FidelityFX 并行排序 1.3
FidelityFX Parallel Sort 是一种使用基于 GPU 的基数排序算法来排序提供的键缓冲区和可选负载的技术。
着色语言要求
HLSL GLSL CS_6_0
技术
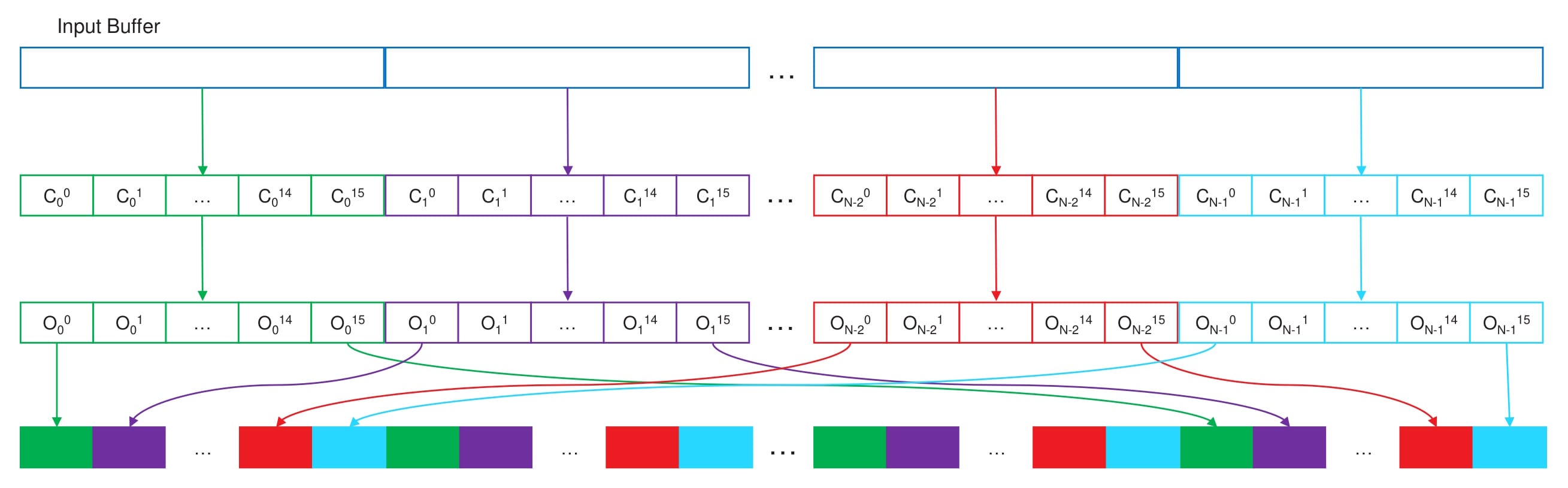
FidelityFX Parallel Sort 将使用 RDNA 优化的 GPU 基数排序算法对提供的键缓冲区和可选负载缓冲区进行排序,这是目前可用的最大数据集最快的排序算法之一。
该算法通过操作连续数据的 块 来实现最佳读取。线程组将根据数据集大小对一个或多个 块 的数据进行排序,并以每线程组可配置数量的线程(当前设置为 128)执行。
为了完全排序 32 位键的缓冲区,该算法会调用 8 次迭代,每次迭代将执行以下步骤中的 4 位增量:
- Count: 根据处理的位数统计局部排序集中的值数量。
- ReduceCount: 进一步减少值计数以对齐线程组大小,从而加快线程组之间的偏移计算。
- ScanPrefix: 对减少的计数进行求和,以提供线程组偏移。
- ScanPrefix + Add: 对线程计数进行求和,并与线程组偏移量相加,以提供最终的偏移位置。
- Scatter: 将源值复制到其新位置(已排序到目前处理的 n 位)。
C++ 示例
通过静态库
FfxParallelSortDispatchDescription dispatchDesc = {};dispatchDesc.commandList = ffxGetCommandList(pCmdList);dispatchDesc.keyBuffer = ffxGetResource(m_pKeysToSort->GetResource(), L"ParallelSort_KeyBuffer", FFX_RESOURCE_STATE_PIXEL_COMPUTE_READ);dispatchDesc.payloadBuffer = ffxGetResource(m_pPayloadToSort->GetResource(), L"ParallelSort_PayloadBuffer", FFX_RESOURCE_STATE_PIXEL_COMPUTE_READ);dispatchDesc.numKeysToSort = <Number of keys to sort>;
FfxErrorCode errorCode = ffxParallelSortContextDispatch(&m_ParallelSortContext, &dispatchDesc);FFX_ASSERT(errorCode == FFX_OK);