AMD FidelityFX™ Variable Shading
AMD FidelityFX Variable Shading 将可变速率着色引入您的游戏。
在使用 Direct3D 12 为配备独立显卡的 PC 开发图形应用程序时,我们主要处理两种内存:主板上的系统 RAM 和显卡上的显存 (VRAM)。主处理器 (CPU) 可以快速直接地访问系统 RAM,而图形处理器 (GPU) 可以快速直接地访问 VRAM。它们之间的通信需要通过 PCI Express® 总线进行。在图形应用程序中,典型的数据流是从 CPU 传输到 GPU。数据量可能有所不同,从每帧更新小的常量缓冲区(包含场景中对象的新位置)到流式传输从磁盘加载的大纹理和网格。
在 Direct3D 12 API 中,有多种方式可以执行此类数据上传。一种典型的方法是在 D3D12_HEAP_TYPE_UPLOAD 内存(通常位于系统 RAM 中)中分配一个“暂存”副本,使用 Map() 获取 CPU 指针,写入数据,然后在 D3D12_HEAP_TYPE_DEFAULT(即 VRAM)中有一个另一个缓冲区,并在该缓冲区被 GPU 使用之前(例如绑定到着色器插槽作为顶点缓冲区、常量缓冲区等)使用 CopyResource() 等函数发出复制操作。
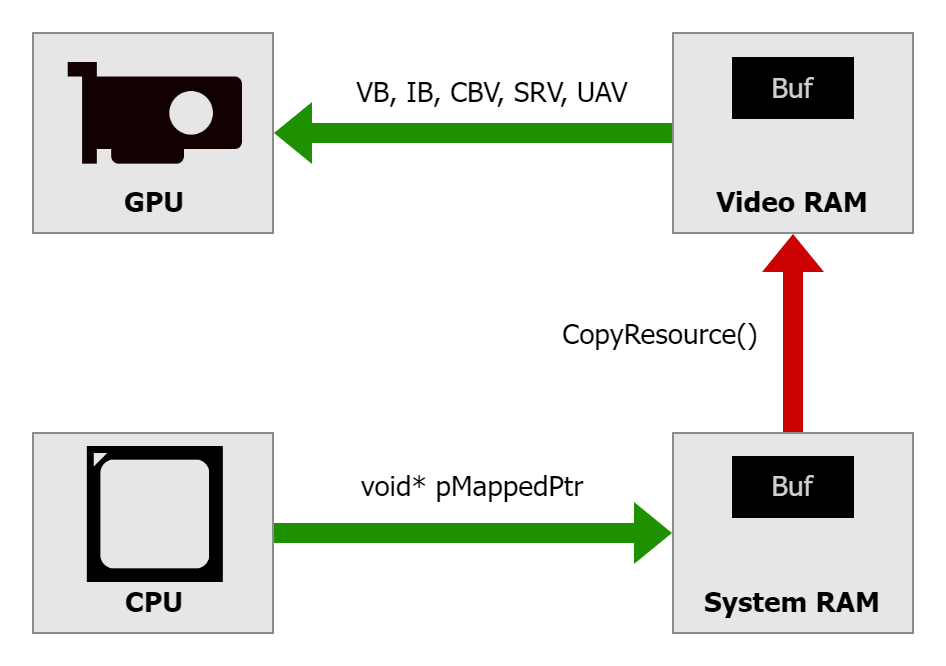
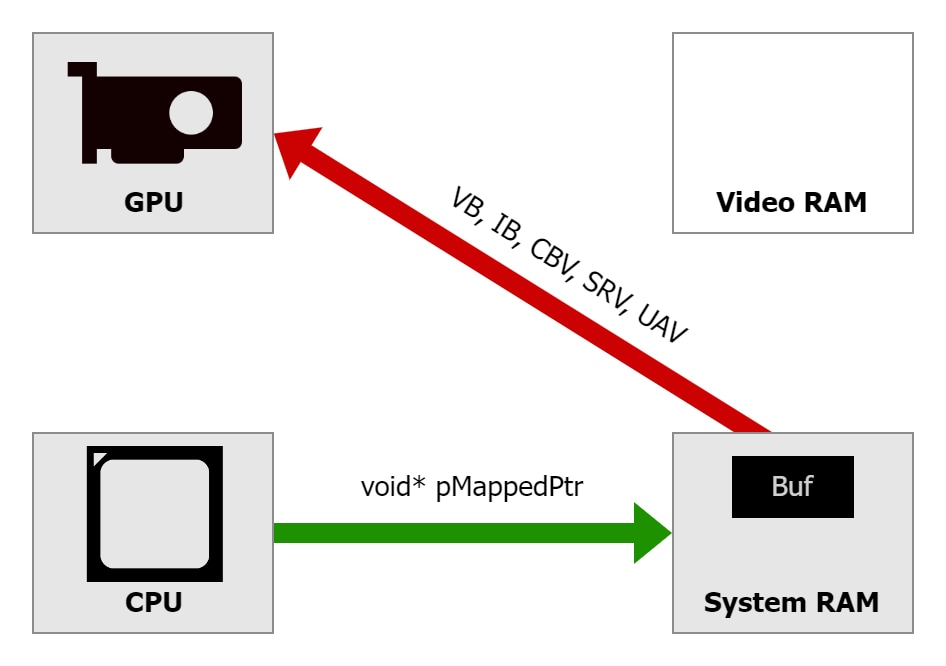
另一种选择是直接从着色器访问 UPLOAD 堆中的原始缓冲区。可以获取此类缓冲区的地址,创建描述符,并像访问绑定到图形管线的任何其他资源一样在着色器代码中访问它。此方法可以避免数据的额外复制,但着色器运行速度可能会变慢,因为直接从 UPLOAD 堆中的缓冲区读取数据需要通过 PCIe® 访问系统 RAM。
两个缓冲区之间的复制操作也可以通过多种方式执行。诸如 CopyResource() 或 CopyBufferRegion() 之类的复制命令可以在具有不同特征的复制、图形或计算队列上执行。也可以通过编写一个计算着色器来执行复制,该着色器逐个读出源缓冲区并写入目标缓冲区。
还有另一种可能性:拥有一个位于显存中但可直接映射到 CPU 的内存池。此功能已存在很长时间,并且被称为 Base Address Register (BAR)。这个特殊的内存区域通常只有 256 MB。现代 PC 可以将其扩展到整个 VRAM,使其对 CPU 完全可访问。这称为 Resizable BAR (ReBAR),需要在主板的 UEFI/BIOS 设置中明确启用。