AMD Radeon™ Memory Visualizer
AMD Radeon™ Memory Visualizer (RMV) 是一款工具,可让您深入了解应用程序如何使用内存图形资源。
为成功发布 Windows 游戏,对视频内存使用进行预算、测量和调试至关重要。开发人员可以借助 Microsoft® 的 Windows® 性能分析器 (WPA) 工具以及对操作系统如何管理视频资源的总体理解,高效地实现这一目标。
Windows 性能分析器是 Windows 性能工具包的一部分,而 Windows 性能工具包又是 Windows 10 SDK 的一部分。安装 Windows 10 SDK 时,请确保选中“Windows Performance Toolkit”复选框。安装的典型文件路径是 C_:\Program Files (x86)\Windows Kits\10\Windows Performance Toolkit\_。在该文件夹中有一个需要编辑的 `perfcore.ini` 文件,以启用视频 GPU 段使用率选项卡,这是进行视频内存分析所必需的。`Perfcore.ini` 包含一个 `.dll` 文件列表,其中需要添加 `perf_dx.dll`。
默认情况下,安装包中包含一个用于触发捕获的 `log.cmd` 脚本。启动后,将捕获整个机器的活动,因此包含所有进程。运行此脚本需要管理员权限。作为示例,典型步骤如下:
分析会产生大量数据,因此为了应对大小问题,最好将 WPA 安装在 SSD 上(因为输出文件夹也是 SSD)。另外,最好处理小于 1GB 的 `Merged.etl` 文件,方法是限制捕获时间。可以使用 WPA 或 GPUView(或同时使用两者)打开 `Merged.etl` 文件进行分析。
