功能
性能分析
此功能支持捕获 GPU 配置文件,以在 Radeon GPU Profiler 中查看。
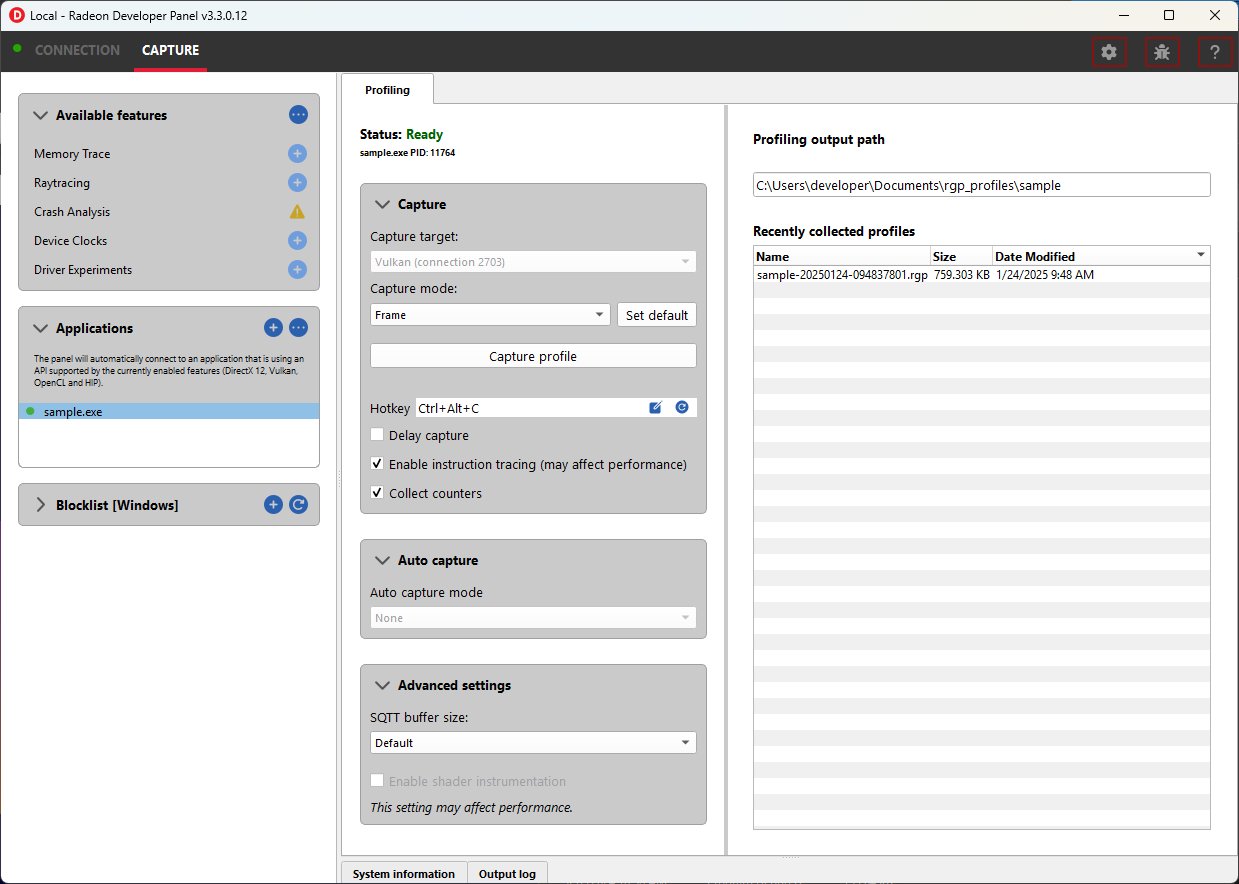
捕获 部分包含以下用于分析的项目
-
捕获目标 - 选择触发捕获时应进行分析的驱动程序连接。
-
捕获模式 - 显示有关应使用哪种分析捕获模式的选项
帧 - 捕获帧内发生的绘制和分派。
分派 - 捕获一定数量的分派。此选项使用“分派范围”自动捕获选项中的*分派计数*值。
-
捕获配置文件 - 捕获配置文件并写入磁盘。
-
启用指令跟踪 - 启用捕获详细指令数据。
-
收集计数器 - 启用捕获 GPU 缓存计数器数据。配备 AMD Radeon RX 6000、AMD Radeon RX 7000 或 AMD Radeon RX 9000 系列 GPU 的系统还将收集光线追踪计数器数据。
-
延迟捕获 - 如果启用此选项,按下“捕获配置文件”按钮或触发热键后,将首先等待输入的毫秒数,然后再捕获配置文件。
启用详细指令数据的捕获可能会对性能产生不利影响。
自动捕获 部分包含以下用于分析的选项
-
自动捕获模式:: - 显示用于自动捕获配置文件的配置选项。
-
无 - 点击捕获配置文件按钮时使用所选的捕获模式。
-
帧 - 允许指定一个特定的帧索引来触发捕获。
-
分派范围 - 允许设置在自动配置文件捕获期间使用的起始和停止分派索引。
-
