FidelityFX 单通道降采样器 2.2
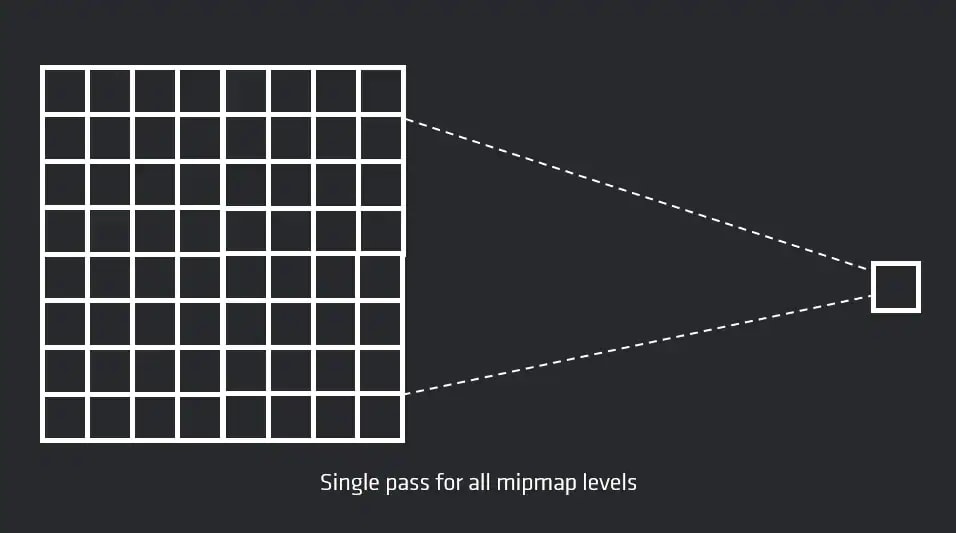
FidelityFX 单通道降采样器(简称“FidelityFX SPD”)是一种无需多个中间步骤即可生成图像降采样版本的技术。
着色语言要求
HLSL GLSL CS_6_0
技术
FidelityFX SPD 使用用户定义的 2x2 内核对输入纹理进行降采样,并使用 LDS 进行中间存储。可选地,可以使用 wave 操作在线程之间共享数据以进行额外的优化。
一个线程组将输入纹理的 64x64 块降采样到 1x1。之后,全局原子计数器将递增。然后,线程组将检查全局原子计数器——如果它等于块的数量,它将像以前一样处理最后一个块,计算输入纹理的最后 6 个 MIP 级别。
最后一个块由所有线程组的 1x1 输出组成。
这样,只需一次 dispatch 调用即可将 4096x4096 的纹理降低到 1x1。
输入
本节介绍 FidelityFX SPD 技术的输入。
| 输入名称 | 类型 | 说明 |
|---|---|---|
| 输入纹理 | 2D 纹理 或 2D 纹理数组 | 需要生成 MIP 级别的资源。支持 2D 纹理和 2D 纹理数组。 |
| 常量 | 常量缓冲区 | 包含有关要生成的 MIP 级别数量以及要降采样输入纹理区域信息的常量缓冲区。 |
| 全局原子计数器 | [globallycoherent] RW buffer uint | 每个输入纹理切片的全局原子计数器。初始化为 0。 |
输入纹理
输入纹理是 2D 纹理或映射为 2D 数组的立方体贴图纹理。在这两种情况下,都只 dispatch 一个 pass 来生成所有 MIP 级别。
输入纹理可以通过采样器或直接加载在着色器中进行访问。如果指定的内核计算 2x2 quad 的平均值,则建议使用线性采样器,而不是手动计算平均值。但是,加载比点采样更受欢迎。
当输入纹理被访问为无序访问视图 (UAV) 纹理时,它可以是输出纹理数组的一部分。您也可以单独绑定输入纹理,作为 UAV 或着色器资源视图 (SRV)。
常量
如果用户选择使用效果的静态库版本,则常量将自动生成,并且 FidelityFX SPD 将始终从头开始生成完整的 MIP 链。
如果已知纹理的某些区域在上一帧中未被修改,则可以仅计算指定数量的 MIP 级别,并且仅降采样输入纹理的子区域。
ffxSpdSetup 是一个 CPU 端辅助函数,它有助于根据提交的子区域(左、上、宽、高)和 MIP 级别数量(指定 -1 表示 MAX)来填充常量缓冲区。
常量缓冲区需要定义以下参数
-
mips:要计算的 mip 级别数量。使用 -1 让ffxSpdSetup根据子区域的宽度和高度计算最大 mip 级别数量。 -
numWorkGroups:每个切片的 dispatch 线程组数量。每个线程组降采样一个 64x64 的块。ffxSpdSetup根据指定的子区域计算线程组的数量。 -
workGroupOffset:线程组的偏移量,用于仅处理指定子区域中的块。ffxSpdSetup有助于计算正确的 workGroupOffset。
全局原子计数器
FidelityFX SPD 需要每个切片有一个全局原子计数器(uint)。计数器需要初始化为 0。
FidelityFX SPD 将在 dispatch 结束时将计数器的值重置为 0。如果全局原子计数器的内存存在别名,则应用程序有责任确保在 dispatch 开始时将计数器设置为 0。
全局原子计数器在着色器中需要具有 [globallycoherent] 标签,因为它的值需要对所有线程组可见。
输出
本节详细介绍了 FidelityFX SPD 技术产生的输出。
| 输出名称 | 类型 | 说明 |
|---|---|---|
| 输出纹理 | 2D 纹理数组或 2D 纹理数组 | 输入纹理的计算出的 MIP 级别。 |
| 输出纹理 MIP 级别 6 | [globallycoherent] 2D 纹理 或 [globallycoherent] 2D 纹理数组 | 带有全局一致性标签绑定的第 6 个 MIP 级别。 |
输出纹理
