FidelityFX 模糊 1.1
FidelityFX 模糊是一种基于计算、高度优化、单次通道的高斯模糊技术。
要求
HLSLCS_6_0GLSLversion 450
目录
集成指南
C++ SDK 集成
集成 FidelityFX 模糊效果的最简单方法是使用 FFX SDK C++ API。
C++ 示例
// Initialize the FFX backend and blur context (do this once)size_t scratchBufferSize = ffxGetScratchMemorySize(FFX_BLUR_CONTEXT_COUNT);void* scratchBuffer = malloc(scratchBufferSize);FfxInterface backendInterface;ffxGetInterface(&backendInterface, GetDevice(), scratchBuffer, scratchBufferSize, FFX_BLUR_CONTEXT_COUNT);
FfxBlurContextDescription desc = {};desc.backendInterface = backendInterface;desc.floatPrecision = FFX_BLUR_FLOAT_PRECISION_32BIT;desc.kernelPermutations = FFX_BLUR_KERNEL_PERMUTATIONS_ALL; // mask to support some Guassian sigma kernels or ALLdesc.kernelSizes = FFX_BLUR_KERNEL_SIZE_ALL; // mask to support some kernel sizes or ALL
FfxBlurContext blurContext;ffxBlurContextCreate(&blurContext, &desc);
// Execute blur effect (multiple times)FfxBlurDispatchDescription desc = {};
desc.commandList = ffxGetCommandList(pCmdList);
desc.kernelPermutation = FFX_BLUR_KERNEL_PERMUTATION_2; // Guassian sigma (1.6, 2.8, or 4.0)desc.kernelSize = FFX_BLUR_KERNEL_SIZE_15x15; // Kernel sizes (3x3 ... 21x21)
desc.input = ffxGetResource(inputResource, L"BLUR_InputSrc", FFX_RESOURCE_STATE_PIXEL_COMPUTE_READ);
desc.inputAndOutputSize.width = desc.input.description.width;desc.inputAndOutputSize.height = desc.input.description.height;