分派计时器 - 允许在指定的时间后指定要捕获的分派数量。
-
高级设置 部分包含以下用于分析的选项
-
SQTT 缓冲区大小:: - 定义 SQTT 数据将存储的缓冲区大小。
-
如果配置文件中缺少数据,可以增加 SQTT 缓冲区大小来解决问题。
-
如果应用程序出现图形损坏,减小 SQTT 缓冲区大小可能会解决问题。
-
-
启用着色器插桩: - 启用对更详细着色器插桩数据进行捕获的支持。
为减少截断配置文件数据的可能性,OpenCL 分析限制为 10000 个分派
可以通过以下方式实现捕获配置文件
- 点击“捕获配置文件”按钮
点击“分析 UI”中的捕获配置文件按钮将捕获一帧并将结果写入磁盘。
- 使用 Ctrl-Alt-C 热键
在 Windows 或 Linux® 上使用 Ctrl-Alt-C 默认热键将捕获一帧并将结果写入磁盘。
可以在启动应用程序之前,通过点击热键标签右侧的编辑按钮,然后输入一系列按键来配置此项。
示例输出
sample-20200908-092653.rgp
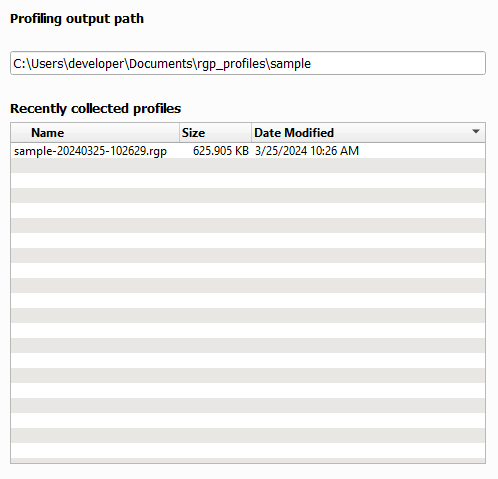
配置文件将输出到磁盘,路径在下方的配置文件输出路径字段中指定。
内存跟踪
此功能支持捕获内存跟踪,以在 Radeon Memory Visualizer 中查看。
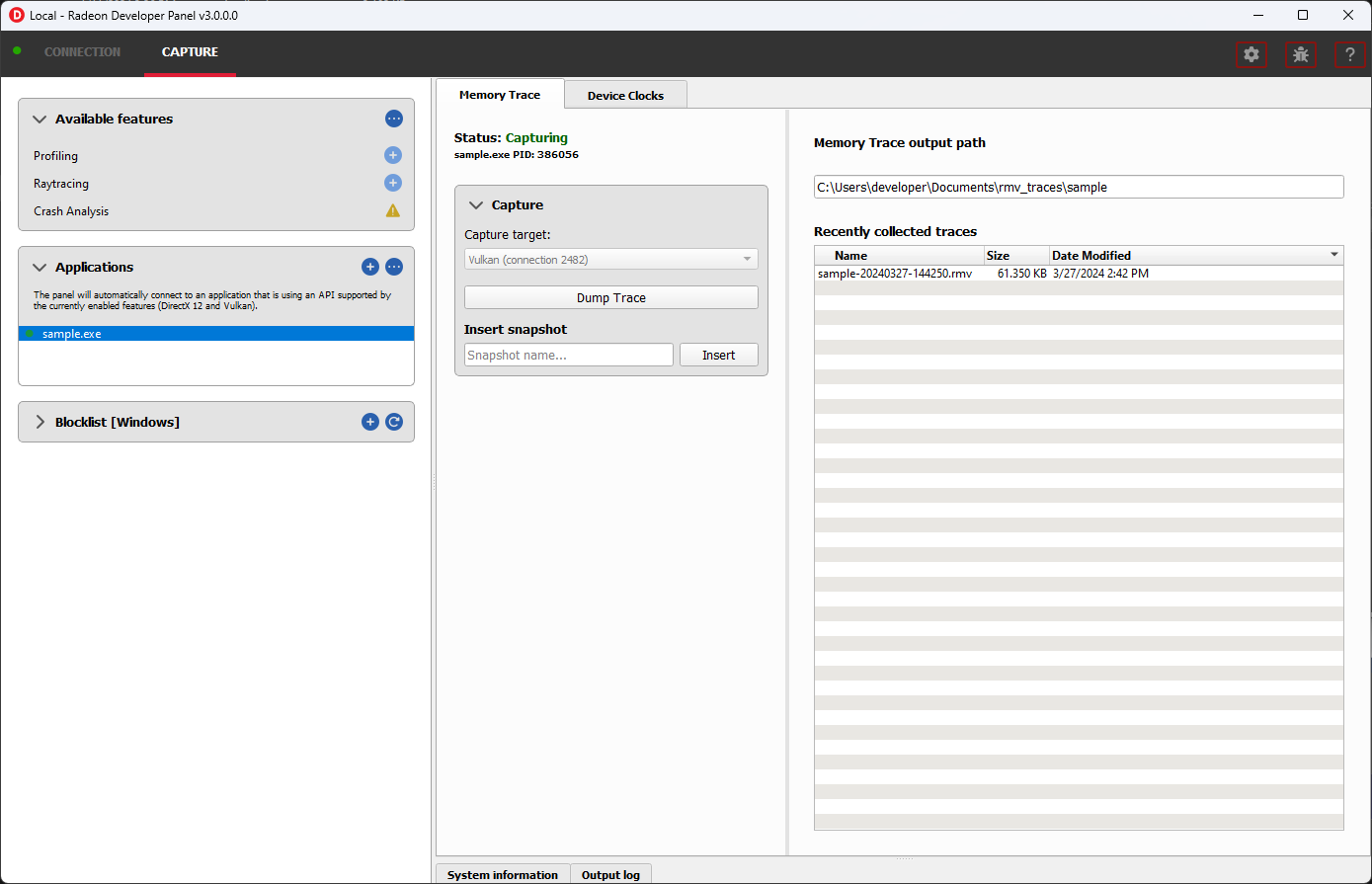
启动应用程序时已隐式开始内存跟踪。
