AMD FidelityFX™ Variable Shading
AMD FidelityFX Variable Shading 将可变速率着色引入您的游戏。
2024 年 3 月更新,针对 Microsoft® Work Graphs 1.0 的发布:使用此 最新 AMD 驱动程序。
在本文中,我们将练习使用 Microsoft 早期发布的 Workgraph API。如果您不熟悉 Workgraph 的基本语法,GPUOpen 上有一个很棒的介绍,我建议您阅读 GPU 工作图入门。
Workgraph 非常适合表达管道。当您考虑在 GPU 上实现一个算法时,您可能会经常将其视为一个整体程序,尽可能多地在 GPU 工作单元上运行。毕竟,使用当前的语言和 API 将算法分解为多个阶段的收益很小。
无论通过对算法进行分阶段来创造任何工作量减少和整形的机会,都需要比由此带来的劣势更有价值。
Workgraphs API 不仅提供了表达管道和图的语法,它还解决了上述问题。
在本系列的这一部分,我们将选择一个小型示例算法,展示将其分解为阶段所带来的工作量减少和整形机会,以及 Workgraph 如何最大化其中固有的性能。
我们选择用于演示的小型示例算法是扫描线光栅化器。为了保持范围简单,我们选择了一种算法变体,它可以很好地处理近平面交线的边缘情况,并且不需要三角形裁剪器。此外,此示例并非旨在成为工业级的复制粘贴模板,它旨在教授 Workgraph,而许多与 Workgraph 无关的内容(如边缘平局和一些精度不准确或层次 Z 测试)已被忽略:使用 2D 齐次坐标进行三角形扫描转换。
该算法可以简化为以下步骤:
这是一个小型算法(约 100 行代码),可以很好地解决三角形光栅化问题。我们将在后续中简单地将此算法称为光栅化器,当我们说到边界框时,指的是屏幕空间 AABB。
接下来,我们将设计算法,然后深入研究实现细节,最后将看到一些结果。在您自己的项目中,实验和考虑之间会有相当多的往返。但新的 Workgraphs 范例的一个优点是,这样做感觉非常舒适。一旦应用程序和着色器程序之间有了稳定的接口,您就可以主要留在着色器代码中并尝试不同的方法。
让我们一步一步地将光栅化器算法转换为一种适合 GPU 运行并利用 Workgraph 功能的实现。当然,我们将把算法分解成更小的部分,利用在算法阶段之间自由路由数据,并剔除冗余数据。
GPU 目前基本上是一个 SIMD 处理器。SIMD 向量的宽度因实现而异,通常在 16 到 64 个通道之间。
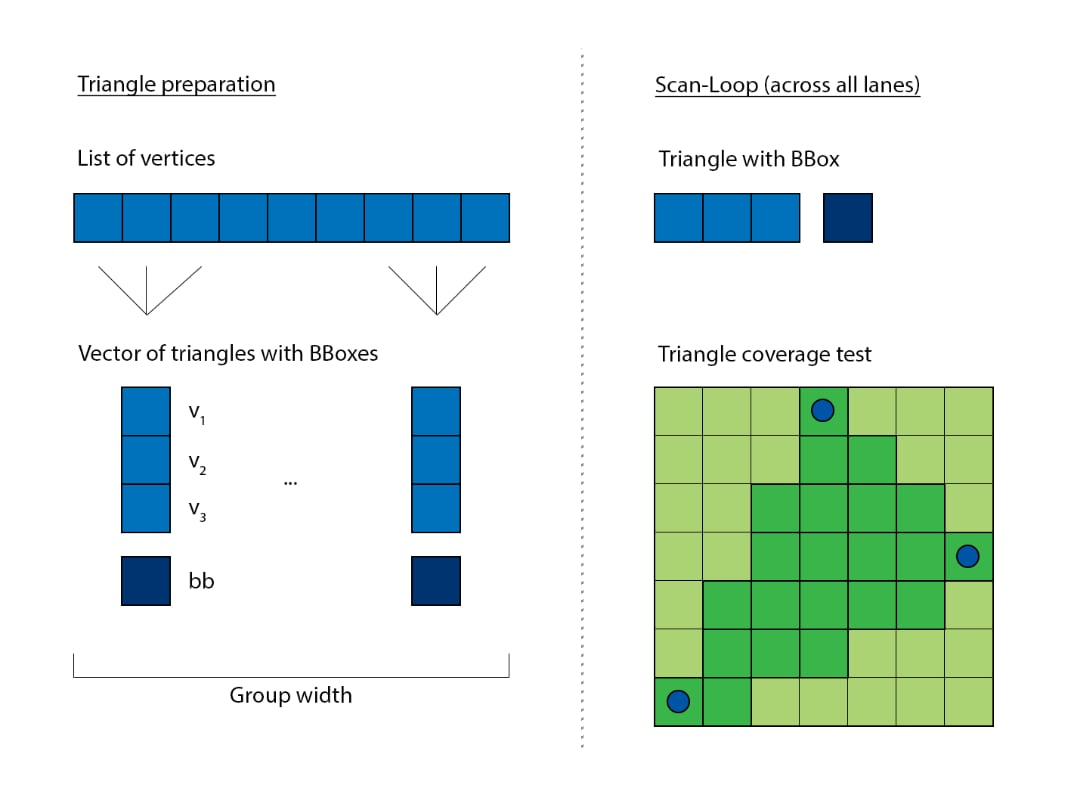
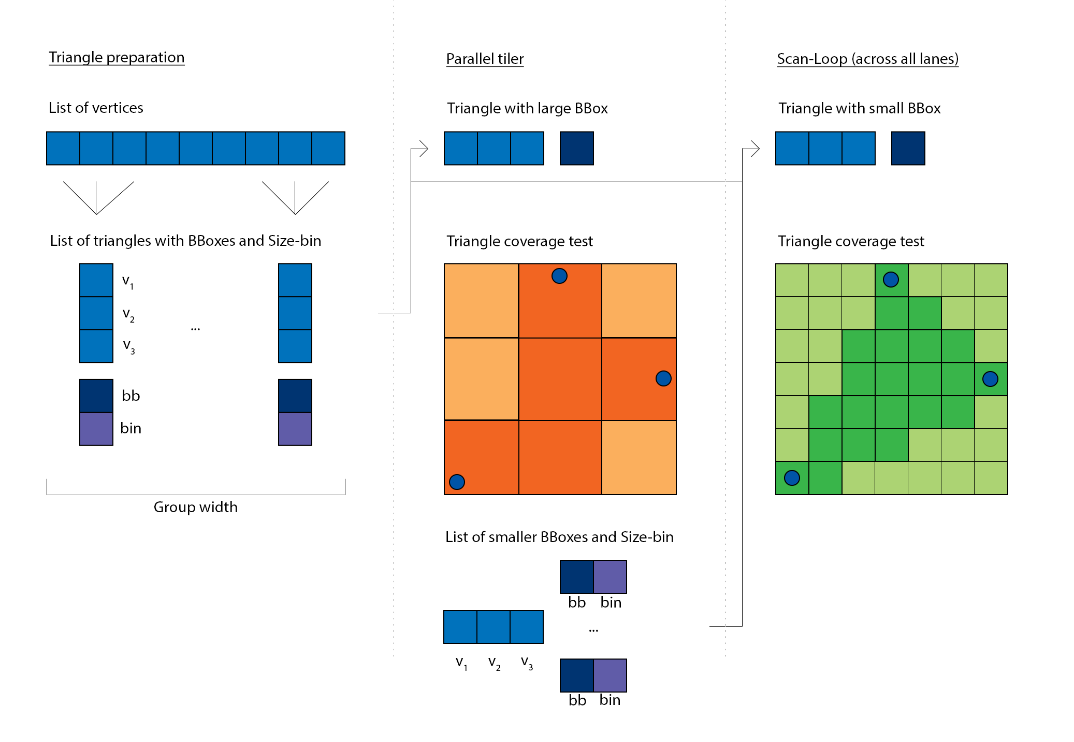
光栅化器可以轻松矢量化。每个通道负责处理不同的三角形。扫描循环需要迭代,只要参与的三角形使用其参数。例如,如果有两个三角形,其边界框分别为 48x6 和 8x92,那么循环需要迭代 48x92 的范围,以便同时覆盖两者。
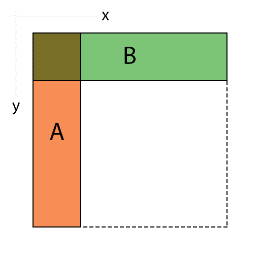
这相当低效,因为几乎所有的面积并集都是空的,对任何一个三角形都没有用。最好将共享循环的维度从 2D 减少到 1D。两个示例三角形的循环参数分别为 288 和 736,这比之前产生的 4140 次迭代要好得多。
float BBStrideX = (BBMax.x - BBMin.x + 1);float BBStrideY = (BBMax.y - BBMin.y + 1);float BBCoverArea = BBStrideY * BBStrideX - 1.0f;
float y = BBMin.y;float x = BBMin.x;
while (BBCoverArea >= 0.0f){ x += 1.0f; y += x > BBMax.x; if (x > BBMax.x) x = BBMin.x;
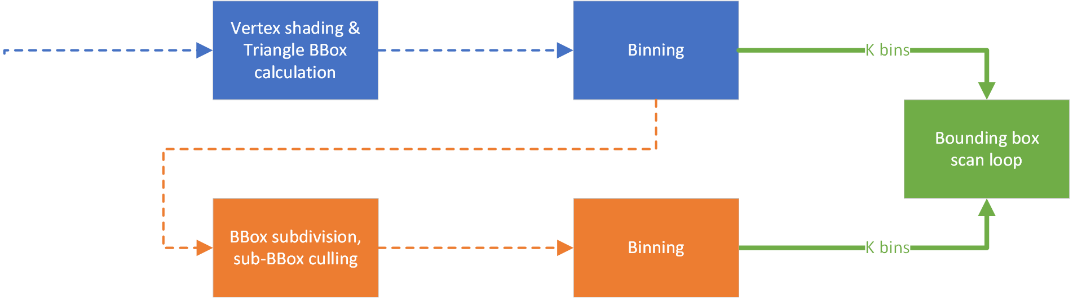
BBCoverArea -= 1.0f;尽管第一步已经是一个很好的改进,但如果我们能进一步改进它那就更好了。我们能否让三角形的面积彼此相似?这将使 SIMD 向量上的共享循环的参与者更加连贯,并且我们不会遇到处理小三角形与大三角形并存的情况。为此,我们将光栅化器分为两个阶段:
在这两个阶段之间,我们现在可以查看所有三角形,按面积对它们进行分组,然后启动具有相似大小三角形的循环。通常,这会在常规的 Compute API 中导致显著的开销(编程和执行),但使用 Workgraphs API,这相当直接,因为我们可以将第一阶段的输出分流到第二阶段的集合中。

仍然存在一个棘手的问题,即三角形的面积可以介于 1 到整个屏幕(对于 4k,约为 800 万)之间。我们不想指定那么多扫描循环的变体。此外,对于真实场景,三角形大小的频率下降得相当快,您很难找到超过几个三角形占据大面积。相反,我们可以将三角形分箱到一组更易于管理的面积属性中。为了通用性,我们不应基于特定的三角形频率,而是选择预期的分布。对数是一个不错的选择,而底为 2 的计算非常快(也许您会发现与信息熵的联系)。
// Calculate rasterization area and binfloat2 BBSize = max(BBMax - BBMin + float2(1.0f, 1.0f), float2(0.0f, 0.0f));float BBArea = BBSize.x * BBSize.y;int BBBin = int(ceil(log2(BBArea)));
为了支持 4k,我们将不得不提供 23 个光栅化循环:22.93 = log2(~8mil.),尽管即使应用了对数,最后几个 bin 中也会有非常少的三角形。此外,为了通用性,我们不会对三角形的大小设置限制。还有一个额外的担忧:在 GPU 这样的并行处理器上运行 800 万次迭代的着色器程序效率极低。我们可以改为将大面积分解为小面积。这听起来很熟悉,硬件光栅化器也是这样做的,它将屏幕空间细分为固定大小的瓦片,如果处理一个大三角形,它会将相同的三角形分发到许多瓦片。它允许硬件以适度的成本并行化三角形光栅化。这个想法为我们带来了三个好处:
当我们在寻找优化机会时,还会出现一个间接的好处,那就是我们不需要光栅化空的边界框。一旦我们将原始三角形的边界框切分成更小的边界框,其中一些较小的边界框现在可能完全位于原始三角形的区域之外。边界框是对三角形的相当差的近似:基本上,边界框面积的一半是空白空间。如果我们的最大可分箱面积相对于输入面积很小,那么我们可以剔除大量不执行任何操作的迭代,这些迭代只是未能符合三角形的内部。