WPA 是与 `.etl` 文件扩展名关联的默认应用程序,因此要打开 `Merged.etl` 捕获文件,只需在文件浏览器中双击它们即可。捕获文件加载完成后,WPA 窗口的左侧应有一个“Graph Explorer”选项卡,其中包含图表类别。如果 `Perfcore.ini` 设置正确,在“Video”下拉菜单下将有一个“GPU Segment Usage”图表。要打开它,双击它,应会打开一个“Analysis”窗口,该窗口可以最大化。
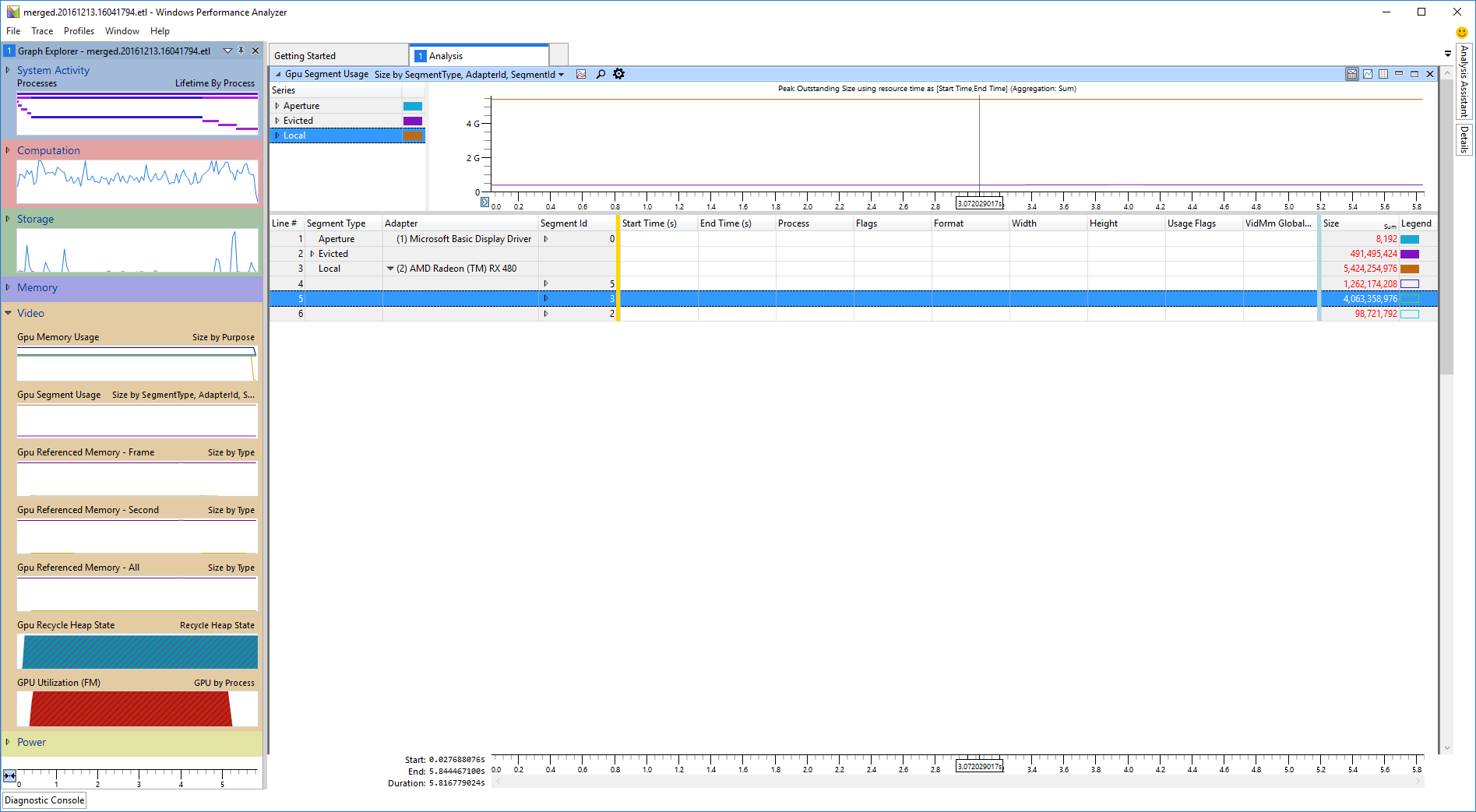
图表下方是一个包含视频分配的表。每个表行对应一个视频分配或一个用于分组分配的下拉菜单。每个表列对应一个分配属性。列被分成由彩色表线分隔的区域。
在黄线左侧,是分配分组的属性,分组顺序从左到右。默认情况下,分配首先按“Segment Type”分组,然后按“Adapter”,最后按“Segment Id”。
在蓝线右侧是“size”和“legend color”列。“size”列显示分配行的单个分配大小,以及下拉菜单行中所有分配的总和。“legend”列在实心框中显示给定分组的关联图表颜色。如果仅显示框的轮廓,则表示该特定分组未在图表中绘制。单击“legend”列下的彩色框可切换各个分组的图表可见性。
在黄线和蓝线之间是常规数据列,显示单个分配的属性。这些列不显示分配分组的信息。
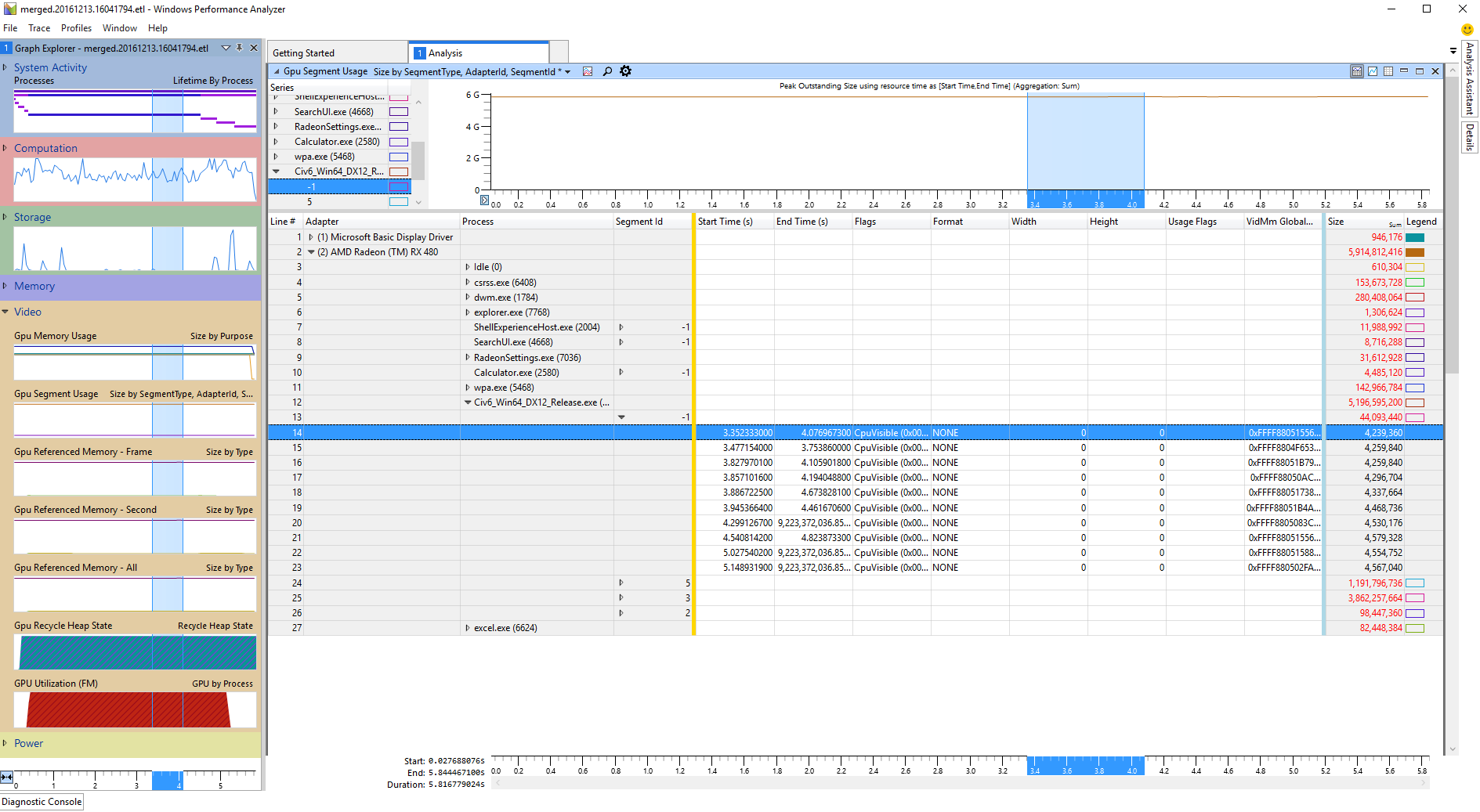
默认分组效果不佳,但很容易更改。通常,更有用的分组是先按“Adapter”分组,然后按“Segment Type”,最后按“Process”。这可以通过用鼠标拖动列到正确的位置来完成。可以通过右键单击表头并取消选中相应的框来删除“Segment Type”列。
