AMD FidelityFX™ Single Pass Downsampler (SPD)
AMD FidelityFX Single Pass Downsampler (SPD) 提供了一个 AMD RDNA™ 架构优化的解决方案,用于生成纹理的最多 12 个 MIP 级别。
我们最新的 RDNA™ 3 GPU 提供了加速通用矩阵乘法 (GEMM) 操作的能力。这意味着您现在可以获得硬件加速的矩阵乘法,充分利用我们新的 RDNA 3 架构。这项新功能名为 **Wave Matrix Multiply Accumulate (WMMA)**。
本博文是一个简短的指南,介绍如何通过一个“Hello World”示例,在 RDNA 3 GPU 架构上使用 WMMA 功能。它展示了如何在 HIP 中将 WMMA 作为编译器内置函数使用。作为先决条件,我们建议阅读 **RDNA 3 ISA 指南** 的 1.1 节的表 2,以了解所用各种术语的概述。在直接查看源代码示例之前,也建议您详细了解 WMMA 的工作原理。作为本博文的补充,您还可以参考 **AMD Matrix Instruction Calculator** 工具,以生成深入的信息,例如每个可用 WMMA 指令的寄存器映射。
基于 RDNA 3 架构的 AMD GPU 可以非常高效地执行 WMMA 指令,从而使应用程序能够实现出色的性能和利用率。单个 WMMA 指令协调 32 个时钟周期的最佳工作调度。AMD 公司研究员兼首席 GPU 架构师 Mike Mantor 如此解释:
WMMA 指令通过提供源数据重用和中间目标数据转发操作而不中断,来优化数据移动和峰值数学运算的调度,从而最大限度地减少 VGPR 访问。矩阵运算中遇到的规则模式使 WMMA 指令能够降低所需功耗,同时提供最佳运算,从而实现持续在峰值速率或非常接近峰值速率的运行。
WMMA 支持 FP16 或 BF16 输入,这些对于在线或离线训练可能很有用,同时也支持适合推理的 8 位和 4 位整数数据类型。下表比较了基于 RDNA 3 架构的我们旗舰级 Radeon RX 7900 XTX GPU 与基于 RDNA 2 的前代旗舰级 Radeon RX 6950 XT GPU 在不同数据类型下的理论 FLOPS/clock/CU(每时钟周期每计算单元的浮点运算数)。
(IU8 和 IU4 分别指无符号 8 位整数数据类型和无符号 4 位整数数据类型)
| 数据类型 | RX 6950 XT FLOPS/clock/CU | RX 7900 XTX FLOPS/clock/CU |
|---|---|---|
| FP16 | 256 | 512 |
| BF16 | 不适用 | 512 |
| IU8 | 512 | 512 |
| IU4 | 1024 | 1024 |
与传统的每个线程的矩阵乘法不同,WMMA 允许 GPU 在 wave32 模式下的整个波形(32 个线程)或 wave64 模式下的整个波形(64 个线程)上协同执行矩阵乘法。这提供了在波形通道之间共享输入/输出矩阵数据的优势,从而优化了 VGPR 使用并减少了内存流量。
假设我们使用矩阵 A、B、C 和 D 进行 GEMM 操作:
D = A*B + C