直到最近,开发人员使用 Direct3D 12 才能访问此内存,而在 Vulkan® 中可以(具有 VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT 和 VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT 设置的内存类型)。因此,我们在 2021 年 6 月发布了一篇题为《如何充分利用 Smart Access Memory (SAM)》的文章,其中解释了我们的图形驱动程序如何通过将 UPLOAD 堆中分配的某些资源放置在 VRAM 中来自动利用该内存。另请参阅:AMD Smart Access Memory。
在 2023 年 3 月,随着 Agility SDK 版本 1.710.0-preview 的发布,Microsoft 通过另一种内存堆类型扩展了 D3D12 API:D3D12_HEAP_TYPE_GPU_UPLOAD。使用此标志,ReBAR 内存可供使用 D3D12 进行开发的开发人员显式使用。要了解更多信息,请参阅 DirectX Developer Blog 上的 公告和 官方规范。支持它的 AMD 驱动程序已于 2023 年 6 月作为 AMD Software: Adrenalin Edition 23.10.01.14 for DirectX®12 Agility SDK 发布。自 2024 年 3 月 11 日发布的 Agility SDK 1.613.0 起,该功能已可供零售使用,不再需要启用 Windows 中的开发者模式。
为了有效地使用这种新类型的内存,我们需要了解它的特性。它通常位于 VRAM 中,尽管在某些情况下(例如在 PIX 下调试时)可能会回退到系统 RAM。在此内存中创建的缓冲区可以被映射并直接从 CPU 访问。当然,GPU 也可以使用它们,例如作为顶点缓冲区或索引缓冲区。从 CPU 的角度来看,该内存是未缓存且写组合的,就像 UPLOAD 堆一样,但这次,CPU 访问需要通过 PCIe 总线。
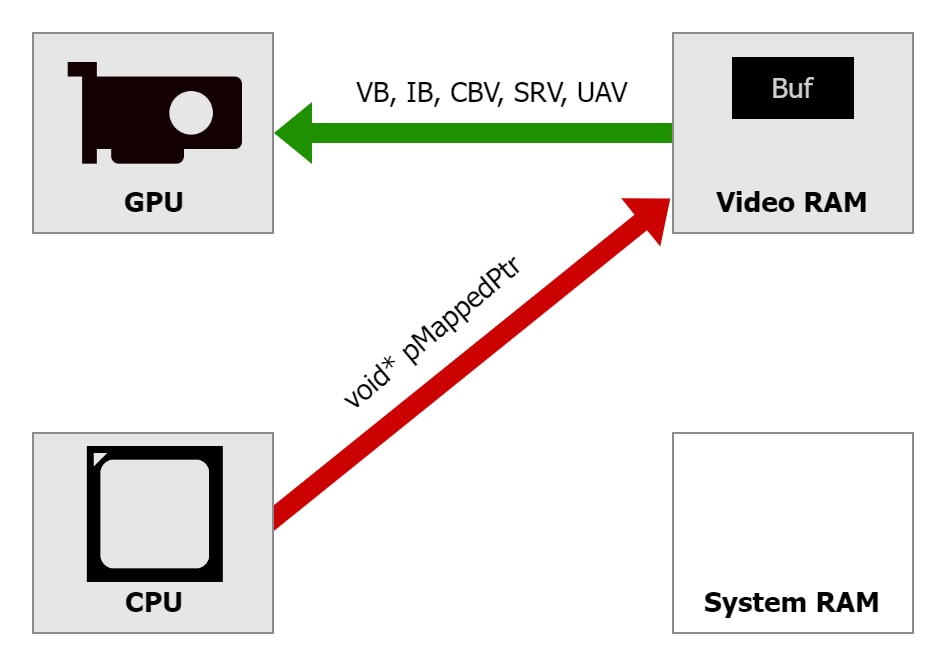
D3D12_HEAP_TYPE_GPU_UPLOAD 中的资源,其速度与使用 DEFAULT 堆一样快,因为它们也位于 VRAM 中。这为 CPU 写入与 GPU 读取的同一缓冲区提供了机会,而无需额外复制缓冲区来占用内存,也无需执行额外的复制操作来花费额外的时间和精力。D3D12_HEAP_TYPE_GPU_UPLOAD 中的缓冲区可能会比写入系统 RAM 慢,因为它们需要通过 PCIe 总线,但对于现代 PCIe Gen 4 及更高版本,如果正确执行(请参阅后续段落),写入速度可能与写入系统 RAM 的速度相当。D3D12_HEAP_TYPE_GPU_UPLOAD 是写组合的,所以在写入数据时使用良好的访问模式(良好的局部性)非常重要。