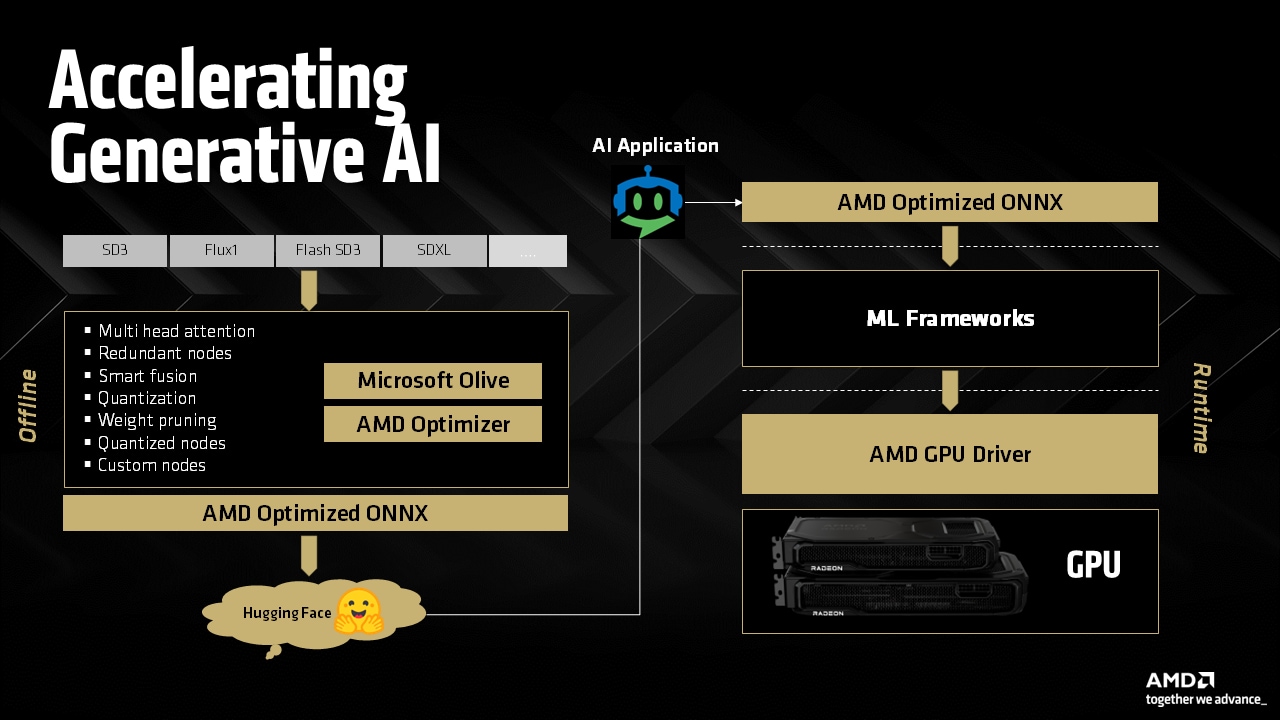
加速 AMD Radeon™ GPU 上的生成式 AI
在 Hugging Face 上发现针对 AMD Ryzen™ AI APU 和 Radeon™ GPU 优化的 AMD ONNX 模型,以及 AMD Radeon RX 9000 系列先进 AI 加速器带来的惊人性能。
如果您有兴趣在本地硬件上部署先进的 AI 模型,利用现代 AMD GPU 或 APU 可以提供高效且可扩展的解决方案。您无需专门的 AI 基础设施即可尝试大型语言模型 (LLM);只需要一台装有 PyTorch 的、配备了近期 AMD 显卡的、性能不错的 Microsoft® Windows® PC 即可。
适用于 AMD 的 Windows 和 Linux 版 PyTorch 目前作为公开预览版提供。您现在可以使用 AMD Radeon™ RX 7000 和 9000 系列 GPU 以及精选的 AMD Ryzen™ AI 300 和 AI Max APU 来使用适用于 AMD 的原生 PyTorch 进行 AI 推理,从而在 Windows 上无缝地在 AMD 硬件上执行 AI 工作负载,而无需任何变通方法或双引导配置。如果您是新手并刚开始使用 AMD ROCm™,请务必在此处查看我们的入门指南。
本指南旨在帮助开发人员在 Windows PC 上使用 PyTorch 和 AMD GPU 或 APU 设置、配置和本地运行 LLM。您不需要任何 PyTorch 或深度学习框架的先前经验。
| AMD Radeon™ AI PRO R9700 | AMD Radeon™ RX 7900 XTX | AMD Radeon™ PRO W7900 | AMD Ryzen™ AI Max+ 395 |
| AMD Radeon™ RX 9070 XT | AMD Radeon™ PRO W7900 双槽 | AMD Ryzen™ AI Max 390 | |
| AMD Radeon™ RX 9070 | AMD Ryzen™ AI Max 385 | ||
| AMD Radeon™ RX 9060 XT | AMD Ryzen™ AI 9 HX 375 | ||
| AMD Ryzen™ AI 9 HX 370 | |||
| AMD Ryzen™ AI 9 365 |
支持的操作系统:Microsoft® Windows® 11
AMD Software: PyTorch on Windows Preview Edition 25.20.01.14 驱动程序
Python 3.12 - Python Release Python 3.12.0 | Python.org
首先,我们需要打开命令提示符。
cmd,然后按Enter。将弹出一个黑色的终端窗口。
“虚拟环境”就像一个干净、空白的沙箱,用于 Python 项目。
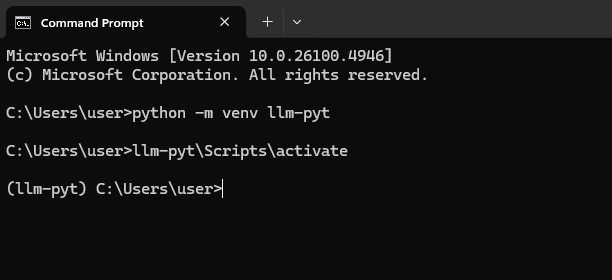
在命令提示符中,键入以下命令并按Enter。这将创建一个名为 llm-pyt 的新文件夹,用于存放我们的项目。
python -m venv llm-pyt
接下来,我们需要“激活”此环境。可以将其理解为进入沙箱。
llm-pyt\Scripts\activate
您会知道它是否成功,因为您的命令行的开头会显示 (llm-pyt)。
现在我们将安装那些能完成繁重工作的软件库。其中最重要的是PyTorch,这是一个用于构建和运行 AI 模型的开源框架。我们需要一个专门为与 AMD 的 ROCm 技术配合而构建的 PyTorch 版本。
我们还将安装 Hugging Face 的两个库:Transformers 和 Accelerate,这两个库可以极大地简化下载和运行最先进 AI 模型的操作。