其中 A 和 B 是输入矩阵,C 是累加器矩阵,D 是目标矩阵,也称为结果矩阵。
如果 C 不使用(例如,在神经网络中不使用偏置时),您可以将 C 初始化为 0 并将其重新用作结果矩阵。
C = A*B + C
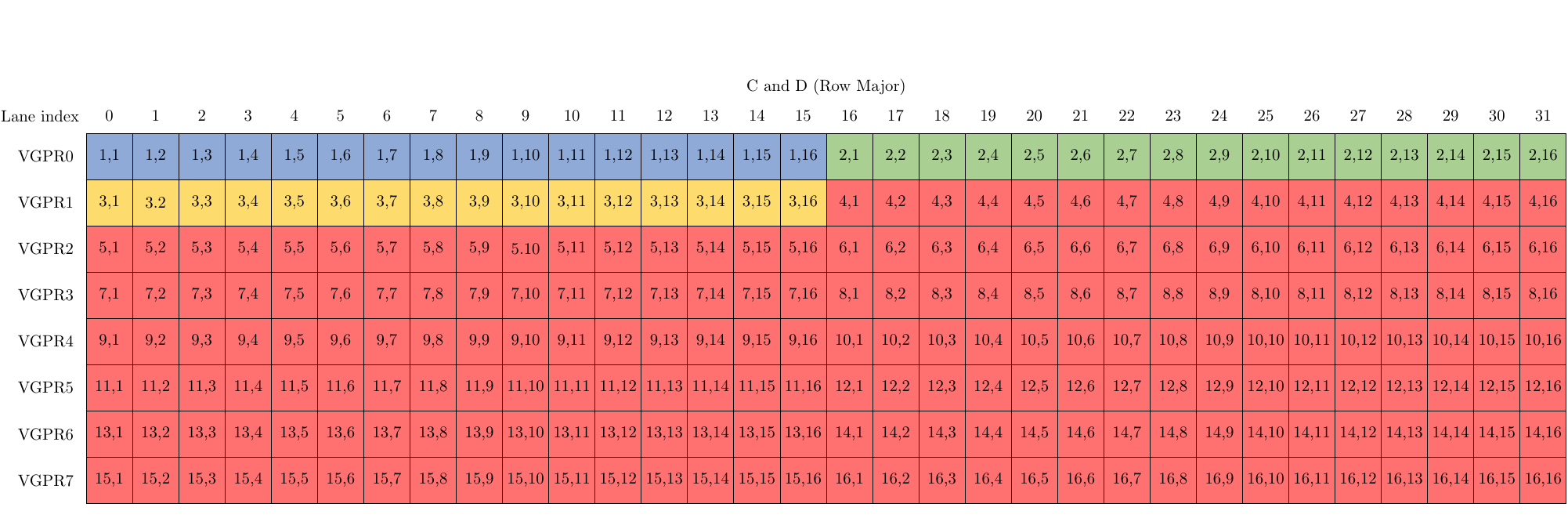
下图说明了这一点,其中矩阵 A、B、C 和 D 都使用 16x16 的块大小。

截至撰写本文时,您可以使用 WMMA 的三种方式是:通过 LLVM clang 内置函数中的编译器内置函数,或者自己编写内联汇编,或者您也可以使用 rocWMMA,它允许开发者访问基于 WMMA 的矩阵运算(有关更多详细信息,请参阅本博文结尾)。本博文将重点介绍编译器内置函数方法。
WMMA 编译器内置函数遵循以下定义的特定语法:
D_frag = __builtin_amdgcn_wmma_<C, D format>_16x16x16_<A, B format>_w<32 or 64>(A_frag, B_frag, C_frag, OPSEL)
如果您想将 D 重用为 C(其中 C 已初始化为零),只需将 D 替换为 C 即可:
C_frag = __builtin_amdgcn_wmma_<C, D format>_16x16x16_<A, B format>_w<32 or 64>(A_frag, B_frag, C_frag, OPSEL)
其中,“C, D format”分别指矩阵 C 和 D 的格式,对于浮点数据类型可以是 f16、f32 或 bf16,对于整数数据类型可以是 i32。
“A,B format”分别指输入矩阵 A 和 B 的格式,可以是 f16、bf16、iu8 或 iu4。
16x16x16 代表 GEMM 约定,表示 MxNxK 矩阵乘法的块大小,其中矩阵 A 的大小为 MxK,矩阵 B 的大小为 KxN,矩阵 C/D 的大小为 MxN。在 RDNA 3 中,仅支持 16x16 的块大小。如果您的矩阵大于 16x16,则将其分割成 16x16 的块,然后可以将其传递给 WMMA 指令。在波形上下文中,WMMA 指令内部会为矩阵 A 获取一个 16x16 的块,为矩阵 B 获取一个 16x16 的块。然后将它们相乘得到一个 16x16 的块,然后将其与矩阵 C 相加得到最终的 16x16 的矩阵 D 块。
内置函数中的 w<32 or 64> 描述了 WMMA 是以 wave32 模式还是 wave64 模式运行。根据模式的不同,矩阵的加载和存储行为可能会有所不同。我们将在本博文稍后部分介绍这些差异。
最后一个参数“OPSEL”也将在本博文稍后介绍。目前,让我们关注这些矩阵片段(A_frag、B_frag、C_frag 和 D_frag)是如何加载和使用的。
参数 A_frag、B_frag、C_frag 和 D_frag 是矩阵片段,分别包含矩阵 A、B、C 和 D 的 16 个元素。从波形中单个通道(线程)的角度来看,每个“片段”都本地存储在 VGPR 中,每个 VGPR 宽度为 32 位。无论波形大小如何,每个线程都持有 fp16/bf16 的 A_frag 和 B_frag(使用 8 个 VGPR),iu8 的(使用 4 个 VGPR),以及 iu4 的(使用 2 个 VGPR)。
