
Vulkan® 内存分配器
VMA 是我们单文件头、MIT 许可的 C++ 库,用于轻松高效地为您的 Vulkan® 游戏和应用程序管理内存分配。
Vulkan® 的障碍物系统很独特,它不仅要求您提供正在转换的资源,还需要指定源和目标管线阶段。这允许对转换执行时间进行更精细地控制。然而,如果您只使用简单的方法,可能会浪费大量性能,因此今天我们将详细探讨 vkCmdPipelineBarrier。
众所周知,GPU 是一个高度管线的设备。命令从*顶部*进入,然后顶点和片段着色等各个阶段按顺序执行。最后,当执行完成时,命令在管线的*底部*完成。
这在 Vulkan® 中通过 VK_PIPELINE_STAGE 枚举来暴露,该枚举定义为:
TOP_OF_PIPE_BIT
DRAW_INDIRECT_BIT
VERTEX_INPUT_BIT
VERTEX_SHADER_BIT
TESSELLATION_CONTROL_SHADER_BIT
TESSELLATION_EVALUATION_SHADER_BIT
GEOMETRY_SHADER_BIT
FRAGMENT_SHADER_BIT
EARLY_FRAGMENT_TESTS_BIT
LATE_FRAGMENT_TESTS_BIT
COLOR_ATTACHMENT_OUTPUT_BIT
TRANSFER_BIT
COMPUTE_SHADER_BIT
BOTTOM_OF_PIPE_BIT
请注意,此枚举不一定代表命令的执行顺序——有些阶段可能会合并,有些阶段可能会缺失,但总的来说,这些是命令将要经历的管线阶段。
还有三个伪阶段,它们结合了多个阶段或处理特殊访问:
HOST_BIT
ALL_GRAPHICS_BIT
ALL_COMMANDS_BIT
出于本文的考虑,我们将讨论 TOP_OF_PIPE_BIT 和 BOTTOM_OF_PIPE_BIT 之间的列表。那么,在障碍物的上下文中,*源*和*目标*是什么意思?您可以将其视为“生产者”和“消费者”阶段——源是生产者,目标阶段是消费者。通过指定源和目标阶段,您告诉驱动程序在转换可以执行之前需要完成哪些操作,以及哪些操作必须尚未开始。
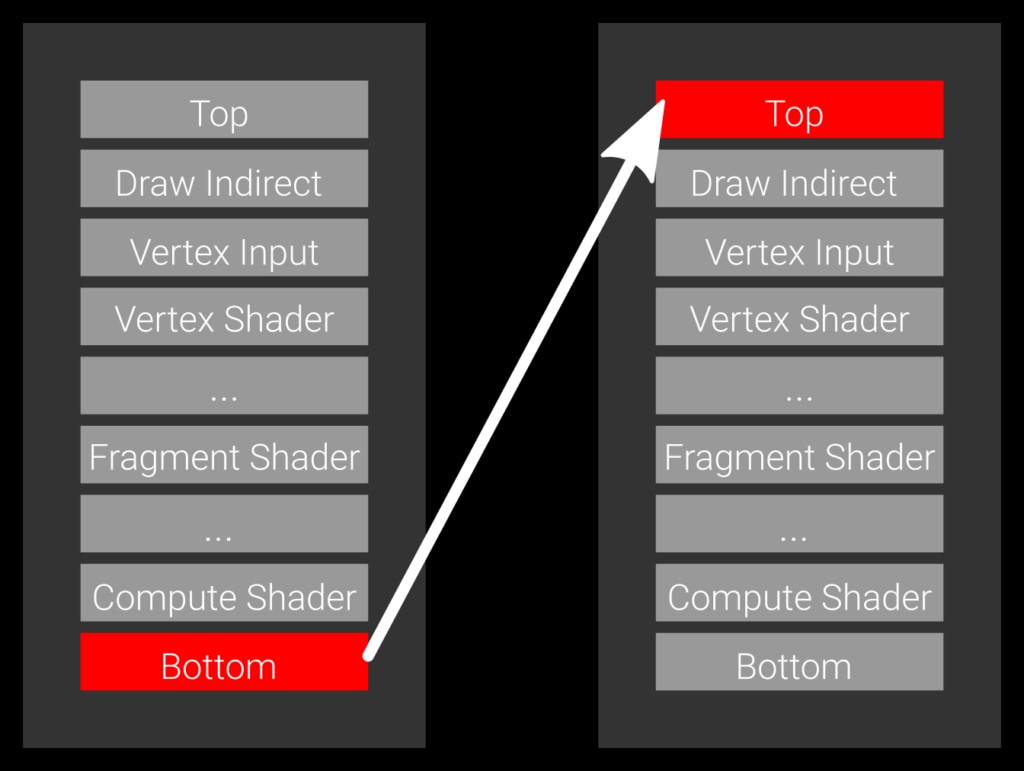
示例 1:一个慢速障碍物,将管线底部指定为源阶段,将管线顶部指定为目标阶段。
我们先来看最简单的情况,即一个障碍物,将 BOTTOM_OF_PIPE_BIT 指定为源阶段,将 TOP_OF_PIPE_BIT 指定为目标阶段(示例 1)。此代码的源代码大致如下:
