在优化游戏或其他程序的性能时,最重要的事情是先获取硬数据——使用一些工具进行性能分析,了解发生了什么以及将精力集中在何处。有许多可用的性能分析工具。在讨论图形时,我们意识到 GPU 实际上是一个协处理器,可以按照自己的节奏执行提交的工作,因此 GPU 性能分析工具提供了一种特定的图形类型来对其进行可视化。在本文中,我将解释如何阅读这种类型的图形。
让我们以 Radeon™ GPU Profiler (RGP) 为例。该程序是免费提供的,并兼容 AMD 显卡。它可以捕获使用 Direct3D® 12 或 Vulkan® 的程序的 data。当我们打开 capture 文件并转到 Overview > Frame summary 选项卡时,我们可以看到类似下图的图形:

乍一看,它可能看起来很吓人,但请放心,请跟着我。我将一步一步解释。我不知道这种类型的图形是否有名称,所以让我们称之为“队列图”,因为它显示了提交给图形卡并由其执行的任务队列。
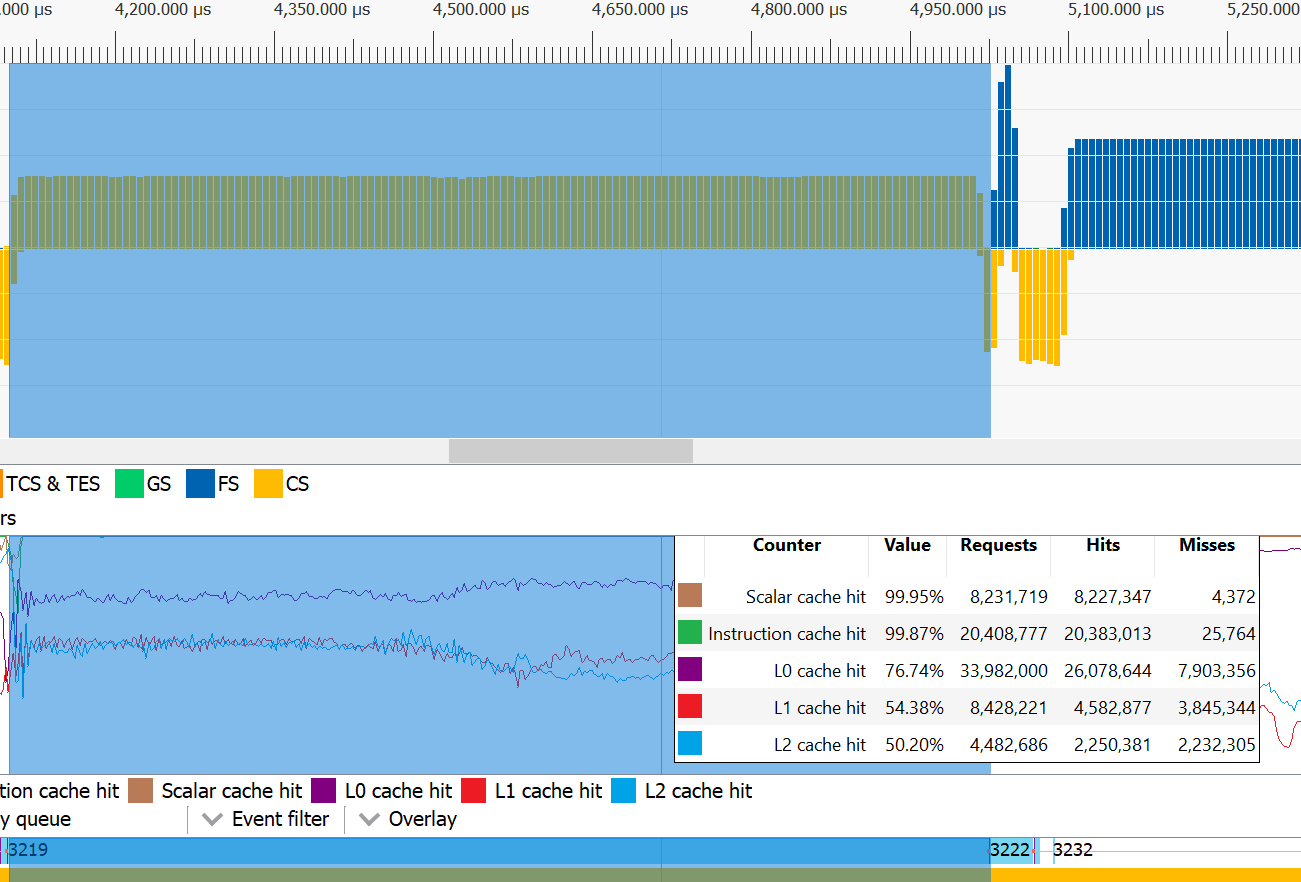
水平轴是时间,以恒定的速率向右移动。垂直轴是队列,队列的前端在底部,稍后入队的 item 堆叠在顶部。
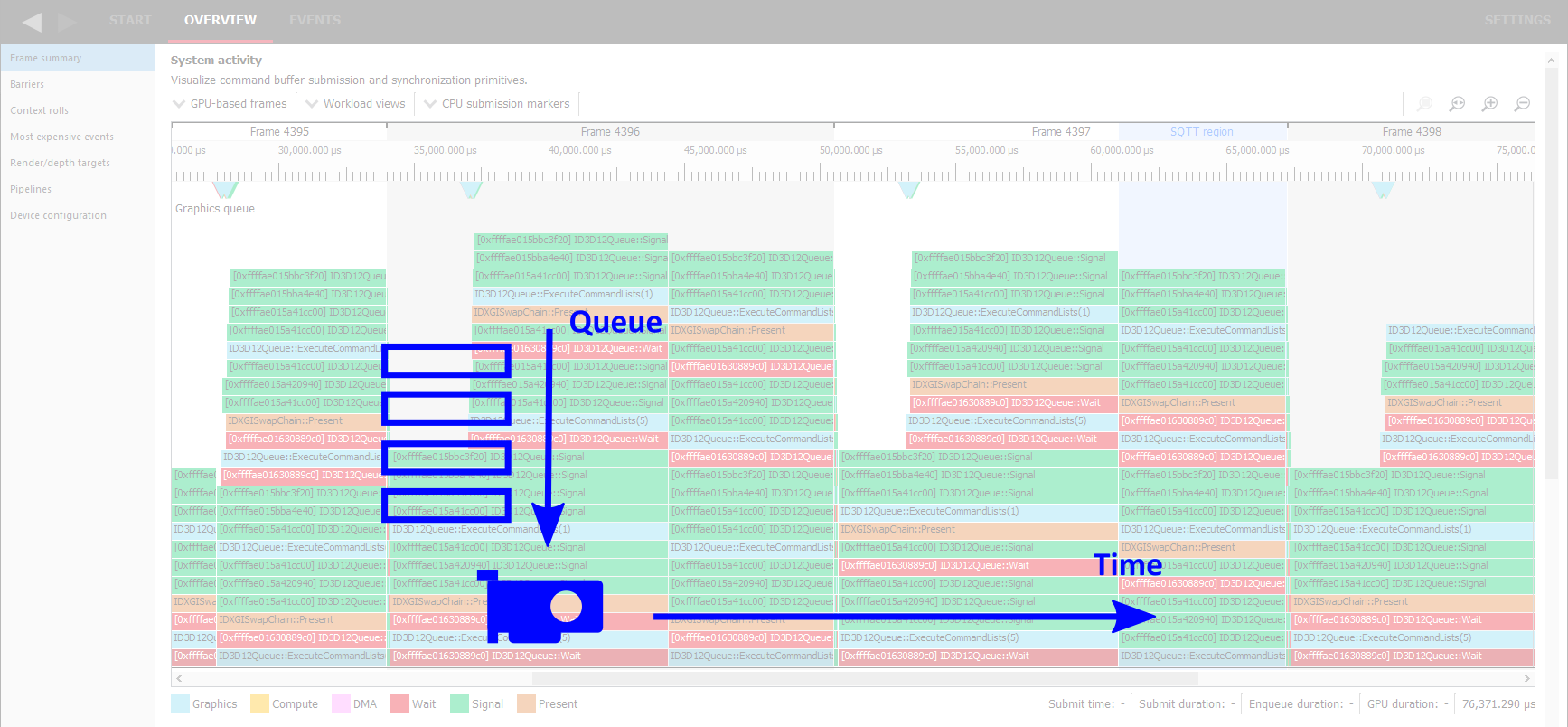
在每个时间点,底部行上的 item 是当前在 GPU 上执行的 item。此行上方的所有 item 都在等待它的 turn。这意味着从图形中我们可以看到并测量某个工作项(例如此示例中的 D3D12 ExecuteCommandLists 调用)何时入队、何时开始执行以及执行它花了多长时间。底部块的宽度代表执行所需的时间。请注意,沿着“楼梯”下降的工作项本身没有任何意义。它只是意味着它前面的某个 item 已完成,因此前面的队列变短了。只有当它最终到达底部行时,它才真正开始执行。