这同样可以通过将细分因子直接传递给 Dispatch 来并行化,就像硬件所做的那样。
现在我们来看第一个 Workgraphs API 特定的优化。您可以使用具有动态 Dispatch 参数的 Broadcasting 节点进行启动。
struct SplitRecord{ uint3 DispatchGrid : SV_DispatchGrid;和
[Shader("node")][NodeLaunch("broadcasting")][NodeMaxDispatchGrid(240, 135, 1)] // Enough of a limit to allow practically unlimited sized triangles[NumThreads(SPLITR_NUM_THREADS, 1, 1)]void SplitDynamic(或者您可以使用固定的 Dispatch 参数。
[Shader("node")][NodeLaunch("broadcasting")][NodeDispatchGrid(1, 1, 1)] // Fixed size of exactly 1 work group[NumThreads(SPLITR_NUM_THREADS, 1, 1)]void SplitFixed(固定 Dispatch 参数变体比动态 Dispatch 变体更容易由调度器进行优化。考虑一下,我们启动了 2x Dispatch X,1,1 和 X,1,1,并且我们没有使用 Y 和 Z,如下面的“uint WorkIndex : SV_DispatchThreadID”。
对于常规的 Compute Dispatch 和 Workgraphs 的动态 Dispatch,这些是未知的和可变的 X,调度器和分配器需要为这些未知数做好准备。但是 Workgraphs 的固定 Dispatch 知道它的 X 始终相同,并且知道您没有使用 Y 和 Z。因此,调度器可以将参数合并为一个 X,2,1 并将其作为一个 dispatch 启动。
我们可以在 Workgraphs 中实现这一点,作为一个分支:如果边界框需要分片到少于 32 个片段,我们使用固定 Dispatch,否则我们使用动态 Dispatch。对此有效的关键再次是三角形大小分布,小三角形应该更频繁,大三角形应该很少。
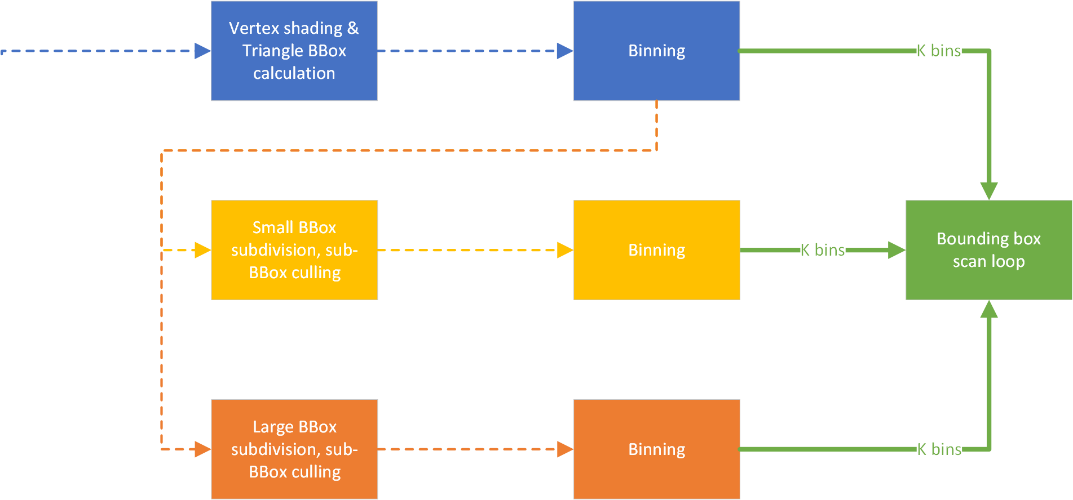
这结束了我们利用 work graphs API 范例的光栅化器设计。部分思维过程与流水线化算法或多线程大型顺序过程相似。利用使 SIMD 向量相关的数据更具连贯性的可能性(如果需要)以获得更好的性能。或者考虑在算法分支处将其拆分。这可以消除活动工作集中的死通道,或恢复条件代码片段的利用率。与所有其他细粒度多线程实践一样,尝试将节点中的计算成本保持得(如果不完全相同)尽可能短。它能带来更好的占用率,并使您的分配能够被有效重用。
这当然不是改进的详尽列表。您还可以尝试其他方法:
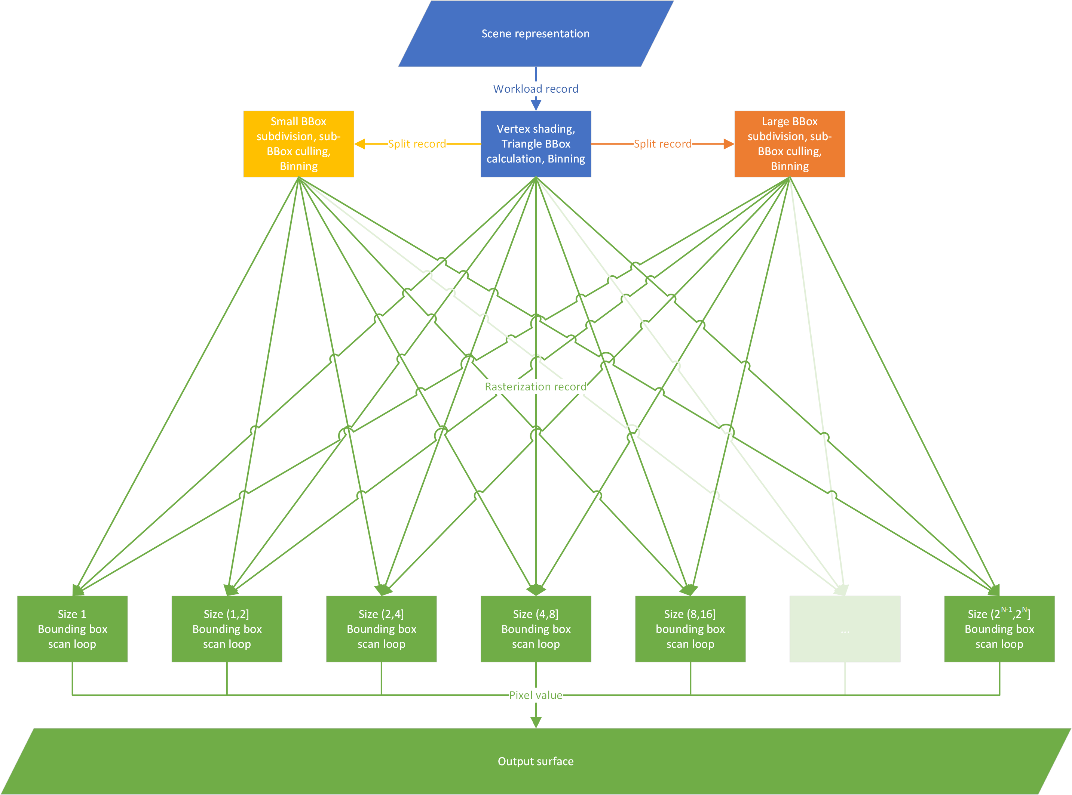
下面是我们将随后实现的最终显式算法图。
我们用于为算法提供场景数据的基本数据结构如下:
struct Workload{ uint offsetIndex; // local cluster location in the global shared index buffer uint offsetVertex; // local cluster location in the global shared vertex buffer // (indices are cluster local) uint startIndex; // start of the triangle-range in the index buffer uint stopIndex; // end of the triangle range in the index buffer, inclusive
float4 vCenter; float4 vRadius;
matrix mWorldCurrent; matrix mWorldPrevious;};Workload 项描述了要光栅化的单个对象。索引和顶点都包含在一个连续可访问的缓冲区中,因为这允许我们使用 DirectX 的传统绑定范例,只绑定两个缓冲区描述符。您也可以选择无绑定范例,并使用描述符索引代替全局缓冲区索引。
此外,我们还传递对象的 Position 和 Extent,以及其当前的世界矩阵。对于静态对象,我们只需要传输此缓冲区一次,因为信息不会随时间改变,但对于本项目,数据量足够小,可以每帧传输,并且我们不因需要区分动态对象而使事情变得更复杂。
我们在 CPU 上进行视锥体剔除,并将活动的场景元素作为 Workload 项的数组写入,然后启动工作图。
从上图来看,我们需要从算法的角度实现三个不同的阶段:
对于细分,我们有两种启动签名(固定 vs. 动态),但节点主体中的算法是相同的。对于光栅化也是如此,尽管我们有 *k* 种不同的 bin,它只是将数据分组以使其更连贯,并不要求我们有专门的实现。
这是图的根节点。它也是程序的入口点。它的特点是常规的 Compute Dispatch,我们启动的线程数量与三角形数量相同,但共享对象的 ID 和参数,因此我们将其注释为 Broadcasting 类型。
[Shader("node")][NodeLaunch("Broadcasting")][NodeMaxDispatchGrid(65535, 1, 1)][NodeIsProgramEntry][NumThreads(TRANSF_NUM_THREADS, 1, 1)]void TriangleFetchAndTransform( uint WorkgroupIndex : SV_GroupID, uint SIMDLaneIndex : SV_GroupIndex,节点由 CPU 馈送,类似于间接参数缓冲区,我们稍后将在 C++ 部分介绍。
这是放大边界框的节点,我们启动一个与计算出的子细分一样大的 dispatch 网格,但共享包含的原点边界框和三角形参数,它也是 Broadcasting 类型。