desc.output = ffxGetResource(outputResource, L"BLUR_Output", FFX_RESOURCE_STATE_UNORDERED_ACCESS);
ffxBlurContextDispatch(&blurContext, &desc);
// When done using the blur effect, clean up.ffxBlurContextDestroy(&blurContext);通过回调和主函数进行自定义
模糊提供了 ffx_blur_callbacks_hlsl.h 和 ffx_blur_callbacks_glsl.h 中的模糊核权重和输入/输出函数的默认实现。SDK 用户可以覆盖它们以集成到自己的应用程序中。
为了实现最高性能,模糊要求将一维模糊核权重嵌入编译后的着色器中,并满足以下要求:
- 根据半精度支持,核权重使用
FfxFloat32或FfxFloat16类型。这些类型在ffx_core.hFFX SDK 头文件中定义。 - 定义一组唯一的核权重作为静态数组,代表归一化的高斯权重分布,元素按降序排列。
模糊核重写示例
#if FFX_HALF #define FFX_BLUR_KERNEL_TYPE FfxFloat16#else #define FFX_BLUR_KERNEL_TYPE FfxFloat32#endif
inline FFX_BLUR_KERNEL_TYPE GetKernelWeight(int iKernelIndex){ static FFX_BLUR_KERNEL_TYPE kernel_weights[] = { 0.257030201088974, 0.22378581991669, 0.147699079538823 }; // for a 5x5 Gaussian kernel return kernel_weights[iKernelIndex];}FFX_BLUR_KERNEL_TYPE FfxBlurLoadKernelWeight(FfxInt32 iKernelIndex) { return GetKernelWeight(iKernelIndex); }模糊输入/输出函数重写示例
#if FFX_HALF FfxFloat16x3 FfxBlurLoadInput(FfxInt16x2 inPxCoord) { return texColorInput[inPxCoord].rgb; } void FfxBlurStoreOutput(FfxInt32x2 outPxCoord, FfxFloat16x3 color) { texColorOutput[outPxCoord] = min16float4(color, 1); }#else FfxFloat32x3 FfxBlurLoadInput(FfxInt32x2 inPxCoord) { return texColorInput[inPxCoord].rgb; } void FfxBlurStoreOutput(FfxInt32x2 outPxCoord, FfxFloat32x3 color) { texColorOutput[outPxCoord] = float4(color, 1); }#endif也可以通过自己的 main 函数集成模糊效果。
- 必须定义
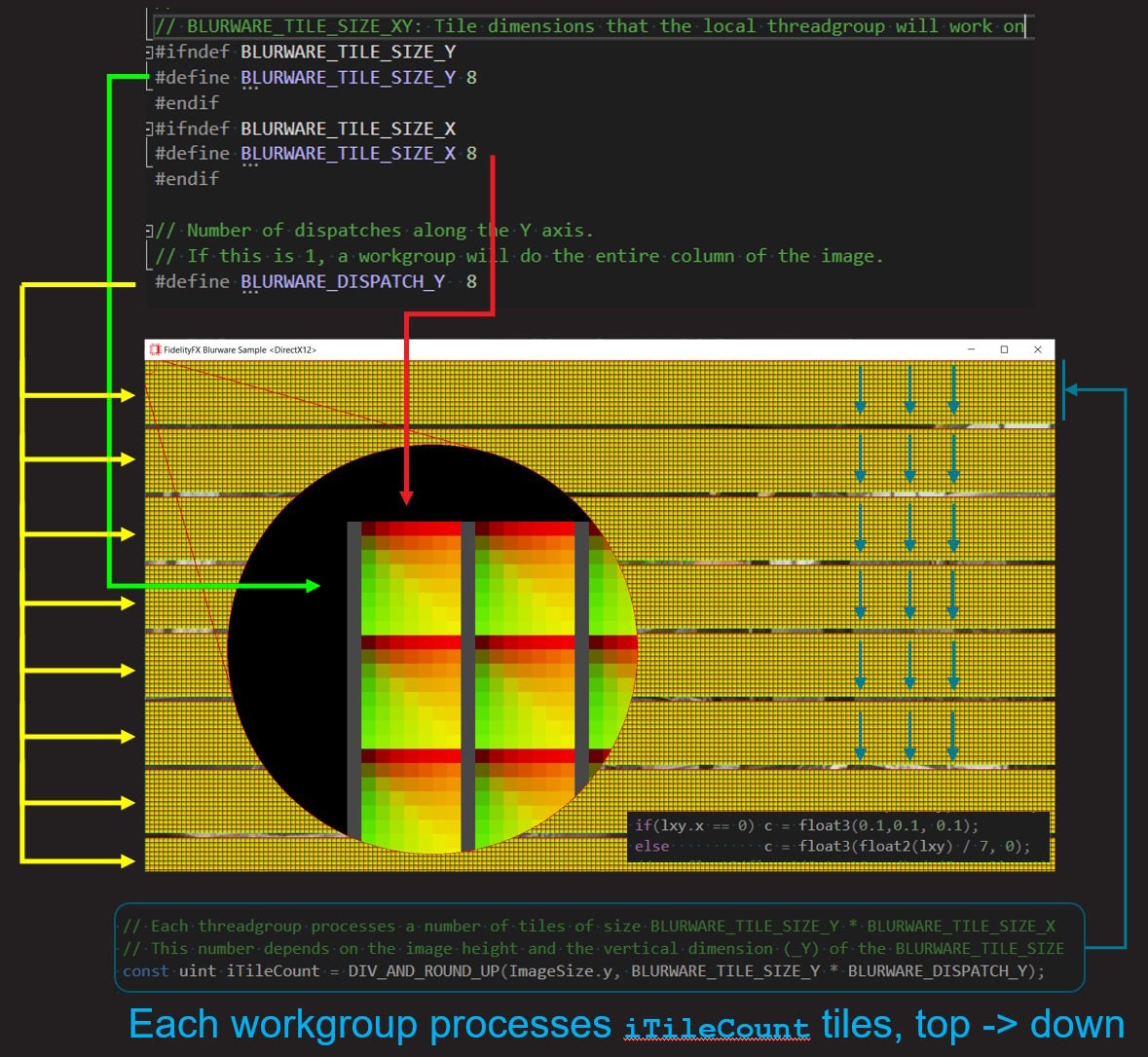