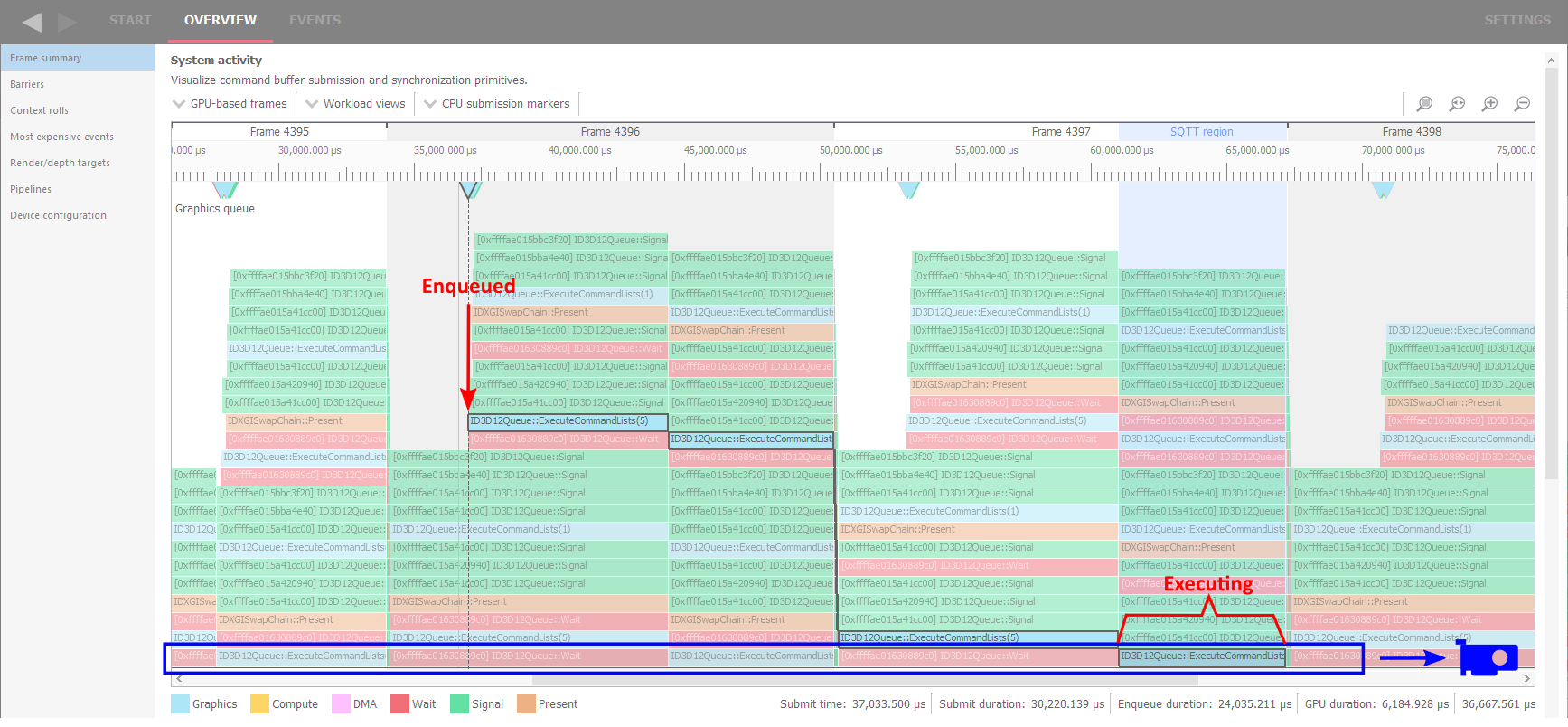
另一件需要注意的事情是,有些 item 在队列中等待,但执行它们所花费的时间并不显著。这些是简单而快速的命令,例如此处标记的绿色 Signal 函数调用。当它前面的所有 item 完成后,它也将立即完成。
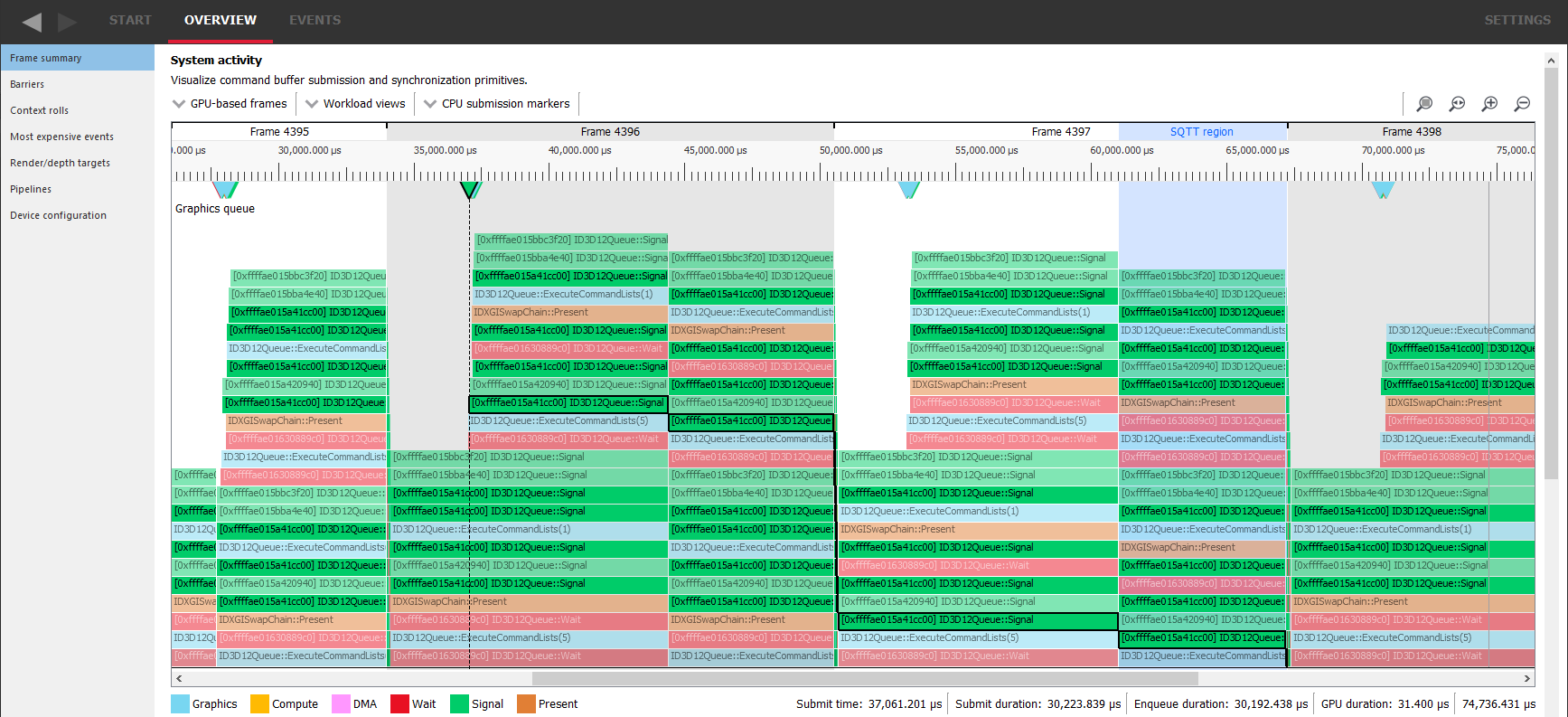
如果我们考虑到游戏是逐帧工作的这一事实,我们可以从该图形中得出更多观察结果。每一帧都执行命令来绘制整个图像,从清除背景、3D 对象到 UI,最后以调用 Present 函数结束,此函数在此处以棕色标记。通过查找这类 item,我们可以确定新帧何时开始。