C_frag 和 D_frag 在 wave32 模式下需要 8 个 VGPR,在 wave64 模式下需要 4 个 VGPR,无论矩阵 C 和 D 使用什么数据类型。
需要注意的是,RDNA 3 上的 WMMA 要求 A_frag 和 B_frag 的内容在 wave32 模式下复制到波形的通道 0-15 和通道 16-31 之间。这意味着,对于 wave32 模式,通道 0 中的每个 VGPR 必须与通道 16 中的每个 VGPR 具有完全相同的矩阵数据。通道 1 类似于通道 17,依此类推,直到通道 15 类似于通道 31。这有效地在两个半波形之间维护了两个矩阵数据的副本。在 wave64 模式下,通道 0-15 的数据也必须复制到通道 32-47 和 48-63。
目前有 12 个遵循上述语法的 WMMA 内置函数。它们大致分为两类:wave32 和 wave64,如下所述:
| wave32 | wave64 | 矩阵 A,B 格式 | 矩阵 C,D 格式 |
|---|---|---|---|
__builtin_amdgcn_wmma_f32_16x16x16_f16_w32 | __builtin_amdgcn_wmma_f32_16x16x16_f16_w64 | FP16 | FP32 |
__builtin_amdgcn_wmma_f32_16x16x16_bf16_w32 | __builtin_amdgcn_wmma_f32_16x16x16_bf16_w64 | BF16 | FP32 |
__builtin_amdgcn_wmma_f16_16x16x16_f16_w32 | __builtin_amdgcn_wmma_f16_16x16x16_f16_w64 | FP16 | FP16 |
__builtin_amdgcn_wmma_bf16_16x16x16_bf16_w32 | __builtin_amdgcn_wmma_bf16_16x16x16_bf16_w64 | BF16 | BF16 |
__builtin_amdgcn_wmma_i32_16x16x16_iu8_w32 | __builtin_amdgcn_wmma_i32_16x16x16_iu8_w64 | IU8 | I32 |
__builtin_amdgcn_wmma_i32_16x16x16_iu4_w32 | __builtin_amdgcn_wmma_i32_16x16x16_iu4_w64 | IU4 | I32 |
最后,“OPSEL”参数是在使用 16 位格式的 C 和 D 矩阵时需要指定的布尔标志。如果此标志设置为 true,则 C 和 D 的元素存储在 VGPR 的上半部分。然而,当此标志设置为 false 时,它们存储在 VGPR 的下半部分。如果您偏好 0 索引,请将此标志设置为 false。这在我们下面的“Hello World”示例代码片段中得到了说明,其中我们将 C_frag 中的 16 位元素存储到矩阵 C 中。
OPSEL 伪代码