FFX_BLUR_TILE_SIZE_X和FFX_BLUR_TILE_SIZE_Y宏。通常这两个值设置为 8。
HLSL 示例
#include "blur/ffx_blur_callbacks_hlsl.h"#include "blur/ffx_blur_blur.h"
[numthreads(FFX_BLUR_TILE_SIZE_X, FFX_BLUR_TILE_SIZE_Y, 1)]void CS( uint3 LocalThreadId : SV_GroupThreadID, uint3 WorkGroupId : SV_GroupID, uint3 DispatchThreadID : SV_DispatchThreadID){ // Run FidelityFX - Blur ffxBlurPass(int2(DispatchThreadID.xy), int2(LocalThreadId.xy), int2(WorkGroupId.xy));}GLSL 示例
#include "blur/ffx_blur_callbacks_glsl.h"#include "blur/ffx_blur_blur.h"
layout (local_size_x = FFX_BLUR_TILE_SIZE_X, local_size_y = FFX_BLUR_TILE_SIZE_Y, local_size_z = 1) in;void main(){ // Run FidelityFX Blur ffxBlurPass( FfxInt32x2(gl_GlobalInvocationID.xy), FfxInt32x2(gl_LocalInvocationID.xy), FfxInt32x2(gl_WorkGroupID.xy));}深入解析:高斯模糊
算法
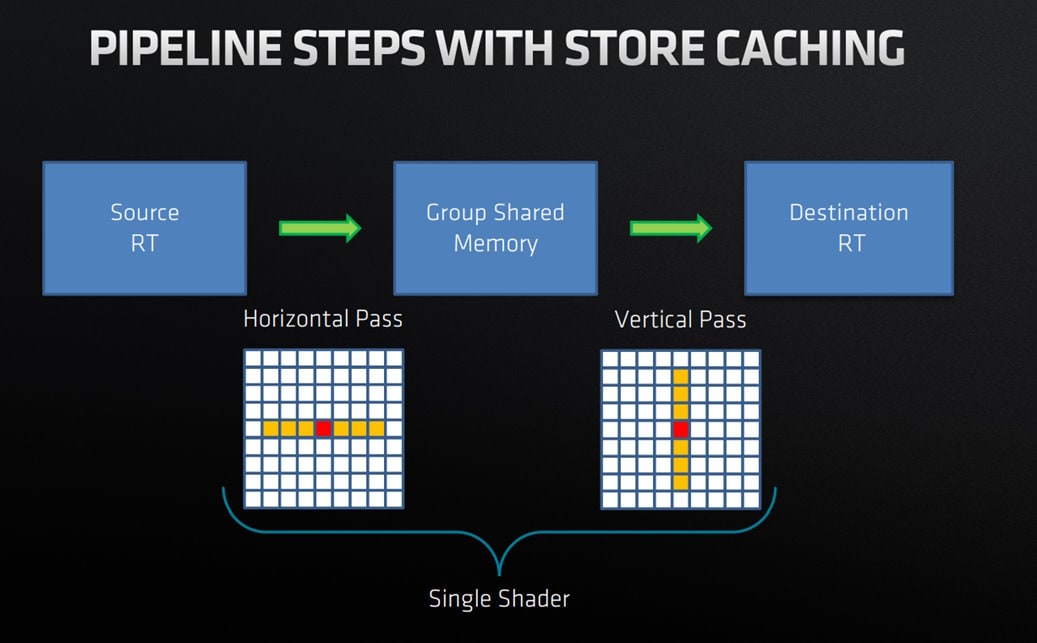
模糊采用了一个在**单个计算调度**中实现的 3 步算法,利用线程组共享内存来存储中间模糊结果。
三个步骤如下:
- 预填充步骤
- 从图像源填充缓存以进行水平模糊
- 从上到下循环
- 从图像源填充缓存以进行水平模糊
- 对缓存结果进行垂直模糊
- 写入目标资源
- 循环处理最后几个图块
- 从缓存进行垂直模糊
- 写入目标资源
| 调度时间复杂度 | 波执行时间复杂度 | 组共享内存空间复杂度 |
|---|---|---|
O(W * H * K) | O(H * K) | O(Th * (Tw + K)) |
其中
W:图像宽度H:图像高度K:一维核大小Tw:模糊图块大小 XTh:模糊图块大小 Y
工作分配
模糊使用 8x8 线程组,覆盖图像中的一个“图块”。
工作分配受以下 #defines 的影响:
共享内存
| 模糊使用一个共享内存区域作为图块的环形缓冲区来存储中间结果。 对应单个图块的线程组在存储结果到共享内存之前,对源图像进行采样并执行水平模糊。 之后,线程组从共享内存读取,并对中间结果执行垂直模糊,然后将完全模糊的图像存储到目标纹理中。 |  |
进一步阅读
- GDC 2019:GCN 优化与色彩处理的融合,第一部分:可分离滤波器中的存储缓存 PDF 链接
- GDC 2018:引擎优化热身赛 PPTX 下载链接
- Rastergrid:线性采样的高效模糊 网页链接