捕获 部分包含以下用于内存跟踪的项目
-
捕获目标 - 选择按下转储按钮时应转储其内存的驱动程序连接。
-
转储跟踪 - 停止选定捕获目标的内存跟踪并将结果写入磁盘。
-
插入快照 - 插入用户指定的标识符来定义跟踪中的快照。快照捕捉一个时间点,方式与照片类似。例如,要查找内存泄漏,可以添加 2 个快照;一个在游戏关卡开始之前(在菜单屏幕之后),另一个在用户返回游戏菜单之后(游戏关卡结束时)。理论上,游戏在两种情况下(游戏关卡之前和之后在菜单中)的状态应该是相同的。
-
最近收集的跟踪 - 显示输出目录中最近收集到的所有跟踪。
可以通过以下任一方式将内存跟踪写入文件
- 关闭正在运行的应用程序
当客户端应用程序终止时,内存跟踪将停止,并将结果写入磁盘。
- 点击“转储跟踪”按钮
点击“内存跟踪 UI”中的转储跟踪按钮将停止内存跟踪并将结果写入磁盘。
通过上述任一方法完成内存跟踪将导致 Radeon Memory Visualizer 跟踪文件被写入磁盘。
示例输出
sample_20200316-143712.rmv
一旦内存跟踪完成(通过关闭应用程序或点击转储跟踪按钮),必须关闭并重新启动应用程序才能开始新的内存跟踪。
光线追踪
此功能支持捕获光线追踪场景,以在 Radeon Raytracing Analyzer 中查看。
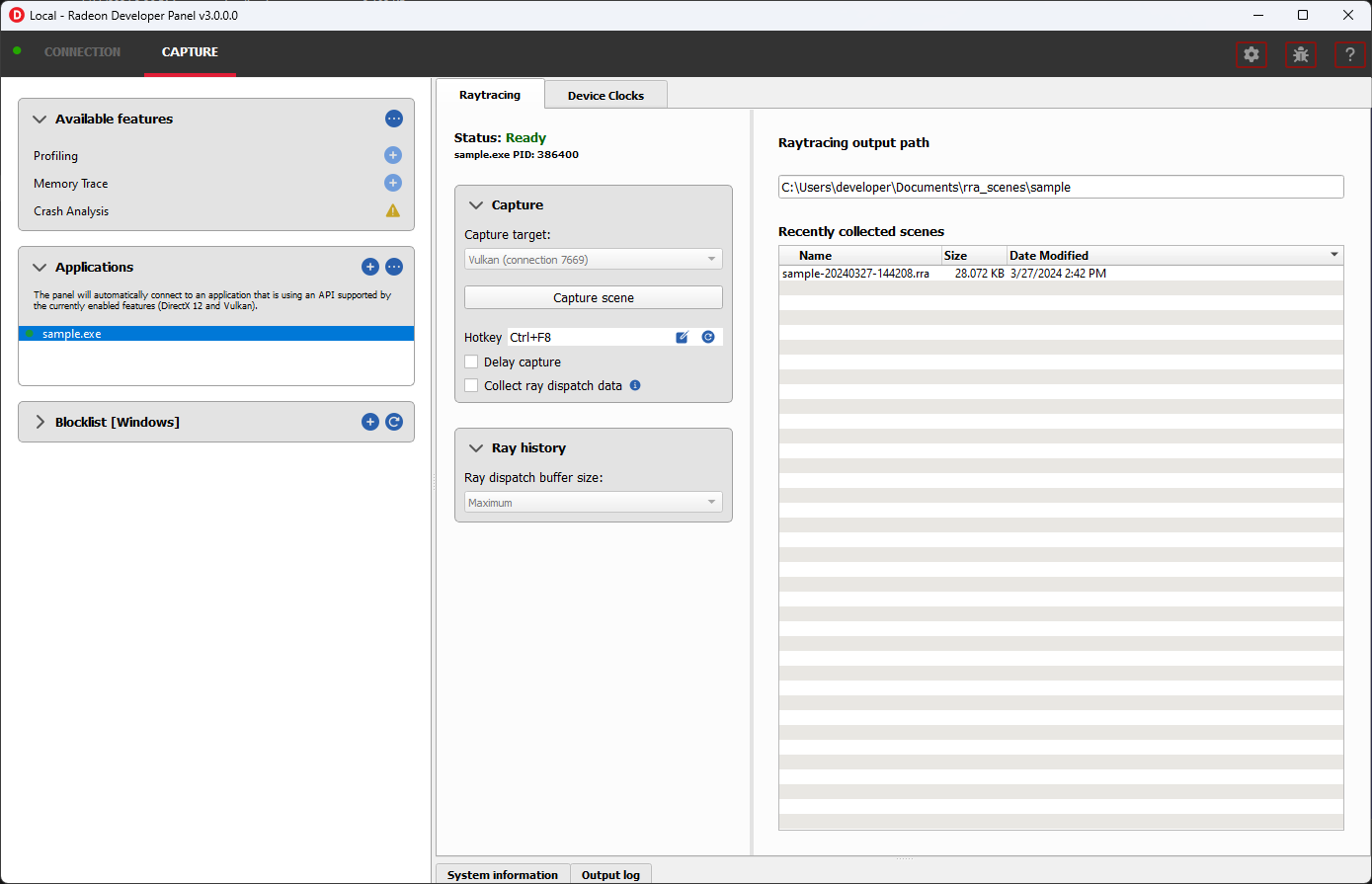