建议从普通系统内存执行 memcpy()。顺序写入(逐个值,向前或向后)也表现良好。随机访问或大跨度写入则不然。这与 UPLOAD 堆的建议相同,但在 GPU_UPLOAD 中,良好和糟糕访问模式之间的性能差异更大。例如,写入 GPU_UPLOAD 时,单个值之间的跨度超过 32 个 DWORD 可能比写入 UPLOAD 慢 2 倍。D3D12_HEAP_TYPE_GPU_UPLOAD 是未缓存的,所以切勿从中读取,仅写入非常重要。没有“只写内存”——从此类指针读取可以保证正常工作,但速度极慢。很容易意外地引入一些读取,例如通过执行 pMappedPtr[i] += v;。这与 UPLOAD 堆的建议相同,但在 GPU_UPLOAD 中,内存读取的性能损失更大。D3D12_HEAP_TYPE_GPU_UPLOAD 可直接映射,因此通常可以避免数据复制,但当需要在两个位于 VRAM 中的缓冲区之间进行复制时,请优先使用图形或计算队列执行。复制队列旨在在通过 PCIe 复制数据时达到最大吞吐量。对于 GPU-GPU 复制,它可能运行较慢。编写自定义着色器来执行此类复制可能是一个好主意,因为它也可以达到峰值性能,并且可以与其他此类复制、其他绘制调用或计算调度并行运行,因为它不像复制命令那样在每个命令前后发出隐式障碍。使用着色器复制对于小批量数据尤其有利。D3D12_HEAP_TYPE_GPU_UPLOAD 位于 VRAM 中,因此请注意其中创建的资源的大小。它们将与其他 DEFAULT 堆中的资源一起计入 VRAM 使用量。当它们超出可用预算时(通过 DXGI_MEMORY_SEGMENT_GROUP_LOCAL 查询 IDXGIAdapter3::QueryVideoMemoryInfo 函数),新的分配可能会失败,或者应用程序可能会遇到性能下降,因为一些分配会在后台默默迁移到系统 RAM,而我们无法显式控制或知晓。Map()/Unmap() 的开销。请注意,该功能可能并非在所有平台上都可用。启用 ReBAR 需要在许多地方进行硬件和软件支持,包括支持更新 BIOS 的主板、支持更新显卡驱动程序的显卡以及在 UEFI/BIOS 设置中明确启用。需要通过查询 D3D12_FEATURE_DATA_D3D12_OPTIONS16::GPUUploadHeapSupported 来检查支持。当此标志为 FALSE 时,应用程序需要回退到其他数据上传方法。