由于分组易于重新配置,因此在分析时经常进行此操作,以便轻松导航表格。另一个有用的技巧是“Filter To Selection”(过滤到所选内容):例如,如果发现配置文件之外的进程对 GPU 段使用率的贡献微不足道,则可以将分组更改为“Adapter”、“Process”和“Segment ID”,展开所需适配器的“Adapter”选项卡,然后右键单击目标进程并选择“Filter To Selection”。这将隐藏与该特定适配器和进程无关的所有分配。
配置完分组后,通常需要设置“Legend”选项卡以显示有意义的图表。
对于 AMD,有三个 GPU 段:
此外,WPA 在段 ID -1 下列出了已驱逐的资源。资源被驱逐的原因之一是当它们需要驻留在特定段中但这些段中已无空间时。例如,对于某些资源,各种限制可能要求在使用时将其驻留在“Local Visible”中。如果过多的此类资源争夺空间,视频内存管理器将驱逐其中一些以腾出空间。这可能导致抖动模式,因为被驱逐的资源需要移回。在各个段 ID 之间来回复制的资源会表现为应用程序中的卡顿/峰值。
“evicted”(已驱逐)段是唯一可以通过段 ID 识别的段,因为它始终是 -1。实际的 GPU 段不容易与段 ID 匹配,因此使用 WPA 分析 GPU 段使用率的第一步始终是确定配置文件中的哪个段 ID 对应哪个 GPU 段。
在特定时间点(尤其是在使用高峰时)特定段上的所有分配的总大小,是在快速识别段时需要获取的重要信息。但是,“Size”列将显示图表中可见的整个时间间隔(默认为整个配置文件的生命周期)的所有分配的总和,因此该信息对于理解峰值容量无用。图表实际上包含了所需信息,因为它绘制了随时间变化的总体分配大小。因此,首先,对于每个段 ID,切换“Legend”列的颜色,以便一次只绘制单个段,并从图表中检索每个段的大小信息。如果某个段的总容量使用量存在很大差异,那么峰值使用量最能帮助识别该段。