捕获 部分包含以下用于光线追踪的项目
-
捕获目标 - 选择当触发捕获时应捕获其光线追踪场景的驱动程序连接。
-
捕获场景 - 捕获场景并写入磁盘。
-
延迟捕获 - 如果启用此选项,按下“捕获场景”按钮或触发热键后,将首先等待输入的毫秒数,然后再进行捕获。
-
收集光线分派数据 - 捕获关于光线分派的详细信息。
此功能在 Linux 上目前处于实验阶段,在大多数情况下,要使其可靠运行,至少需要 16GB 的系统内存。
- 最近收集的场景 - 显示在输出目录中找到的任何最近收集的场景。
光线历史部分允许配置收集光线分派数据的设置
- 光线分派缓冲区大小:: - 定义在场景捕获期间用于分配光线分派数据的系统内存中的缓冲区大小。
可以通过以下方式实现捕获场景
- 点击“捕获场景”按钮
点击“光线追踪 UI”中的捕获场景按钮将捕获光线追踪场景并将结果写入磁盘。
- 使用 Ctrl-F8 热键
在 Windows 或 Linux® 上使用 Ctrl-F8 默认热键将捕获光线追踪场景并将结果写入磁盘。
可以在启动应用程序之前,通过点击热键标签右侧的编辑按钮,然后输入一系列按键来配置此项。
示例输出
sample-20220705-104021.rra
崩溃分析
此功能支持使用 Radeon GPU Detective 捕获 GPU 崩溃摘要。
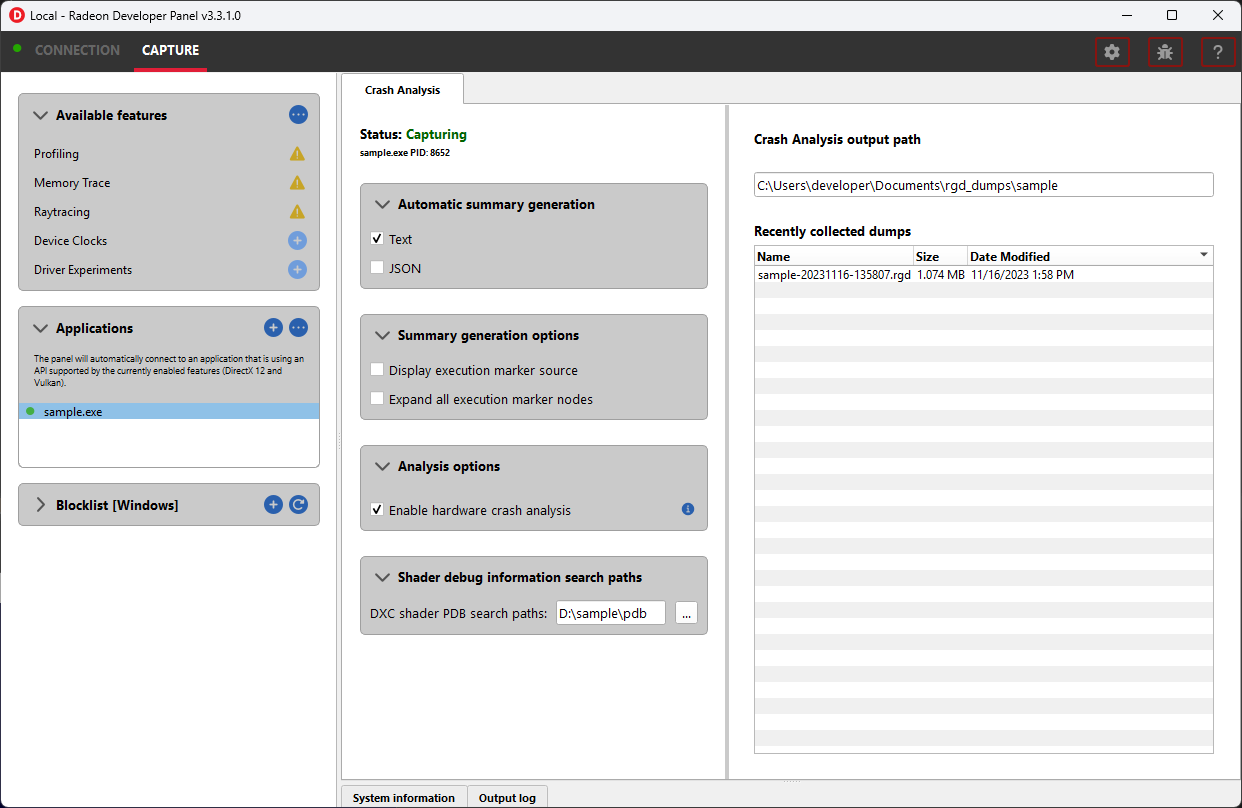
以下是崩溃分析功能支持的要求