[Shader("node")][NodeLaunch("broadcasting")]#if (EXPANSION == 1) // fixed expansion[NodeDispatchGrid(1, 1, 1)] // has the size of one wave, consumes nodispatch parameters[NumThreads(SPLITR_NUM_THREADS, 1, 1)]void SplitFixed(#elif (EXPANSION == 2) // dynamic expansion[NodeMaxDispatchGrid(240, 135, 1)] // can be very large, consumesdispatch parameters[NumThreads(SPLITR_NUM_THREADS, 1, 1)]void SplitDynamic(#else[NodeMaxDispatchGrid(240, 135, 1)][NumThreads(SPLITR_NUM_THREADS, 1, 1)]void Split(#endif uint WorkSIMDIndex : SV_DispatchThreadID, // use only one dimension to allow optimizations of the dispatch为了生成不同的签名(和函数名)排列,我们使用预处理器条件,并将节点从同一代码编译多次。因为我们对固定节点和动态节点使用不同的函数签名,根据当前规范修订版,它们彼此不兼容/不可互换。因此,我们无法使用分箱/索引机制来定位它们,而是必须显式地将数据中继给另一个。
图的叶节点是光栅化器。每个线程处理自己的边界框和三角形,它们之间没有有用的信息可以共享。此节点为 Thread 类型。
[Shader("node")][NodeLaunch("thread")][NodeID("Rasterize", TRIANGLE_BIN)] // indicate position in a node-array, passed in as a preprocessor symbol while compiling the nodevoid Rasterize(一个 Thread 启动节点不受工作集大小的显式参数控制,而是其实现的工作方式类似于生产者-消费者队列。一旦积累了足够的工作来启动一个 SIMD 波形,它就会以与通道数相同的单个参数启动。这非常高效,因为可以内部选择启动线程的最佳数量,而我们不需要完全了解条件。例如,此值可能因架构甚至 SKU 而异。或者有时调度器最好通过防止停顿、恢复分配或在 SIMD 单元上预加载着色器程序来发出工作。
由于光栅化器在代码方面完全相同,我们可以使用 Workgraph 强大的节点数组概念:而不是通过显式条件结构(if/else、switch 等)重定向工作,这个概念类似于跳转表。
剩下要做的就是定义节点之间的连接。这以自上而下的方式显式指定:输出显式指向它们的目标节点。为确保这些连接有效,输入和输出都指定了它们携带的数据结构,以便运行时可以验证连接是否有效。结果是一个有向无环图。
输入和输出的声明是函数参数声明的一部分,包括它们的本地注释。这可能使 Workgraph 函数签名非常庞大。在下文中,我将仅显示与我们正在解释的数据记录相关的函数签名部分。在代码中,您会在一个大块中看到它们。
首先,我们定义如何将应用程序的数据馈送到图的根节点。因为根节点是 Broadcasting 类型,我们在数据声明中使用必需的 SV_DispatchGrid 语义。指向全局工作负载缓冲区的 workload-offset 类似于根签名常量(它在所有调用中都相同)。
struct DrawRecord{ // index into the global scene buffer containing all Workload descriptors uint workloadOffset;
uint3 DispatchGrid : SV_DispatchGrid;};现在我们将此结构声明为用于输入到我们根节点函数签名的类型。
void TriangleFetchAndTransform( // Input record that contains the dispatch grid size. // Set up by the application. DispatchNodeInputRecord<DrawRecord> launchRecord,当我们组合 dispatch 全局参数和 dispatch 局部参数时,我们可以确切地知道每个线程应该处理哪个三角形。
接下来,我们定义如何将数据从根节点传递到边界框细分节点。因为我们为此使用了两种不同的节点类型(一个固定 Dispatch 和一个动态 Dispatch,具有不兼容的函数签名),我们也想声明两种不同类型的数据结构。动态 Dispatch 必须在数据声明中使用必需的 SV_DispatchGrid 语义。固定 Dispatch 也可以使用一个,因为编译器会静默清除未使用的语义参数,但我们保留两个版本以保持清晰和无歧义的编译时验证。
struct SplitDynamicRecord{ uint3 DispatchGrid : SV_DispatchGrid;
// Triangle equation, bbox and interpolateable values struct TriangleStateStorage tri;
uint2 DispatchDims; // 2D grid range processed by this 1D dispatch uint2 DispatchFrag; // 2D size of the subdividing bounding boxes};struct SplitFixedRecord{ // Triangle equation, bbox and interpolateable values struct TriangleStateStorage tri;
uint2 DispatchDims; // 2D grid range processed by this 1D dispatch uint2 DispatchFrag; // 2D size of the subdividing bounding boxes};然后,我们将这两个记录类型添加为根节点函数签名的独立输出。对于每个输出,我们必须注释更多内容:
前者允许分配器根据情况切换分配策略,后者明确地确定数据去向。