// call the WMMA intrinsic with OPSEL set to "false"c_frag = __builtin_amdgcn_wmma_f16_16x16x16_f16_w32(a_frag, b_frag, c_frag, false);// 8 VGPRs per C,D fragment per thread in wave32 modeconst int lane = threadIdx.x % 16;
for (int ele = 0; ele < 8; ++ele){ // index into matrix C const int r = ele * 2 + (lIdx / 16); // store results from unpacked c_frag output c[16 * r + lane] = c_frag[ele*2];}注意当 OPSEL 设置为“false”时,存储矩阵 C 元素从 C_frag 的那一行。
OPSEL=“false”
c[16 * r + lane] = c_frag[ele*2];如果 OPSEL 设置为“true”,则上面的那一行将是:
OPSEL=“true”
c[16 * r + lane] = c_frag[ele*2 + 1];请注意,在此特定示例中,我们选择矩阵 C 始终以打包格式存储 C_frag 元素,因此 OPSEL 标志仅影响此表达式右侧的索引。您可以根据您的应用程序需求自由修改它以存储在非打包格式中。
WMMA 需要矩阵 A、B、C 和 D 的行主序和列主序输入的组合。矩阵 A 以列主序存储,而矩阵 B、C 和 D 都以行主序存储。矩阵 A 和 B 以打包格式存储(即每个 VGPR 打包 2 个 fp16 值、4 个 iu8 值或 8 个 iu4 值),而矩阵 C 和 D 以非打包格式存储,“OPSEL”参数用于描述 VGPR 内的存储位置,下面将进一步说明。
w32 或 w64 分别代表 wave32 或 wave64。它代表将参与 16x16x16 GEMM 操作的线程数。
在此,我们将演示如何使用 __builtin_amdgcn_wmma_f16_16x16x16_f16_w32 在 wave32 模式下执行具有 fp16 输入和输出的 16x16x16 GEMM。
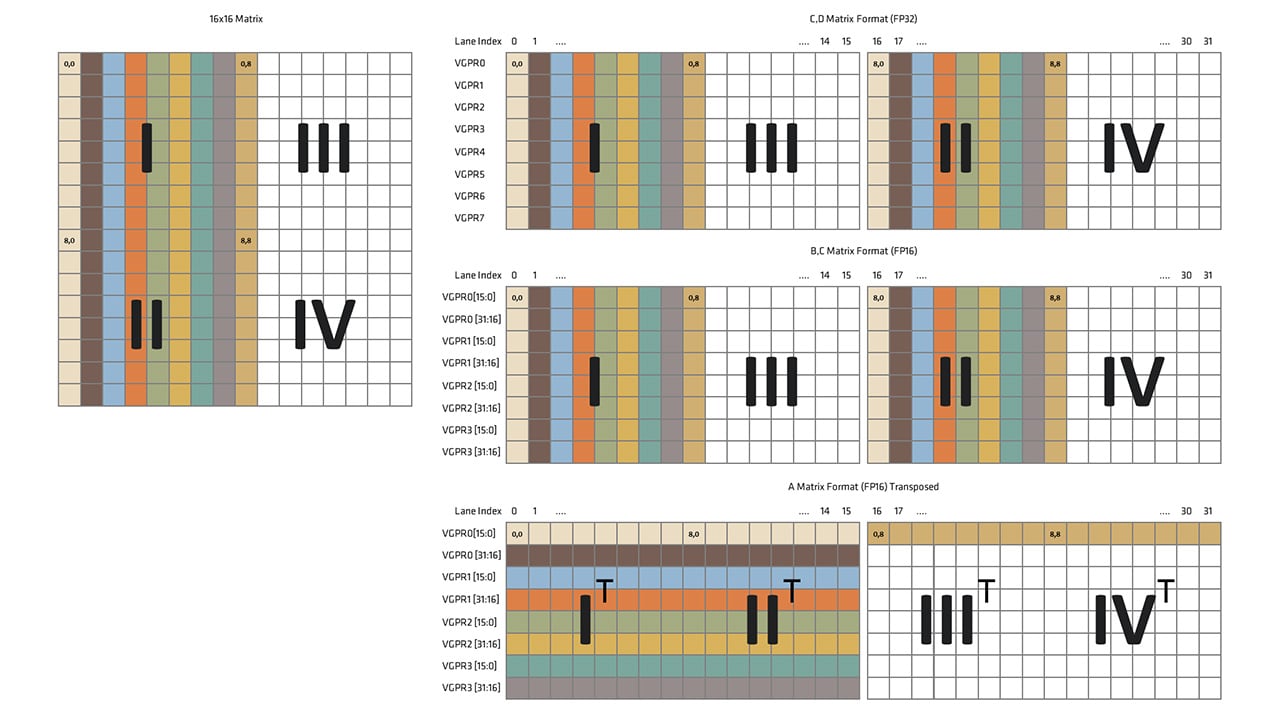
下图显示了矩阵 A 和 B 的输入矩阵布局。对于矩阵 A,单元格中的 (i, j) 代表第 i 行和第 j 列。对于矩阵 B,单元格中的 (i, j) 代表第 i 列和第 j 行。
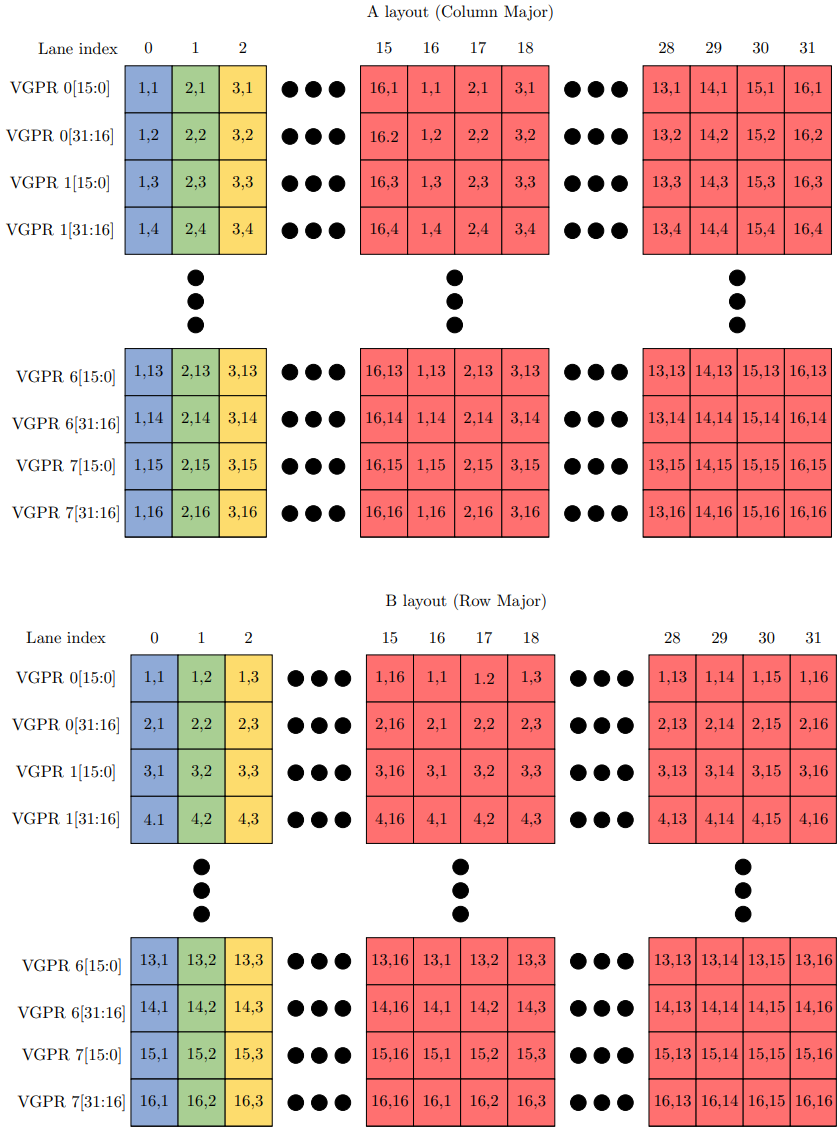
从线程的角度来看,每个 VGPR 保存两个打包的 fp16 元素,每组 8 个 VGPR 分别保存矩阵 A 和 B 的 16 个元素。矩阵 A 在 VGPR 中保存 16 列,而矩阵 B 在 VGPR 中保存 16 行。
注意表示矩阵 A 的 3 行以及矩阵 B 的 3 列的蓝色、绿色和黄色单元格。这些将映射到下图,该图显示了矩阵 C 和 D 的布局。另请注意,这里的 8 个 VGPR/通道将以非打包格式存储 C 和 D 的元素,其中 16 位元素根据“OPSEL”标志存储在 32 位 VGPR 的上半部分或下半部分。在我们的例子中,OPSEL 设置为 0 (False),因此每个 VGPR 在 VGPR 的下半部分(位 0 到 15)中包含一个矩阵元素。请注意,如前所述,矩阵 C 和 D 以行主序格式存储。