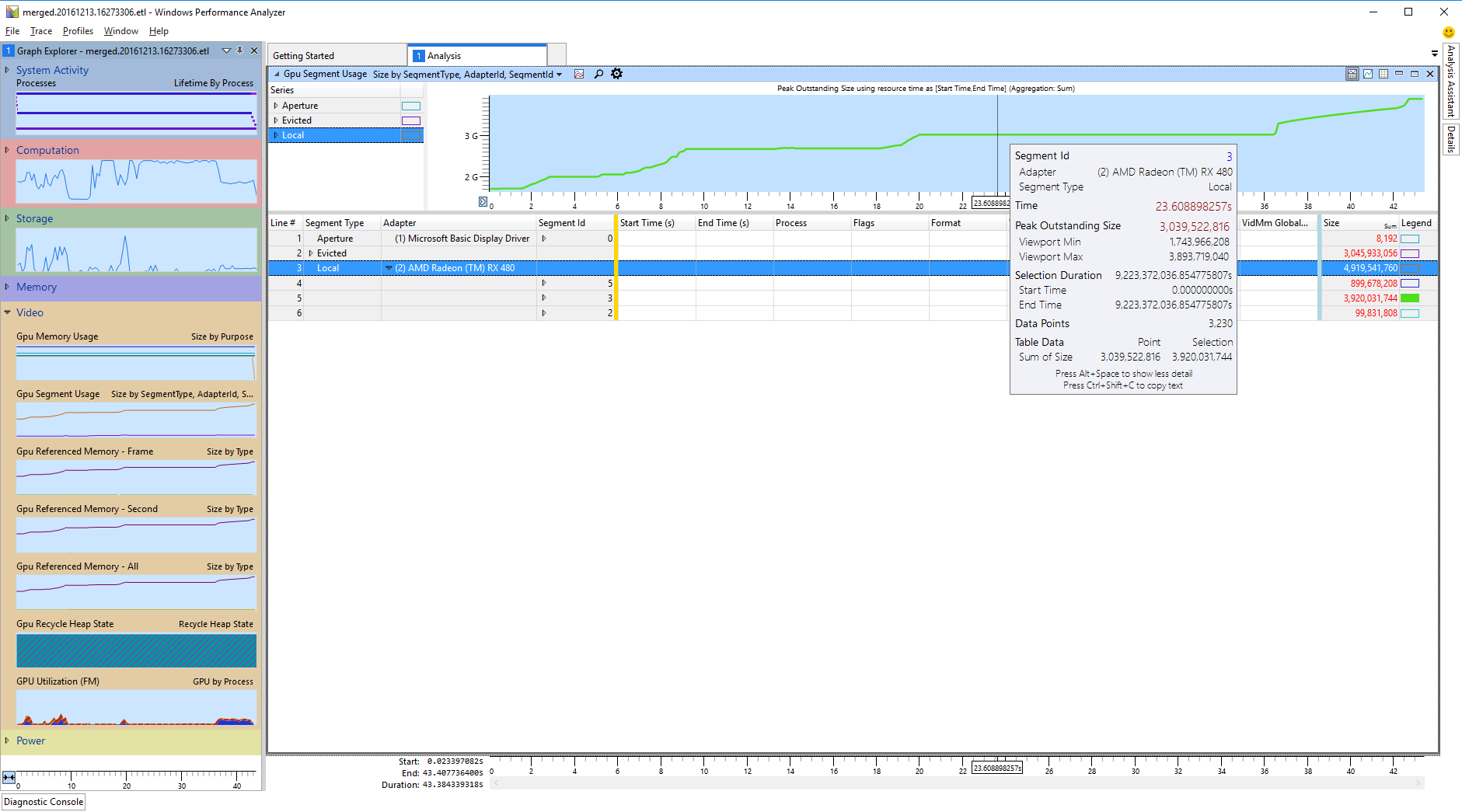
识别段的粗略步骤如下:
一旦确定了段,最显而易见的事情就是确定是否存在过载。Local Visible或Local Invisible中的过载会产生两个负面影响:资源可能最终驻留在次优段中(例如,纹理可能从系统内存而不是本地内存使用,导致性能问题),并且抖动可能导致卡顿和峰值,因为资源在各个段之间来回复制。
要检查由于过载导致的卡顿,请查看“Evicted”(已驱逐)段,并按“Start Time”(开始时间)列对分配进行排序。一些分配在分析开始时可能已经被驱逐,因此表格的前几行应显示 0 作为“Start Time”。所有其他被驱逐的分配都是在分析过程中被驱逐的。评估这些驱逐的大小和频率,以确定它们是否可能成为问题。如果这些驱逐很大或经常发生,请查看其他段,并将“Evicted”段中的“Start Time”与源段中的“End Time”(结束时间)进行匹配,以找出这些资源是从哪里被驱逐出来的。某些资源可能一开始就被驱逐,然后被转移到某个段,这与过载完全无关。这些资源通常在“Evicted”段中停留很短的时间,因此可以通过观察“End Time”和“Start Time”的差值(大约 0.001ms 左右)来识别它们。
要检查资源是否最终驻留在次优段中(例如,首选用于Local Invisible的资源最终驻留在System中),请检查任一本地段的峰值使用率是否接近容量。如果是,对于Local Invisible,确认过载的最简单方法是安装具有比您的应用程序预算更高的 VRAM 的 GPU。