在已激活的命令提示符中运行以下命令。此命令指示 Python 的包安装程序 (pip) 下载并安装用于 ROCm 的 PyTorch 以及其他必要的工具。
pip install --no-cache-dir https://repo.radeon.com/rocm/windows/rocm-rel-6.4.4/torch-2.8.0a0%2Bgitfc14c65-cp312-cp312-win_amd64.whlpip install --no-cache-dir https://repo.radeon.com/rocm/windows/rocm-rel-6.4.4/torchaudio-2.6.0a0%2B1a8f621-cp312-cp312-win_amd64.whlpip install --no-cache-dir https://repo.radeon.com/rocm/windows/rocm-rel-6.4.4/torchvision-0.24.0a0%2Bc85f008-cp312-cp312-win_amd64.whlpip install transformers accelerate到了检验成果的时刻了。让我们给新设置的任务:运行一个小型但功能强大的语言模型,名为Llama 3.2 1B。
请确保您的命令提示符仍处于 (llm-pyt) 环境激活状态。如果关闭了,只需重新打开 cmd 并运行 llm-pyt\Scripts\activate。
现在,启动 Python
python复制下面的整个代码块。将其粘贴到您的 Python 终端(显示 >>> 的地方)并按Enter。
首次运行时,它将下载模型(几 GB),可能需要几分钟。之后运行会快得多。
import torchfrom transformers import pipelinemodel_id = "unsloth/Llama-3.2-1B-Instruct"pipe = pipeline( "text-generation", model=model_id, dtype=torch.float16, device_map="auto")pipe("The key to life is")您应该会看到类似的输出
[{'generated_text': 'The key to life is not to get what you want, but to give what you have.The best way to make life more meaningful is to practice gratitude, and to cultivate a senseof contentment with what you have. If you want to make life more interesting, you must bewilling to take risks, and to embrace the unknown. The best way to avoid disappointment isto be patient and persistent, and to trust in the process. By following these principles,you can live a more fulfilling life, and make the most of the time you have.'}]您可以通过键入 exit() 并按Enter来返回到命令提示符。
exit()运行单个提示很有趣,但真正的对话更好。在本节中,我们将创建一个交互式聊天循环,该循环可以“记住”对话,让您可以与 AI 进行来回交流。
在文本编辑器中打开一个新文件。
复制并粘贴下面的聊天机器人代码。
import torchfrom transformers import pipeline
print("Loading chat model...")