vkCmdPipelineBarrier( commandBuffer, VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT, // source stage VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, // destination stage /* remaining parameters omitted */);此转换表示 GPU 上当前处于活动状态的所有命令都需要完成,然后执行转换,并且在转换完成之前,任何命令都不能开始。此障碍物将等待所有操作完成并阻止任何后续工作启动。这通常不是理想的,因为它引入了不必要的管线气泡。
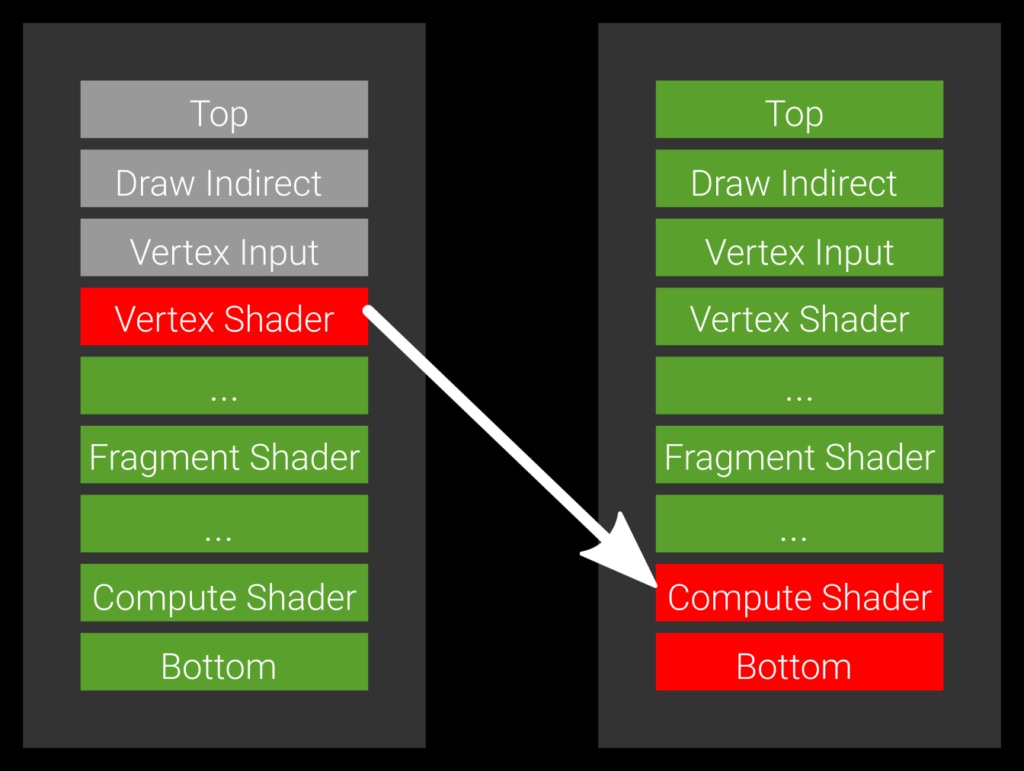
示例 2:允许所有绿色管线阶段执行的最优障碍物。
想象一下您有一个顶点着色器,它还通过 imageStore 存储数据,并且一个计算着色器想要使用它。在这种情况下,您不希望等待后续的片段着色器完成,因为这可能需要很长时间。您真的希望计算着色器一旦顶点着色器完成就尽快开始。表达此目的的方法是将源阶段(生产者)设置为 VERTEX_SHADER_BIT,并将目标阶段(消费者)设置为 COMPUTE_SHADER_BIT(示例 2)。
vkCmdPipelineBarrier( commandBuffer, VK_PIPELINE_VERTEX_SHADER_BIT, // source stage VK_PIPELINE_COMPUTE_SHADER_BIT, // destination stage /* remaining parameters omitted */);如果您写入渲染目标并在片段着色器中读取它,那么阶段将是 VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT 作为源,VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT 作为目标——这对于 G-Buffer 渲染来说很典型。对于阴影贴图,源将是 VK_PIPELINE_STAGE_LATE_FRAGMENT_TESTS_BIT。另一个典型的例子是复制数据——您通过复制产生数据,因此源阶段将设置为 VK_PIPELINE_STAGE_TRANSFER_BIT,目标设置为您需要它的阶段。对于顶点缓冲区,这将是例如 VK_PIPELINE_STAGE_VERTEX_INPUT_BIT。
总的来说,您应该尽量最大化“未阻塞”阶段的数量,即早期生成数据,晚期等待使用。从生产者方面来看,向管线底部移动总是安全的,因为您将等待越来越多的阶段完成,但这不会提高性能。同样,如果您想在目标方面感到安全,您会向上移动到管线顶部——但这会阻止更多阶段运行,因此也应该避免。
最后一点说明:如前所述,硬件可能不具备所有内部阶段,或者可能无法在指定的阶段进行信号或等待。在这些情况下,驱动程序可以自由地将您的源阶段移至管线底部,将目标阶段移至管线顶部。但这取决于实现,您不必为此担心——您的目标应该是尽可能“紧密”地设置阶段,并最小化被阻塞的阶段数量。
