例如,如果您担心 4GB Fury X 上的过载问题,请改为在 8GB Radeon RX 480 上进行分析。比较两张卡上“System”和“Local Visible”段的峰值使用率,如果 4GB 卡使用了更多的“System”和//_或_“Local Visible”(并且Local Invisible也接近容量),则意味着 4GB 卡上的Local Invisible过载。如果无法获得更高 VRAM 容量的卡,或者Local Visible接近容量,请比较目标段的图表与其它段,并尝试找出段之间使用率变化的关联(尝试确定目标段中的资源是否被移至其他段或被驱逐)。
最终,检查“System”和“Evicted”段的内容。如果这些段的总使用量很大,这本身就值得关注,因为它暗示着过载、资源泄漏、很少使用的资源或视频内存管理的其他问题。如果很大,则应识别这些段中的资源。
视频内存过载/抖动的常见解决方法是优化应用程序以使用更少的视频内存。要实现这一点,需要能够将视频内存使用量分解为类别进行预算,并且还能够识别 WPA 分配(理解它们与哪些应用程序资源相关联)。
为了识别资源类别,将所有分配导出到电子表格编辑器会很有帮助。要做到这一点,请将所有需要导出的分配分组到 WPA 中的一个下拉菜单下。通常,导出属于某个进程的所有分配很有用,因此在 WPA 中,可以将列配置为只留下“Process”列在黄线左侧。要实际导出,请选择目标进程下的所有分配(Shift+单击),右键单击它们并选择“Copy Selection”(复制所选内容)。然后可以将单元格粘贴到电子表格编辑器中。
要获得资源的良好概览和粗略分类,请创建一个数据透视表,首先按“Height”(高度)分组,然后按“Width”(宽度)分组。让数据透视表计算每个类别中的资源数量,并汇总资源大小。此数据透视表可以按资源大小总和进行排序,以快速显示最重要的资源类别。