以下是一个代码示例,其中包含一些有用的注释,展示了如何执行两个 f16 矩阵 A 和 B 的矩阵乘法,并将 C 重用为 GEMM 操作 C = AB + C 的 D,在 wave32 模式下使用 __builtin_amdgcn_wmma_f16_16x16x16_f16_w32。
wmma_test.cpp
WMMA 示例
// Wave Matrix Multiply Accumulate (WMMA) using HIP compiler intrinsic// Does a matrix multiplication of two 16x16, fp16 matrices, and stores them into a 16x16 fp16 result matrix
#include <iostream>#include <hip/hip_runtime.h>#include <hip/hip_fp16.h>
using namespace std;
// Use half16 as an alias of the internal clang vector type of 16 fp16 valuestypedef _Float16 half16 __attribute__((ext_vector_type(16)));
__global__ void wmma_matmul(__half* a, __half* b, __half* c){ const int gIdx = blockIdx.x * blockDim.x + threadIdx.x; const int lIdx = threadIdx.x;
// a and b fragments are stored in 8 VGPRs each, in packed format, so 16 elements each for a and b // a_frag will store one column of the 16x16 matrix A tile // b_frag will store one row of the 16x16 matrix B tile half16 a_frag; half16 b_frag; // initialize c fragment to 0 half16 c_frag = {};
// lane is (0-31) mod 16 instead of 0-31 due to matrix replication in RDNA 3 const int lane = lIdx % 16;
for (int ele = 0; ele < 16; ++ele) { b_frag[ele] = b[16*ele + lane]; }
for (int ele = 0; ele < 16; ++ele) { a_frag[ele] = a[16 * lane + ele]; }
// call the WMMA intrinsic with OPSEL set to "false" c_frag = __builtin_amdgcn_wmma_f16_16x16x16_f16_w32(a_frag, b_frag, c_frag, false);