操作系统: Windows® 10 或 Windows® 11
支持的 GPU: AMD Radeon RX 6000、AMD Radeon RX 7000 或 AMD Radeon RX 9000 系列 GPU
最低支持驱动程序: AMD Radeon Adrenalin 软件驱动程序版本 23.7.2
在运行应用程序生成崩溃转储之前,可以在此处所示的捕获设置窗格中配置一些设置
-
存储转储的目录 - 崩溃转储输出到的磁盘路径。
-
自动生成崩溃摘要
为方便起见,启用这些选项将在捕获后自动生成相应的崩溃转储摘要。
- 显示执行标记源
如果选中,生成的摘要文件的执行标记树中的每个标记节点都将包含一个指定生成标记的源(例如应用程序、驱动程序等)的标签。
- 展开所有执行标记节点
如果选中,所有执行标记节点将在标记树中展开。
分析选项部分列出了配置选项
- 启用硬件崩溃分析
启用后,RGD 会收集 GPU 硬件状态的低级信息,并在“崩溃分析 (.rgd)”输出文件中提供有意义的见解。
着色器调试信息搜索路径部分允许配置 DXC 着色器 PDB 文件搜索路径,这些路径将在生成崩溃转储时使用。
如果提供了 PDB 文件并且它们已成功关联,则 rgd.exe 可用相应的着色器入口点和源文件。有关更多信息,请参阅Radeon GPU Detective 文档。
激活后,发生 TDR 时将创建 GPU 崩溃转储。
示例输出