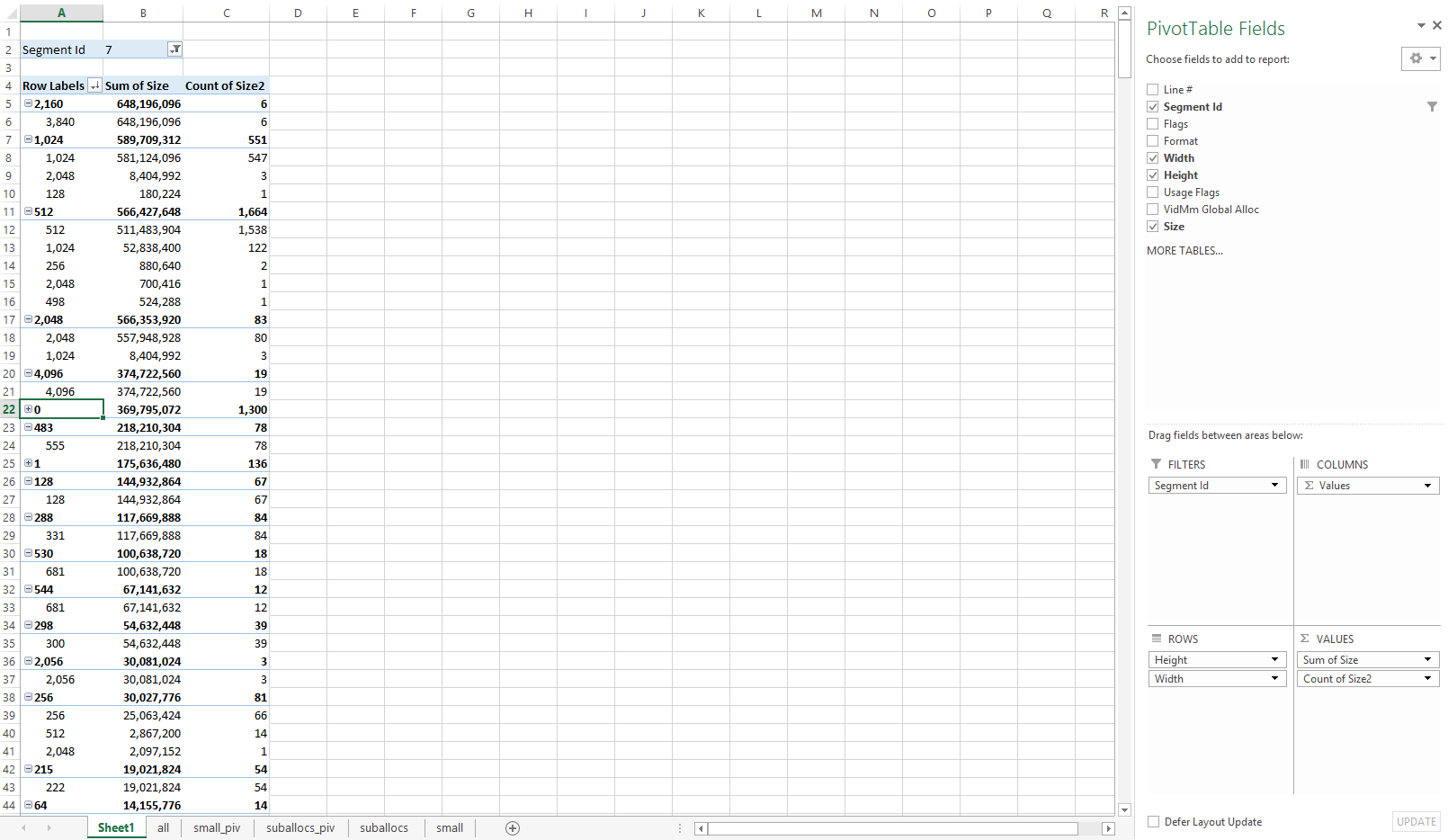
很有可能,最相关的类别是:
为了更好地理解视频内存使用情况,创建额外的数据透视表或使用其他过滤(按段、格式、标志等)很有用。一个有用的例子是创建一个仅包含小型资源的数据透视表。对于 DirectX 11,这些可以是所有小于子分配大小(通常为 32KB)的资源。对于 DirectX 12,可以指定任意大小(或多个大小用于其他数据透视表)。小型资源在 DirectX 11 中总大小应微不足道,因为其中大部分应由驱动程序自动子分配。对于 DirectX 12,由应用程序负责子分配大多数小型资源,因此这是检查分析的分配是否符合预期应用程序行为的好方法。
其他纹理可能会产生填充,非二次幂纹理也可能如此,尤其是在高端显卡上,宽内存总线需要更大的对齐才能实现最大性能——这种额外的填充是典型的独立 GPU 与集成和其他统一内存解决方案之间最大的区别之一,因为后者的总线没有那么宽。要留意分配大小明显大于图像数据的项。电子表格可以设置为计算预期大小并与实际大小进行比较。如果存在大量浪费,减少这种开销的选项包括将小纹理合并到更大的纹理图中,以及调整绑定标志或纹理格式,为驱动程序提供切换到更小填充大小的选项(例如,渲染目标或深度缓冲区比纹理更容易产生填充开销)。纹素尺寸较小的格式通常比纹素尺寸较大的格式需要的填充更少,但 BC 格式除外(4bpp BC 格式等同于 64 位纹素,8bpp BC 格式等同于 128 位纹素)。
WPA 有许多功能和用例,这可能使该工具难以入手。本文提供了一个更易于理解的入门介绍,让读者能够在此基础上进一步自行探索。我希望这能增进对硬件和驱动程序模型的理解,并希望开发人员能充分利用这些知识来提供高性能图形。