for (int ele = 0; ele < 8; ++ele) { const int r = ele * 2 + (lIdx / 16); // store results from unpacked c_frag output c[16 * r + lane] = c_frag[ele*2]; // if OPSEL was set to "true", the line above would instead be // c[16 * r + lane] = c_frag[ele*2 + 1]; }
}
int main(int argc, char* argv[])
{ __half a[16 * 16] = {}; __half b[16 * 16] = {}; __half c[16 * 16] = {}; __half *a_gpu, *b_gpu, *c_gpu; hipMalloc(&a_gpu, 16*16 * sizeof(__half)); hipMalloc(&b_gpu, 16*16 * sizeof(__half)); hipMalloc(&c_gpu, 16*16 * sizeof(__half));
// fill in some data into matrices A and B for (int i = 0; i < 16; ++i) { for (int j = 0; j < 16; ++j) { a[i * 16 + j] = (__half)1.f; b[i * 16 + j] = (__half)1.f; } }
hipMemcpy(a_gpu, a, (16*16) * sizeof(__half), hipMemcpyHostToDevice); hipMemcpy(b_gpu, b, (16*16) * sizeof(__half), hipMemcpyHostToDevice); hipMemcpy(c_gpu, c, (16*16) * sizeof(__half), hipMemcpyHostToDevice);
wmma_matmul<<<dim3(1), dim3(32, 1, 1), 0, 0>>>(a_gpu, b_gpu, c_gpu);
hipMemcpy(c, c_gpu, (16 * 16) * sizeof(__half), hipMemcpyDeviceToHost);
hipFree(a_gpu); hipFree(b_gpu); hipFree(c_gpu);
for (int i = 0; i < 16; ++i) { for (int j = 0; j < 16; ++j) { printf("%f ", (float)c[i * 16 + j]); } printf("\\n"); }
return 0;}上述代码中的过程如下:
初始化输入矩阵 A 和 B。
将矩阵 C 设置为零并将其重用为矩阵 D。
将矩阵 C 传递给“wmma_matmul”内核,该内核将矩阵元素加载到各自的片段中。
调用 WMMA 内置函数。
将结果从 c_frag 存储回矩阵 C。