输出纹理是 2D 纹理数组,或者在 FidelityFX SPD 降采样立方体贴图的情况下是 2D 纹理数组的数组。
每个切片的 MIP 级别 6 会被绑定两次——一次作为数组的一部分,一次单独绑定并带有 [globallycoherent] 标签。着色器本身仅访问单独绑定的 MIP 6 资源。 [globallycoherent] 标签是必需的,因为它的内容需要对所有线程组可见。
算法结构
FidelityFX SPD 为输入纹理的每个 64x64 块生成一个线程组。每个块单独降采样到 1x1,贡献给 MIP 级别 1-6。MIP 级别 6 的每个像素都由不同的线程组计算。
其余的 MIP 由最后一个活动的线程组计算。
当每个线程组完成其块的降采样后,它会增加一个全局计数器并检查计数器是否等于块的数量。如果不等于,则线程组终止。如果等于,它就知道它是最后一个活动的线程组,并将执行剩余的降采样。这确保了 FidelityFX SPD 中只有一个线程组间的同步,而不是在每个 MIP 级别后都进行一次同步。
所有其他同步都在单个线程组内部进行。单个线程组通过使用 LDS 和可选的 wave 操作在其线程之间共享数据。
局限性
FidelityFX SPD 目前仅支持 2x2 内核以及每个 MIP 级别的 min、max 或 mean 操作。
对于奇数尺寸,将省略最后一行或最后一列。例如,分辨率为 7x4 的 MIP 级别为 3x2,值为 6x4 子区域。第 7 行被忽略。
这个问题可以通过将输入纹理填充到 2 的幂次方来解决。另一种解决方案是将输入纹理填充到 64 的倍数,并手动处理最后一个剩余线程组计算的 MIP 的奇数分辨率情况。这些 MIP 都在全局计数器被评估后计算。
集成指南
用户可以设置一些选项,这些选项会影响性能。
标志
FfxSpdInitializationFlagBits 或通过着色器代码中的定义进行本机集成。
Wave 操作
默认情况下,FidelityFX SPD 将使用 wave 操作和组共享内存 (LDS) 来共享单个线程组内线程之间的数据。如果不支持 wave 操作,请设置 FFX_SPD_OPTION_WAVE_INTEROP_LDS 标志,告诉 SPD 只使用 LDS。此定义可能会影响性能。
半精度类型
FidelityFX SPD 支持半精度类型。如果 16 位精度足够,建议设置 FFX_SPD_MATH_PACKED 标志。
采样器
FidelityFX SPD 支持通过线性采样器或纹理加载来访问输入纹理。除非您可以使用线性采样器,否则建议使用加载。设置 FFX_SPD_SAMPLER_LINEAR 标志来采样输入纹理。
组共享内存 (LDS)
FidelityFX SPD 使用组共享内存来共享单个线程组内线程之间的数据。所需的组共享内存量取决于是否使用半精度类型。
组共享内存可以用 float4 定义
float4 spdIntermediate[16][16];或单独用 float 定义
float spdIntermediateR[16][16];float spdIntermediateG[16][16];float spdIntermediateB[16][16];float spdIntermediateA[16][16];对于半精度类型,请使用
min16float4 spdIntermediate[16][16];或
min16float2 spdIntermediateRG[16][16];min16float2 spdIntermediateBA[16][16];您还需要定义组共享内存中的计数器。此计数器用于存储原子添加的返回值,以便每个线程可以确定它是否需要终止或继续。
回调函数
FidelityFX SPD 需要以下回调函数定义(如果 FidelityFX SPD 需要处理半精度类型,则使用 [H] 版本)
SpdLoadSourceImage[H]
为给定的 UV 和切片从输入纹理进行采样或加载。
SpdLoad[H]
为给定的 UV 和切片从带有 [globallycoherent] 标签的单独绑定的 MIP 级别 6 资源加载。此函数仅由最后一个活动的线程组使用。
