法适应任何一个块。
当然,返回菜单并不一定代表游戏内的实际情况,但在所有关卡中也观察到了内存收益。
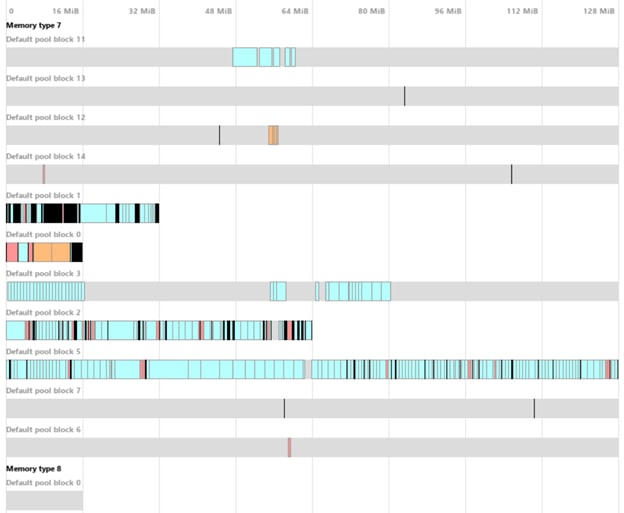
图 1 - 未启用碎片整理
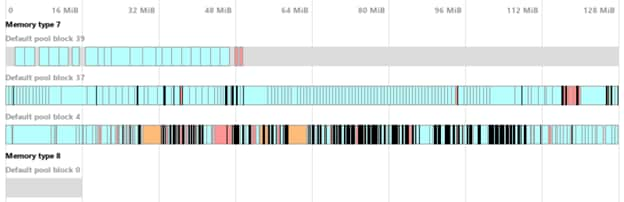
图 2 - 启用碎片整理
另一项 GPU 内存优化是从 PlayStation® 4 移植过来的,即对引擎渲染目标的专用分配使用 GPU 内存别名。内存别名允许将单个 GPU 内存分配 (VmaAllocation) 绑定到不同的纹理或缓冲区。我们的某些渲染目标纹理共享相同的 VkImageCreateInfo 参数(尤其是尺寸和 mip 级别)。因此,它们遵循 Vulkan® 定义的条件以实现别名。专用分配内存别名功能也必须得到支持并启用。
为了重用这些分配,必须提取并重新定义 VMA 的创建和绑定函数,以允许将分配传递给这些函数并应用于新纹理。如果绑定到现有分配失败,我们将回退并创建一个新的分配来绑定。
GPU 内存别名可节省多达 164 MB(从全高清的 1.60 GB 降至 1.44 GB)。
VMA 的另一个重要功能是使用自定义池。VMA 为每个需要分配的内存类型创建一个默认内存池。然而,默认池可能会在任何时候分配内存块,且大小不断增加。这不适用于我们用于上传的特定内存类型。对于该内存类型,在某些任务开始时,其默认池会在稳定下来之前分配大量内存块,从而产生大量可见的卡顿。为了缓解此问题,我们首先监控该内存类型的用法,并确定了需要预先分配的足够但不过度的内存量。因此,我们创建了一个自定义池,其中包含基础量的预分配内存块,这些内存块将在游戏退出前都不会被释放。
《底特律:变人》移植到 PC 的过程是一次很棒的经历。我们引擎的 Vulkan® 版本比 OpenGL® 版本速度快得多。
我们仍有许多工作要做来改进 PC 引擎。例如,我们希望探索渲染图谱的方法。这将有助于我们改进屏障管理、异步着色器和内存别名。
但这将是另一款游戏的故事了……






