要在 Linux 或 Windows 上使用 HIP 编译上述程序,在您的 Radeon RX 7900 XTX 或 7900 XT GPU 上,只需使用 hipcc --offload-arch=gfx1100 wmma_test.cpp -o wmma_test。请确保您的 Linux 环境已安装 ROCm v5.4 或更高版本,或者您的 Windows® 环境已安装最新的 HIP SDK。
作为安装 HIP SDK 的替代方案,请访问 Orochi GitHub 仓库,其中包含一个涉及在 Windows® 或 Linux 上运行时使用 hipRTC API 编译和运行上述代码的示例!
顺便说一句,如果您习惯使用 nvcuda::wmma API 和/或 rocWMMA,您会注意到许多相似之处。例如,a_frag、b_frag、c_frag 和 d_frag 中的这些矩阵片段可以被视为与这些 API 中可用的模板化片段类型相同,片段的加载和存储类似于 load_matrix_sync 和 store_matrix_sync。调用编译器内置函数类似于调用 mma_sync。主要区别在于您自己进行加载、存储、同步和 WMMA 调用,而不是依赖 API 来为您完成。为简洁起见,我们省略了同步部分,因为对于上面这样的简单示例,它不是必需的。但是,我们建议在适当的地方使用 __syncthreads()。
WMMA 可用于加速任何涉及矩阵乘法的用例。此处我们描述三个可用或即将推出的用例:
Stable Diffusion 使用 WMMA 通过 SHARK MLIR/IREE 运行时为 RDNA 3 GPU 提升性能。
AMD 的 Composable Kernels (CK) 库 将很快在新版本中更新以支持 WMMA,这将使 Meta 的 AI Template (AIT) 库能够在 RDNA 3 上为模型推理提供端到端的硬件加速。
Machine Intelligence Shader Autogen (MISA) 库将很快发布 WMMA 支持,以加速 Resnet50 等模型,与 RDNA 2 相比,性能提升约 2 倍。
到目前为止,我们已经讨论了如何通过编译器内置函数使用 WMMA。但是,将其与利用 nvcuda::wmma API(通过 mma.h)的现有 CUDA 应用程序集成可能很麻烦(请注意,nvcuda::wmma 中的 WMMA 指的是 Warp Matrix-Multiply Accumulate,这与此处描述的 Wave Matrix-Multiply Accumulate 不同)。
虽然这些内置函数可以轻松映射到 mma_sync API 调用,但矩阵的加载/存储和同步可能难以处理和调试,尤其是对于新手用户。
RDNA 3 WMMA 支持现已在 **rocWMMA** 中提供。该库可与 nvcuda::wmma 兼容,并支持 MFMA 和 WMMA 指令,从而使您的应用程序能够在 RDNA 3 和 CDNA 1/2 系统上实现硬件加速的 ML。
感谢 Atsushi Yoshimura、Joseph Greathouse 和 Chris Millette 提出改进建议和提供反馈,并感谢 Mike Mantor 提供了富有见地的 WMMA 解释。矩阵布局图由 Damon McDougall 最初编写的修改版 TikZ 程序生成。