SpdStore[H]
将输出存储到 MIP 级别。如果 mip 值为 5,则需要将输出存储到带有 [globallycoherent] 标签的单独绑定的 MIP 级别 6 资源。
SpdIncreaseAtomicCounter
增加全局原子计数器。我们每个切片都有一个计数器。原子添加返回前一个值,需要将其存储到共享内存中,因为只有线程 0 调用原子添加。这样,前一个值就可以被线程组中的所有线程访问,并且每个线程都可以使用它来确定是应该终止还是继续。
SpdGetAtomicCounter
读取存储在共享内存中的全局原子计数器的值。
SpdResetAtomicCounter
将给定切片的全局原子计数器重置为 0。
SpdReduce4[H]
用户指定的 2x2 -> 1 归约内核。常见的归约函数是 min、max 或平均值。
SpdLoadIntermediate[H]
从组共享缓冲区加载。
SpdStoreIntermediate[H]
存储到组共享缓冲区。
主函数
SpdDownsample[H] 在主函数中调用。线程组大小为 [numthreads(256,1,1)]。
CSMain 示例
[numthreads(256, 1, 1)]void main( uint3 WorkGroupId : SV_GroupID , uint LocalThreadId : SV_GroupIndex){#if FFX_HALF SpdDownsampleH(WorkGroupId.xy, LocalThreadId, Mips(), NumWorkGroups(), WorkGroupId.z, WorkGroupOffset());#else SpdDownsample(WorkGroupId.xy, LocalThreadId, Mips(), NumWorkGroups(), WorkGroupId.z, WorkGroupOffset());#endif // FFX_HALF}C++ 示例
通过静态库
FfxSpdDispatchDescription dispatchParameters = {};dispatchParameters.commandList = ffxGetCommandList(pCmdList);dispatchParameters.resource = ffxGetResource(m_pCubeTexture->GetResource(), L"SPD_Downsample_Resource", FFX_RESOURCE_STATE_PIXEL_COMPUTE_READ);
FfxErrorCode errorCode = ffxSpdContextDispatch(&m_SPDContext, &dispatchParameters);FFX_ASSERT(errorCode == FFX_OK);本机集成
ffxSpdSetup(dispatchThreadGroupCountXY, workGroupOffset, numWorkGroupsAndMips, rectInfo);
// downsampleuint32_t dispatchX = dispatchThreadGroupCountXY[0];uint32_t dispatchY = dispatchThreadGroupCountXY[1];uint32_t dispatchZ = m_cubeTexture.GetArraySize();
SpdConstants constants;constants.numWorkGroupsPerSlice = numWorkGroupsAndMips[0];constants.mips = numWorkGroupsAndMips[1];constants.workGroupOffset[0] = workGroupOffset[0];constants.workGroupOffset[1] = workGroupOffset[1];
...
// Dispatch//pCommandList->Dispatch(dispatchX, dispatchY, dispatchZ);