sample-20230220-103954.rgd
右键单击“最近收集的转储”窗格中的转储将在文本编辑器中打开一个上下文菜单,其中包含打开生成的崩溃摘要的选项。如果尚未生成摘要,将提供一个选项来使用 Radeon GPU Detective CLI 首先生成摘要,然后打开摘要。从该上下文菜单删除转储也将删除已生成的任何摘要。
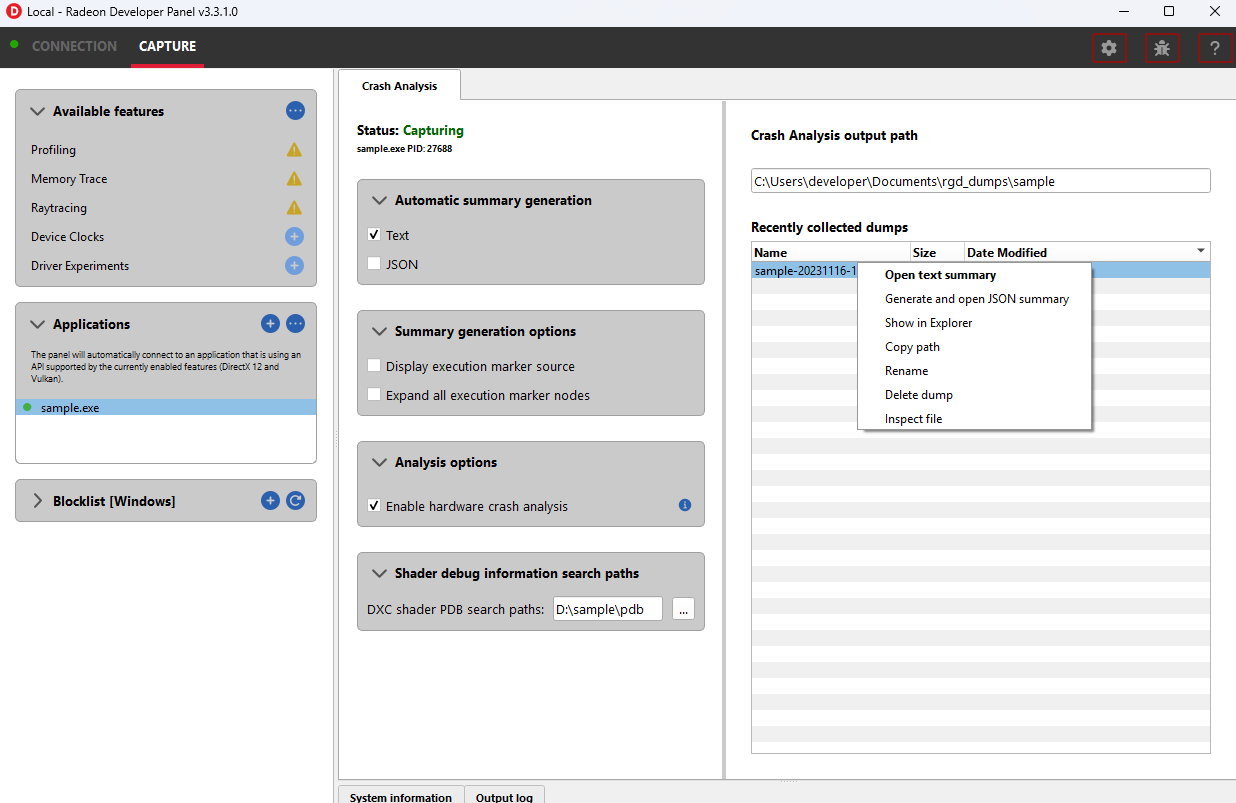
必须在设置配置中正确设置 Radeon GPU Detective 可执行文件路径才能生成崩溃摘要。
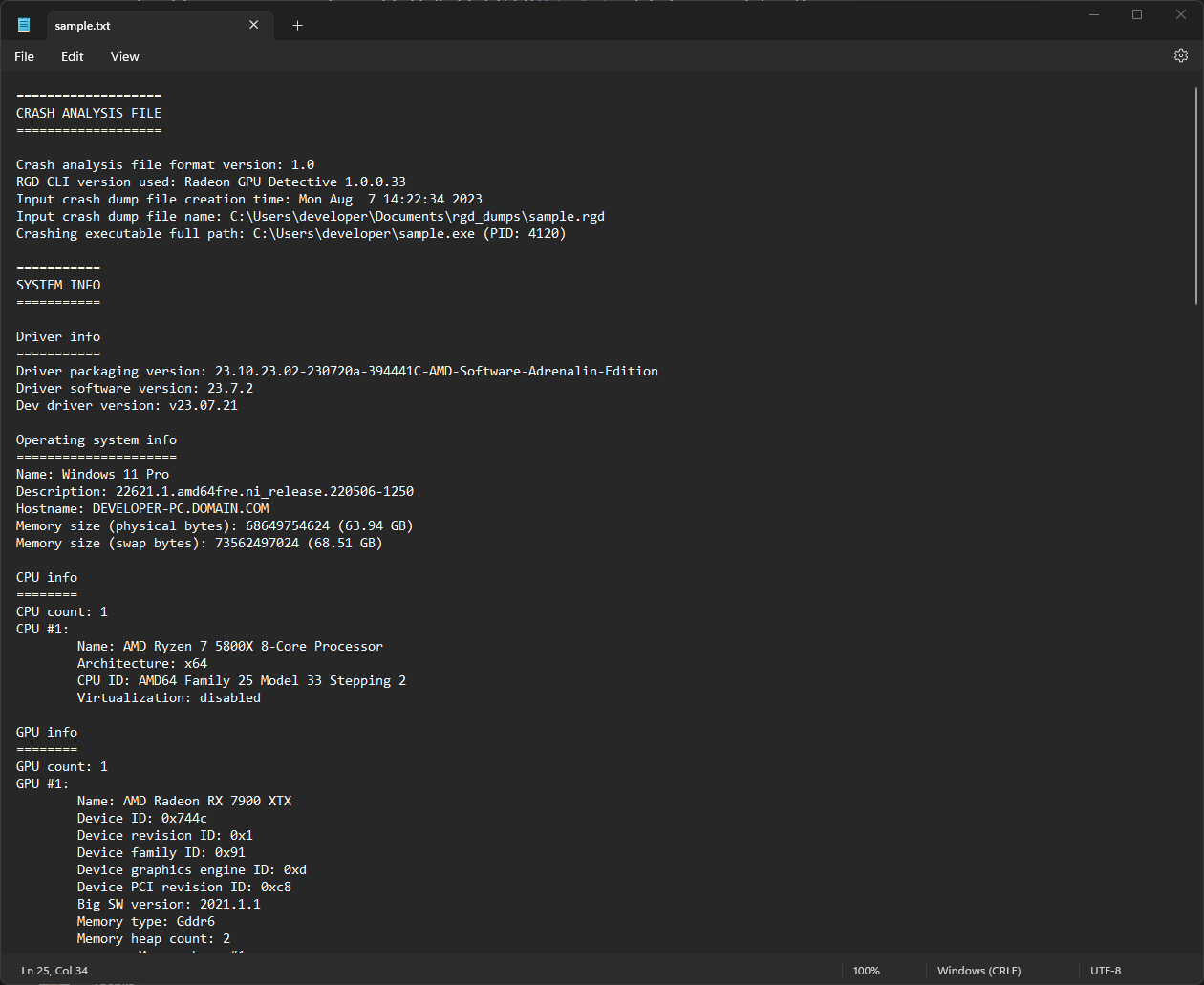
此处显示了一个示例崩溃转储摘要
驱动程序实验
驱动程序实验提供了一种更改游戏或其他图形应用程序的行为和性能特征的方法,而无需修改其源代码或配置。它们控制图形驱动程序的低级行为。此工具公开了一些以前仅对开发驱动程序的 AMD 工程师可用的驱动程序设置,例如禁用对光线追踪的支持或着色器编译器中的某些优化。实验是按图形 API(DirectX 12、Vulkan)分开的。两个 API 都提供了一组类似的实验,但并非所有实验都适用于每个 API。
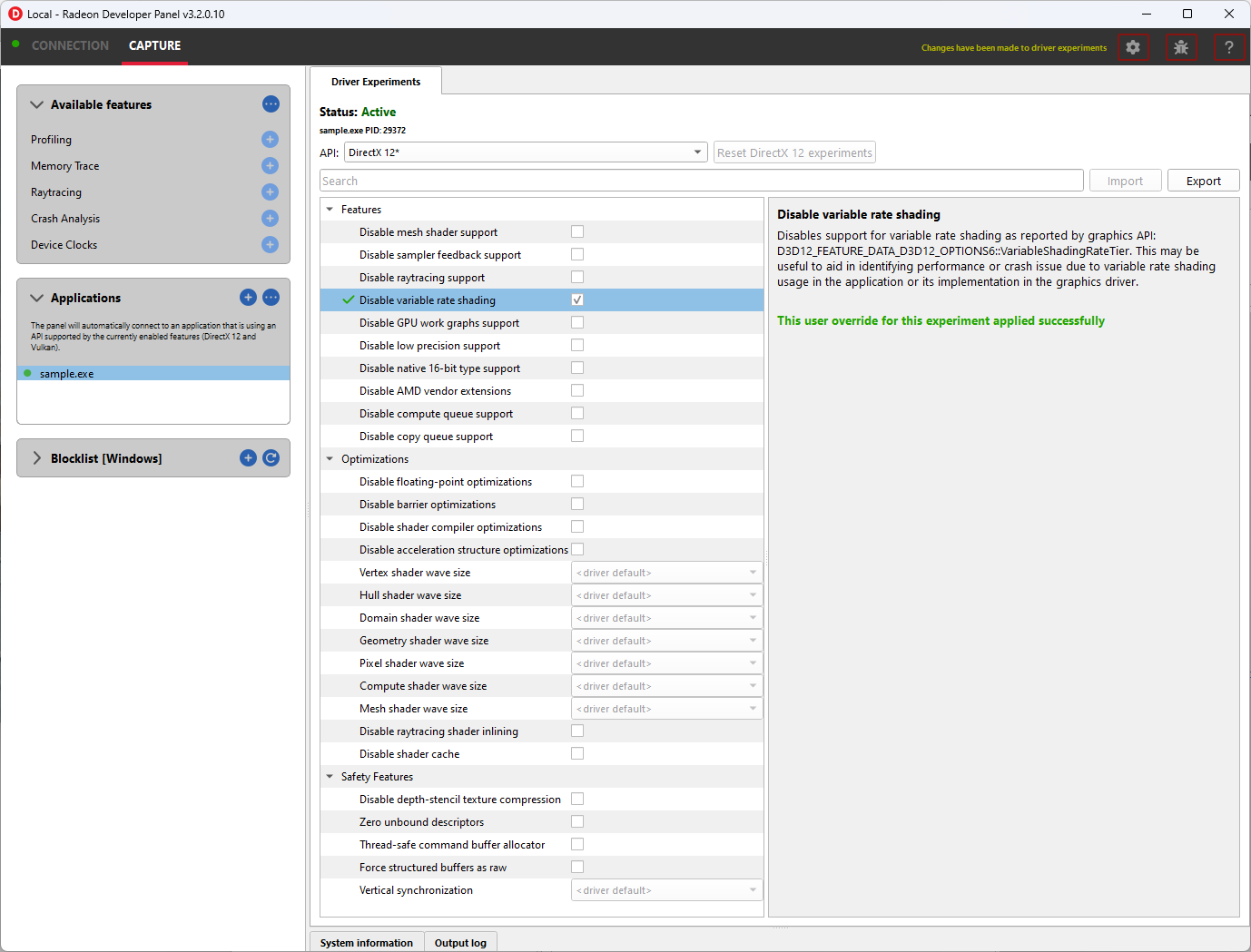