void TriangleFetchAndTransform( [MaxRecords(TRANSF_NUM_THREADS)] // N threads that each output 1 bbox-split [NodeID("SplitFixed")] NodeOutput<SplitFixedRecord> splitFixedOutput,
[MaxRecords(TRANSF_NUM_THREADS)] // N threads that each output 1 bbox-split [NodeID("SplitDynamic")] NodeOutput<SplitDynamicRecord> splitDynamicOutput,然后我们将此结构声明为用于输入到我们细分节点函数签名的类型。
void SplitFixed/Dynamic( // Input record that may contain the dispatch grid size. // Set up by TriangleFetchAndTransform. #if (EXPANSION == 1) // fixed expansion DispatchNodeInputRecord<SplitFixedRecord> splitRecord, #else // dynamic expansion DispatchNodeInputRecord<SplitDynamicRecord> splitRecord, #endif我们不更改函数体,因为它执行相同的操作,并且参数保持不变。而是我们通过函数签名来专门化其调用方式。
最后,我们定义如何将图表中所有较高节点的数据传递到光栅化器。现在剩下的唯一必要数据,用于光栅化循环,实际上只是三角形方程、要扫描的边界框以及我们想要插补的值。
struct RasterizeRecord{ // Triangle equation, bbox and interpolateable values struct TriangleStateStorage tri;};尽管如此,正如我们在文章开头所计划的,我们希望将具有相似性能特征的数据收集在一起。实现这一目标的本机 Workgraph 构造是输出数组。到目前为止,我们只定位了单个输出。输出数组可以理解为绑定的输出束。我们使用索引来选择输出到哪个,而不是使用流程控制。当只有几个输出时,这可能没有太大区别,但一旦涉及几百个输出,使用分支就会非常低效。我们在输出的注释中指定输出数组的大小,以及输出限制和输出节点名称。与多个输出一样,不要求只选择一个选项并互斥地输入数据。如果算法要求您向多个输出(或输出数组中的多个槽)输入数据,这完全没问题。请记住调整您的峰值输出大小。
void TriangleFetchAndTransform( [MaxRecords(TRANSF_NUM_THREADS)] // N threads that each output 1 triangle [NodeID("Rasterize")] [NodeArraySize(TRIANGLE_BINS)] // TRIANGLE_BINS defined by application // during compilation NodeOutputArray<RasterizeRecord> triangleOutput和
void SplitFixed/Dynamic( [MaxRecords(SPLITR_NUM_THREADS)] // N threads that each output 1 triangle [NodeID("Rasterize")] [NodeArraySize(TRIANGLE_BINS)] // TRIANGLE_BINS defined by application // during compilation NodeOutputArray<RasterizeRecord> triangleOutput尽管我们可能通过不同的路径到达光栅化节点,但结构是相同的,声明也非常直接。
void Rasterize( ThreadNodeInputRecord<RasterizeRecord> triangleRecord就像在常规的 Compute 算法中一样,我们将光栅化输出写入 UAV,这在 Workgraphs 中不需要特殊声明。
输入和输出已声明并准备就绪,我们可以实现 i/o。这相当直接,我将不一一介绍。
如果您有一个单一输入(如 Broadcasting 和 Thread 的情况),我们可以对声明的输入调用一个简单的 getter。
uint workloadOffset = launchRecord.Get().workloadOffset;就是这样。对于 Coalescing 启动,您只需将要检索的元素的索引传递给 getter。
输出稍微复杂一些。根据规范,您必须以一致的方式调用输出记录分配器(所有通道都离开,或都不离开)。为了允许按通道单独分配,API 接受一个布尔值来指示您是否真的想要记录,或者它是否是虚拟分配。
让我们看一下根节点的输出代码。
const uint triangleBin = ts.triangleBBBin; // calculated bin, if not too largeconst bool allocateRasterRecordForThisThread = ts.triangleValid; // true if not too largeconst bool allocateSplitDynamicRecordForThisThread = !allocateRasterRecordForThisThread & (DispatchGrid.x != 1); // too large, and many work groups necessary for subdivisionconst bool allocateSplitFixedRecordForThisThread = !allocateRasterRecordForThisThread & (DispatchGrid.x == 1); // too large, but only one work group necessary for subdivision