例如,在点“A”处,GPU 仍在执行帧 N 的命令,而我们已经为下一帧 N+1 入队了所有命令,包括它的下一个 Present,并且帧 N+2 的命令也正在排队末尾堆叠。因此,我们可以预期游戏在显示图像时会有 2 帧的延迟。

Microsoft® 的免费工具 GPUView 使用相同类型的图形——它可以记录和显示系统中发生的非常底层的事件。(链接的文章非常旧——现在安装该工具的方法是获取 Windows® Assessment and Deployment Kit (Windows ADK),并且方便的 UI 是 UIforETW)。正如您在此处看到的,我的显卡的“3D Hardware Queue”和正在运行的游戏的软件“Device Context”都显示了提交给渲染的工作包。
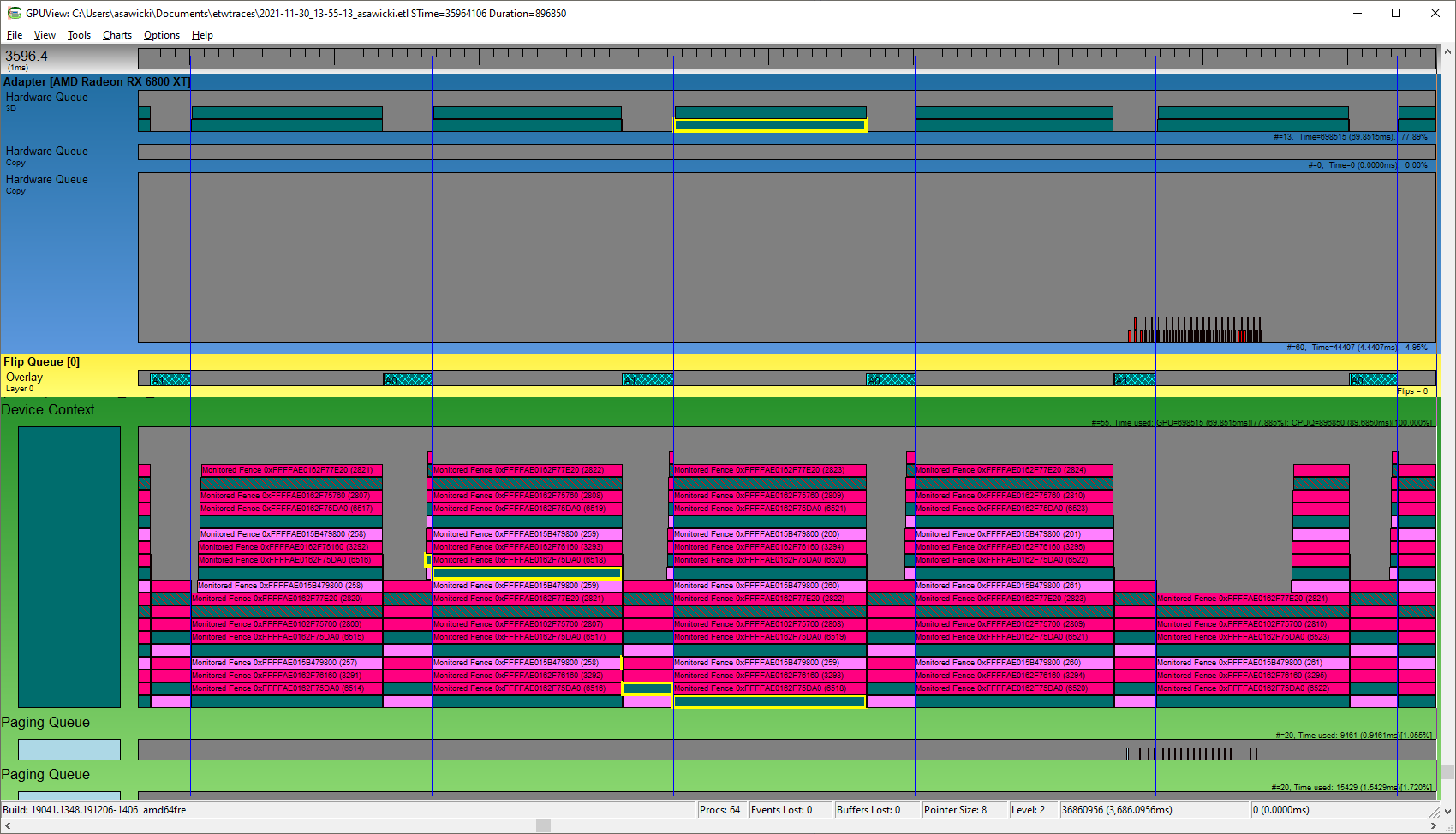
我们可以从该图形中提取的一个重要信息是,GPU 并非 100% 的时间都在忙碌。GPUView 实际上显示了右侧的数字,对于当前视图是 77.89%。这意味着游戏没有受 GPU 限制。降低图形质量设置不会提高帧率(FPS)。这种情况经常发生,当游戏在 CPU 上执行繁重计算时,或者当游戏达到 60 FPS 并且我们启用了 V-sync 时。在这里,我们遇到了后一种情况,因为我们可以看到垂直同步的 moments 被标记为蓝色线条,而渲染每一帧似乎都一直被阻塞直到那一刻。
请注意,此处描述的图形与 flame graphs 或 flame charts 不同,后者显示嵌套内容的层次结构,而不是队列。例如,函数调用的调用堆栈。
此博客 最初发布 在 asawicki.info 上,您可以在那里找到更多关于类似主题的博客文章。