实验可以用作 Radeon Developer Panel 的唯一功能,也可以与其他功能一起使用。例如,在激活实验的同时进行 RGP 捕获将允许您观察实验如何影响某些特定渲染通道和绘制调用的性能。或者,您可以启用“崩溃分析”功能并捕获 RGD 崩溃转储。在各自的工具中打开带有活动驱动程序实验捕获的文件将显示一个通知,表明该文件是使用某些驱动程序实验捕获的,并列出了它们的值。

激活驱动程序实验
激活驱动程序实验后,所需的测试应用程序将需要连接到 Radeon Developer Panel 以应用这些实验。只要 Radeon Developer Panel 正在运行,实验就处于活动状态。关闭 Panel 应用程序或重启系统会将它们恢复为默认设置。
详细信息窗格将包含应用程序连接后选定实验状态的描述。在左侧实验列表的实验名称旁边也会显示一个相应的指示器
-
已修改:用户已提供实验的覆盖,但尚未在已连接的应用程序中应用。
-
已应用:用户覆盖已成功应用,驱动程序行为将得到更改。
-
应用失败:驱动程序未接受用户覆盖,驱动程序行为将保持不变。
-
不支持:驱动程序报告此实验当前不受支持。如果用户设置了该实验,则该值未在驱动程序中应用。
可以使用“导出”按钮将实验的用户覆盖保存到 JSON 文件,并稍后使用“导入”按钮加载。
可用驱动程序实验
功能
此组中的实验允许禁用对现代 AMD/Radeon GPU 的某些硬件功能的支持,这可能有助于调试。
禁用网格着色器支持
禁用采样器反馈支持
禁用光线追踪支持
禁用可变速率着色
禁用 GPU 工作图支持