// call allocators outside of branch scopes, the boolean indicates if we want a real record or notThreadNodeOutputRecords<RasterizeRecord> rasterRecord = triangleOutput[triangleBin] .GetThreadNodeOutputRecords(allocateRasterRecordForThisThread);ThreadNodeOutputRecords<SplitDynamicRecord> splitterDynamicRecord = splitDynamicOutput .GetThreadNodeOutputRecords(allocateSplitDynamicRecordForThisThread);ThreadNodeOutputRecords<SplitFixedRecord> splitterFixedRecord = splitFixedOutput .GetThreadNodeOutputRecords(allocateSplitFixedRecordForThisThread);
// fill the acquired output records, here we branch according to the conditionsif (allocateRasterRecordForThisThread){ rasterRecord.Get().tri = StoreTriangleState(ts);}else if (allocateSplitFixedRecordForThisThread){ splitterFixedRecord.Get().DispatchDims = DispatchDims; splitterFixedRecord.Get().DispatchFrag = DispatchFrag; splitterFixedRecord.Get().tri = StoreTriangleState(ts);}else if (allocateSplitDynamicRecordForThisThread){ splitterDynamicRecord.Get().DispatchGrid = DispatchGrid; splitterDynamicRecord.Get().DispatchDims = DispatchDims; splitterDynamicRecord.Get().DispatchFrag = DispatchFrag; splitterDynamicRecord.Get().tri = StoreTriangleState(ts);}
// call completion outside of branch scopes, this allows the scheduler to start processing themrasterRecord.OutputComplete();splitterDynamicRecord.OutputComplete();splitterFixedRecord.OutputComplete();我们有三种可能的输出场景:
由于我们注意不围绕这些调用进行分支,它看起来有点冗长,但并没有太复杂的。您从输出分配器获得的记录与您通过函数接收的输入记录的类型相同。您需要以相同的方式调用 getter。如果您分配了多个条目(本项目中没有),则传递您要访问的子分配记录的索引,与在 Coalescing 启动中提供的记录集合相同。
至此,我们在着色器代码中实现了所有与 work graphs 相关的内容。在下一章中,我们将看看如何从 CPU 端启动工作图。
在 D3D12 中创建 Workgraph 程序与创建常规的 Graphics 或 Compute pipeline State Object 略有不同。从概念上讲,它类似于为光线追踪创建 State Object(您也需要注册大量子程序)。
首先,我们将定义 Workgraph 的描述,并指定入口点/根节点。
D3D12_NODE_ID entryPointId = { .Name = L"TriangleFetchAndTransform", // name of entry-point/root node .ArrayIndex = 0,};
D3D12_WORK_GRAPH_DESC workGraphDesc = { .ProgramName = L"WorkGraphRasterization", .Flags = D3D12_WORK_GRAPH_FLAG_INCLUDE_ALL_AVAILABLE_NODES, .NumEntrypoints = 1, .pEntrypoints = &entryPointId, .NumExplicitlyDefinedNodes = 0, .pExplicitlyDefinedNodes = nullptr};然后,我们将所有节点编译成单独的着色器 blob,调整预处理器符号,以便获得我们想要的精确排列。
CompileShaderFromFile(sourceWG, &defines, "TriangleFetchAndTransform", "-T lib_6_8" OPT, &shaderComputeFrontend);
CompileShaderFromFile(sourceWG, &defines, "SplitDynamic", "-T lib_6_8" OPT, &shaderComputeSplitter[0]);CompileShaderFromFile(sourceWG, &defines, "SplitFixed", "-T lib_6_8" OPT, &shaderComputeSplitter[1]);
for (int triangleBin = 0; triangleBin < triangleBins; ++triangleBin) CompileShaderFromFile(sourceWG, &defines, "Rasterize", "-T lib_6_8" OPT, &shaderComputeRasterize[triangleBin);我们在此指定的函数名称必须与 HLSL 源代码中的名称匹配,以便编译器知道我们想要源代码的哪个部分。您可以在这里看到,对于分离器,我们可以使用明确的函数名称,因为我们在 HLSL 中更改了它们的名称。对于光栅化函数,我们将不这样做,因为对于大量节点来说,这样做是不切实际的。请记住,我们可能有数百个这样的节点!