从 CPU 代码写入 GPU 执行的着色器读取的同一缓冲区会带来竞态条件错误的风险。需要采取措施确保正确同步。GPU 与 CPU 异步工作,通常会渲染一些时间之前入队的帧,而 CPU 会领先一到两帧,计算逻辑并为未来的帧记录图形命令。虽然不需要显式的缓存刷新、失效或其他类型的障碍即可使 CPU 写入的数据对 GPU 可用,但您需要确保 CPU 不会覆盖 GPU 仍在使用的内容。在命令列表入队执行之前写入数据,并等待栅栏以确保执行已完成。对这些数据进行双/三缓冲或使用环形缓冲区可能是一个不错的解决方案。
本文仅讨论了缓冲区,但与 D3D12_HEAP_TYPE_UPLOAD 不同,GPU_UPLOAD 堆也允许在 D3D12_TEXTURE_LAYOUT_UNKNOWN 中创建纹理。使用它们,可以使用 ID3D12Resource::WriteToSubresource 函数将数据从系统内存直接上传到此类纹理,从而节省 CPU 像素排样的周期。但是,这可能不是最高效的纹理上传方法。
D3D12 Memory Allocator 库在您从“master”分支中选择的最新版本中提供了对 GPU Upload Heaps 的支持。
在可用且支持的系统上,使用新的 D3D12_HEAP_TYPE_GPU_UPLOAD 可以作为 CPU 到 GPU 上传数据的替代方法。如果实现得当,它可以获得更好的性能。一种通用的思考方式是数据穿越 PCIe 总线的位置发生了变化。使用 GPU_UPLOAD 堆时,发生在 CPU 代码写入映射指针时,而不是复制操作,或者 GPU 着色器代码直接访问系统 RAM 时——如上图所示。实际性能可能因特定项目而异,因此我们建议在各种硬件/软件配置下进行测量,并选择最适合您的解决方案。
©2023 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, Adrenalin Edition, Radeon, Ryzen, and combinations thereof are trademarks of Advanced Micro Devices, Inc. Microsoft is a registered trademark of Microsoft Corporation in the US and/or other countries. PCIe and PCI Express are registered trademarks of PCI-SIG Corporation. Vulkan and the Vulkan logo are registered trademarks of the Khronos Group Inc. Other product names used herein are for identification purposes and may be trademarks of their respective owners.