model_id = "unsloth/Llama-3.2-1B-Instruct"pipe = pipeline( "text-generation", model=model_id, dtype=torch.float16, device_map="auto",)
# This list will store our conversation historymessages = []
print("\nChatbot ready! Type 'quit' or 'exit' to end the conversation.")print("-" * 20)
while True: # Get input from the user user_input = input("You: ")
# Check if the user wants to exit if user_input.lower() in ["quit", "exit"]: print("Chat session ended.") break
# Add the user's message to the conversation history messages.append({"role": "user", "content": user_input})
# Generate the AI's response using the full conversation history outputs = pipe(messages, max_new_tokens=500, do_sample=True, temperature=0.7)
# The pipeline returns the full conversation. The last message is the new one. assistant_response = outputs[0]['generated_text'][-1]['content']
# Add the AI's response to our history messages.append({"role": "assistant", "content": assistant_response})
# Print just the AI's new response print(f"AI: {assistant_response}")run_chat.py,放在同一个用户文件夹中。步骤 2:运行您的聊天机器人
在命令提示符中,运行新脚本
python run_chat.py终端现在会提示您输入 You:。输入一个问题并按Enter。AI 将做出回应,您可以提问后续问题。聊天机器人将记住对话的上下文。
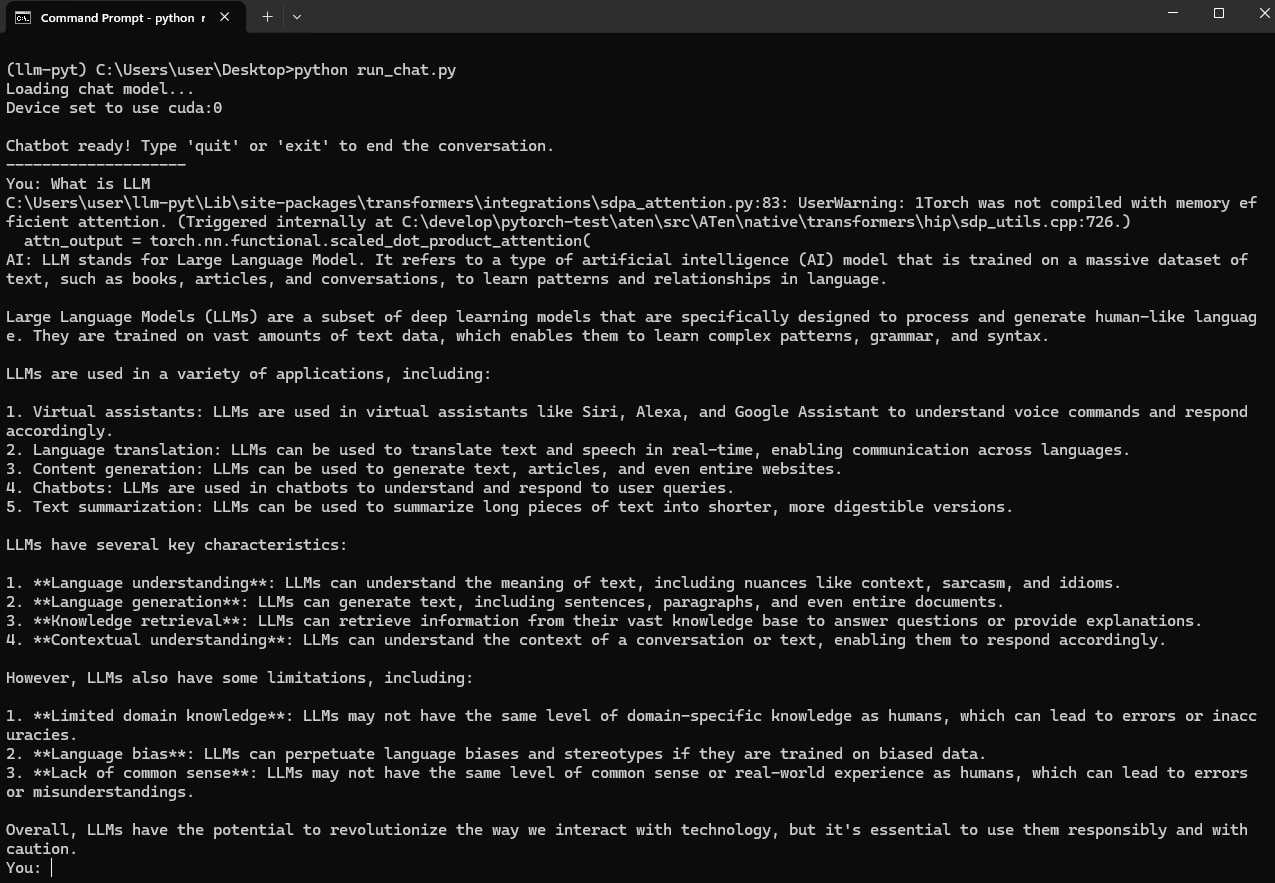
说明
运行 LLM 时,您会看到类似此处的警告消息
UserWarning: 1Torch was not compiled with memory efficient attention.(Triggered internally at C:\develop\pytorch-test\aten\src\ATen\native\transformers\hip\sdp_utils.cpp:726.)不用担心,这是预期的,您的代码工作正常!
简单来说: PyTorch 2.0+ 引入了一个名为“内存高效注意力”的功能来加速。适用于 AMD 的 Windows 版 PyTorch 的当前版本开箱即用,不包含此特定优化。当 PyTorch 找不到它时,它会打印此警告并自动回退到标准、可靠的方法。
通过遵循本博客,您应该能够开始使用 AMD 消费级图形硬件在 Windows 上使用 PyTorch 运行基于 Transformer 的 LLM。
您可以在 AMD 高级软件副总裁兼首席软件官 Andrej Zdravkovic 的博客此处了解更多关于我们走向 AMD ROCm 在 Windows 和 Linux 上的 Radeon 的历程。
Windows 是 Microsoft 公司集团的商标。