相反,我们使用 API 的一个巧妙功能:在链接程序时更改函数名称,但稍后会详细介绍。
在编译完所有单独的着色器 blob 后,我们可以将它们注册为 Workgraph 程序的子对象。
std::vector<D3D12_STATE_SUBOBJECT> subObjects = { {.Type = D3D12_STATE_SUBOBJECT_TYPE_GLOBAL_ROOT_SIGNATURE, .pDesc = &globalRootSignature}, {.Type = D3D12_STATE_SUBOBJECT_TYPE_WORK_GRAPH, .pDesc = &workGraphDesc},};
D3D12_DXIL_LIBRARY_DESC shaderComputeFrontendDXIL = { .DXILLibrary = shaderComputeFrontend, .NumExports = 0, .pExports = nullptr};
subObjects.emplace_back(D3D12_STATE_SUBOBJECT_TYPE_DXIL_LIBRARY, &shaderComputeFrontendDXIL); // move into persistent allocation
D3D12_DXIL_LIBRARY_DESC shaderComputeSplitter0DXIL = { .DXILLibrary = shaderComputeSplitter[0], .NumExports = 0, .pExports = nullptr};
subObjects.emplace_back(D3D12_STATE_SUBOBJECT_TYPE_DXIL_LIBRARY, &shaderComputeSplitter0DXIL); // move into persistent allocation
D3D12_DXIL_LIBRARY_DESC shaderComputeSplitter1DXIL = { .DXILLibrary = shaderComputeSplitter[1], .NumExports = 0, .pExports = nullptr};
subObjects.emplace_back(D3D12_STATE_SUBOBJECT_TYPE_DXIL_LIBRARY, &shaderComputeSplitter1DXIL); // move into persistent allocation到目前为止一切顺利。现在我们要注册光栅化器着色器 blob,并且必须重命名它们。链接器将自动将函数名称与我们在 HLSL 中给出的输出数组声明进行匹配。
[NodeID("Rasterize")]NodeOutputArray<RasterizeRecord> triangleOutput匹配器遵循的模式是“<函数名>_<索引>”。我们将在下面指定,我们希望将“Rasterize”重命名为“Rasterize_0”,以此类推。
for (int triangleBin = 0; triangleBin < triangleBins; ++triangleBin){ auto entryPoint = L"Rasterize";
// Change "Rasterize" into "Rasterize_k" refNames.emplace_back(std::format(L"{}_{}", entryPoint, triangleBin)); // move into persistent allocation
// Tell the linker to change the export name when linking D3D12_EXPORT_DESC shaderComputeRasterizeExport = { .Name = refNames.back().c_str(), .ExportToRename = entryPoint, .Flags = D3D12_EXPORT_FLAG_NONE };
expNames.emplace_back(shaderComputeRasterizeExport); // move into persistent allocation
D3D12_DXIL_LIBRARY_DESC shaderComputeRasterizeDXIL = { .DXILLibrary = shaderComputeRasterize[triangleBin], .NumExports = 1, .pExports = &expNames.back() };
libNames.emplace_back(shaderComputeRasterizeDXIL); // move into persistent allocation
subObjects.emplace_back(D3D12_STATE_SUBOBJECT_TYPE_DXIL_LIBRARY, &libNames.back());}此外,还有一些代码可以防止悬空指针导致范围外的解分配。
现在我们已经收集并定义了创建 Workgraph 程序所需的所有必要信息。
const D3D12_STATE_OBJECT_DESC stateObjectDesc = { .Type = D3D12_STATE_OBJECT_TYPE_EXECUTABLE, .NumSubobjects = static_cast<UINT>(subObjects.size()), .pSubobjects = subObjects.data()};
ThrowIfFailed(m_pDevice->CreateStateObject(&stateObjectDesc, IID_PPV_ARGS(&m_pipelineWorkGraph)));它的设置肯定比预定义的硬件流水线阶段(VS、PS、CS 等)要复杂,但它允许您灵活地将各种不同的 Workgraph 从通用构建块组装起来,而无需将这种多样性的规范泄露到您的 HLSL 代码中。
正如我们一开始所说,Workgraphs 的一个有益功能是它允许您进行分配,以便将数据从一个节点传递到下一个节点。但实现从中提取分配的内存池不是隐藏的隐式池。获取 Workgraph State Object 后,我们必须弄清楚该内存池的总大小应该是多少,并且我们还必须自己分配缓冲区并将其提供给实现。
ComPtr<ID3D12WorkGraphProperties> workGraphProperties;ThrowIfFailed(m_pipelineWorkGraph->QueryInterface(IID_PPV_ARGS(&workGraphProperties)));
D3D12_WORK_GRAPH_MEMORY_REQUIREMENTS workGraphMemoryRequirements;workGraphProperties->GetWorkGraphMemoryRequirements(0, &workGraphMemoryRequirements);
const auto workGraphBackingMemoryResourceDesc = CD3DX12_RESOURCE_DESC::Buffer(workGraphMemoryRequirements.MaxSizeInBytes);
const auto defaultHeapProps = CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT);
ThrowIfFailed(m_pDevice->CreateCommittedResource( &defaultHeapProps, D3D12_HEAP_FLAG_NONE, &workGraphBackingMemoryResourceDesc, D3D12_RESOURCE_STATE_COMMON, nullptr, IID_PPV_ARGS(&m_memoryWorkGraph)));
const D3D12_GPU_VIRTUAL_ADDRESS_RANGE backingMemoryAddrRange = { .StartAddress = m_memoryWorkGraph->GetGPUVirtualAddress(), .SizeInBytes = workGraphMemoryRequirements.MaxSizeInBytes,};底层内存的大小取决于您的 Workgraph 的结构:有多少输出?输出的类型是什么?等等。内存大小将足以让 Workgraph 实现始终能够取得进展。
最后,我们准备好在 GPU 上启动 Workgraph。我们有:
同样,设置 Workgraphs 实现需要我们设置一些结构来告诉运行时我们确切想要发生什么。
ComPtr<ID3D12WorkGraphProperties> workGraphProperties;ThrowIfFailed(m_pipelineWorkGraph->QueryInterface(IID_PPV_ARGS(&workGraphProperties)));
ComPtr<ID3D12StateObjectProperties1> workGraphProperties1;ThrowIfFailed(m_pipelineWorkGraph->QueryInterface(IID_PPV_ARGS(&workGraphProperties1)));
D3D12_WORK_GRAPH_MEMORY_REQUIREMENTS workGraphMemoryRequirements;workGraphProperties->GetWorkGraphMemoryRequirements(0, &workGraphMemoryRequirements);
// Define the address and size of the backing memoryconst D3D12_GPU_VIRTUAL_ADDRESS_RANGE backingMemoryAddrRange = { .StartAddress = m_memoryWorkGraph->GetGPUVirtualAddress(), .SizeInBytes = workGraphMemoryRequirements.MaxSizeInBytes,};
// Backing memory only needs to be initialized onceconst D3D12_SET_WORK_GRAPH_FLAGS setWorkGraphFlags =m_memoryInitialized ? D3D12_SET_WORK_GRAPH_FLAG_NONE : D3D12_SET_WORK_GRAPH_FLAG_INITIALIZE;m_memoryInitialized = true;
const D3D12_SET_WORK_GRAPH_DESC workGraphProgramDesc = { .ProgramIdentifier = workGraphProperties1->GetProgramIdentifier(L"WorkGraphRasterization"), .Flags = setWorkGraphFlags, .BackingMemory = backingMemoryAddrRange};
const D3D12_SET_PROGRAM_DESC programDesc = { .Type = D3D12_PROGRAM_TYPE_WORK_GRAPH, .WorkGraph = workGraphProgramDesc};
// Set the program and backing memorypCommandList->SetProgram(&programDesc);
// Submit all of our DrawRecords in one batch-submissionconst D3D12_NODE_CPU_INPUT nodeCPUInput { .EntrypointIndex = 0, .NumRecords = UINT(m_Arguments.size()), .pRecords = (void*)m_Arguments.data(), .RecordStrideInBytes = sizeof(DrawRecord),};
const D3D12_DISPATCH_GRAPH_DESC dispatchGraphDesc = { .Mode = D3D12_DISPATCH_MODE_NODE_CPU_INPUT, .NodeCPUInput = nodeCPUInput,};
pCommandList->DispatchGraph(&dispatchGraphDesc);这将启动与场景中的对象数量相等的 Workgraph 实例。每个 Workgraph 实例都通过其根节点中每个对象中的顶点数量,并继续通过图直到到达叶节点,在那里我们将光栅化和插值的值写入屏幕大小的 UAV。
文章到此结束,让我们来看看结果,以及一切是否如我们预期的那样工作。在 rasterizer repository 的实现中,我们提供了各种控件,以便您可以实时探索性能差异。
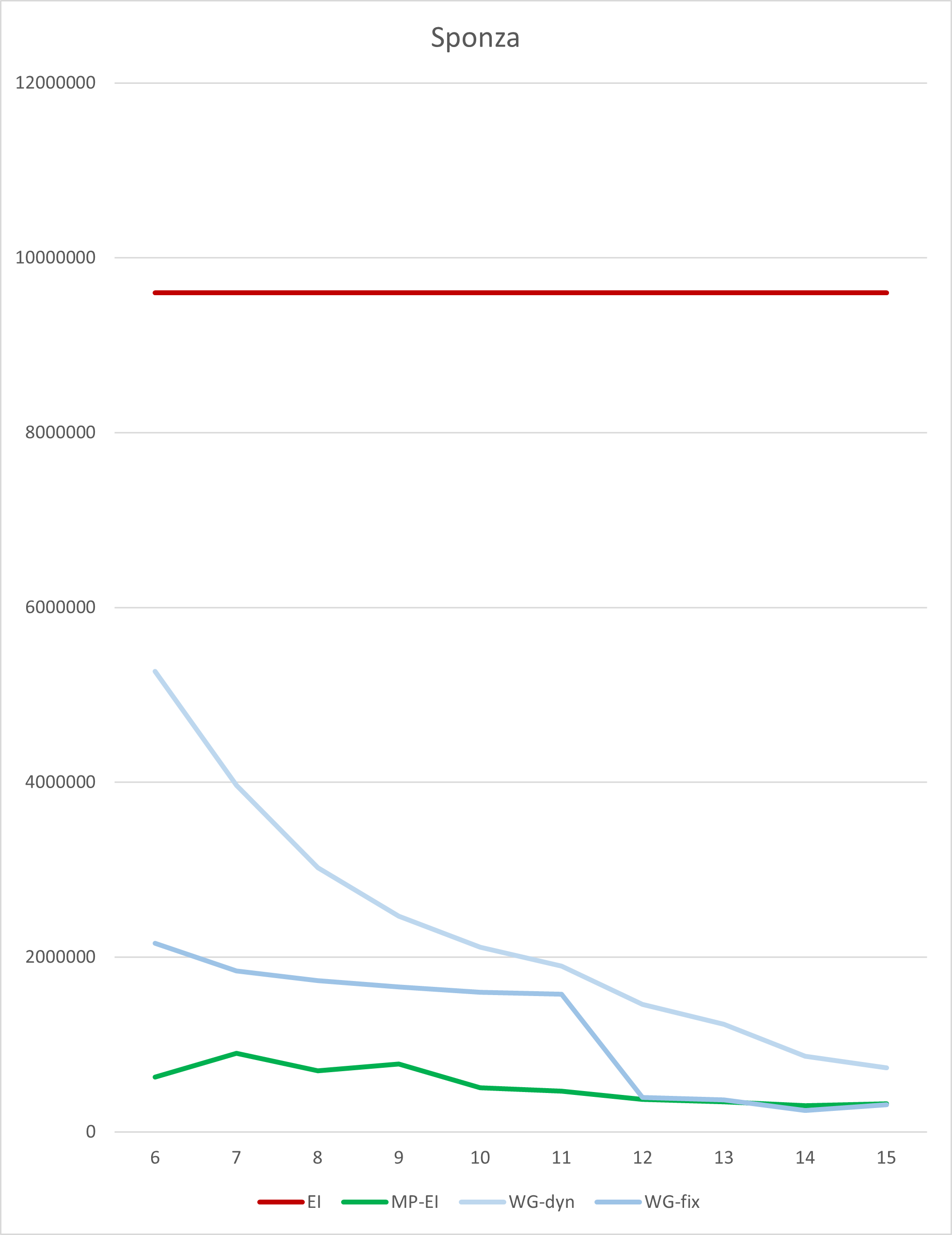
该场景来自 glTFSample repository。这是 Crytek 的 Sponza 场景。它有一些非常大的三角形,也有很多小三角形。较暗的颜色表示较小的边界框。

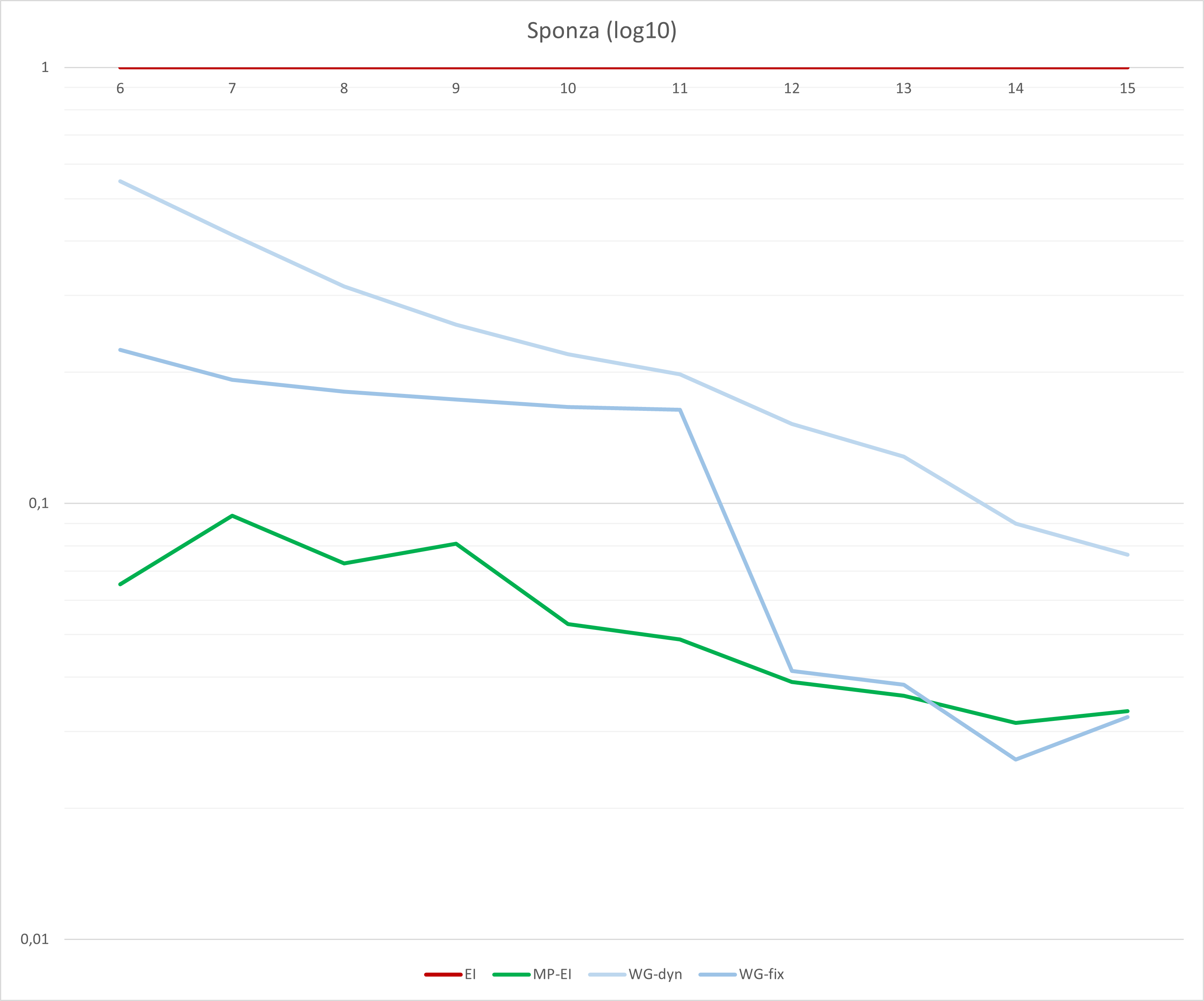
时间以 10ns 滴答为单位。测试的 GPU 是 7900 XTX。测试的驱动程序是 23.20.11.01。为了更好地可视化,我们绘制了一个图表,其中log10(ratio)与单片(纯 GPU SIMD)实现进行比较。
| 10ns 滴答 | log10(比率) |
|---|---|
 |  |
| 分箱 | 单片 ExIn | 多通道 ExIn | 动态 WoGr | 固定 WoGr |
|---|---|---|---|---|
| 6 | 9598764 | 625700 | 5267600 | 2158076 |
| 7 | 9598764 | 898932 | 3964992 | 1842596 |
| 8 | 9598764 | 698976 | 3020956 | 1730860 |
| 9 | 9598764 | 776720 | 2466808 | 1661224 |
| 10 | 9598764 | 507876 | 2111640 | 1598632 |
| 11 | 9598764 | 467532 | 1896800 | 1575920 |
| 12 | 9598764 | 373704 | 1461440 | 395980 |
| 13 | 9598764 | 347604 | 1229584 | 368704 |
| 14 | 9598764 | 301444 | 863680 | 248180 |
| 15 | 9598764 | 320772 | 731676 | 310732 |
正如您所见,性能在很大程度上取决于分箱的数量(以及因此光栅化边界框的最大尺寸)。但是,最佳点似乎在 14 个分箱左右(大约是 214 = 16k 像素,其中包含 128x128)。Workgraph 实现具有中等大小的底层缓冲区,约 130MB。它比单片 ExecuteIndirect 实现快 38 倍以上。固定 Dispatch 变体比仅动态 Dispatch 变体快约 3 倍。
如果我们将它与复杂的、内存消耗较大且占用大量内存带宽的、多通道的 ExecuteIndirect 实现进行比较,我们仍然可以获得约 1.2 倍的优势。
本教程的示例代码可在 GitHub 上找到:https://github.com/GPUOpen-LibrariesAndSDKs/WorkGraphComputeRasterizer
为了让您能够尝试各种场景,它基于 GitHub 上已有的 glTFSample:https://github.com/GPUOpen-LibrariesAndSDKs/glTFSample
您可以在 GitHub 上找到一个很棒的 glTF 场景存储库:https://github.com/KhronosGroup/glTF-Sample-Models
本教程中涉及的源代码可以在这里找到:
第三方网站链接仅为方便用户提供,除非另有明确说明,AMD不对任何此类链接网站的内容负责,且不暗示任何认可。GD-98
Microsoft 是 Microsoft Corporation 在美国和/或其他国家/地区的注册商标。本出版物中使用的其他产品名称仅用于标识目的,并可能为其各自所有者的商标。
DirectX 是 Microsoft Corporation 在美国和/或其他国家/地区的注册商标。