这些实验使得图形 API 无法公开对新 GPU 硬件功能的支持,例如 D3D12_FEATURE_DATA_D3D12_OPTIONS7::MeshShaderTier,或等效的 Vulkan 扩展,例如 VK_EXT_mesh_shader,就好像 GPU 不支持该功能一样。
通常不使用该功能的应用程序会回退到其他实现,例如使用顶点着色器代替网格着色器,或使用屏幕空间反射代替光线追踪反射。如果应用程序代码中存在使用该功能但导致其崩溃或返回不正确结果的错误,则禁用该功能可以进行测试。例如,如果一个应用程序正在崩溃,并且启用“禁用光线追踪支持”实验可以缓解崩溃,那么可以推断光线追踪代码是导致崩溃的原因。
禁用低精度支持
在着色器中,当用作最小精度数字时,禁用对 16 位浮点数(半精度浮点数)的支持。HLSL 中的最小精度数字,如 min16float 类型,允许声明变量,在这些变量中 16 位精度足够。如果半精度浮点数在某些操作中不受支持,或者会提高性能,则着色器编译器将使用完整的 32 位(单精度)浮点数。激活此实验后,将不支持最小精度数字(D3D12_FEATURE_DATA_D3D12_OPTIONS::MinPrecisionSupport),着色器中的此类数字将回退到使用完整的 32 位精度。
在某些情况下,在着色器中使用半精度浮点数可以提高性能,因为计算速度更快且存储需求更小,但它也可能导致错误。16 位浮点数仅保留大约 3 位小数精度,只能精确表示高达 2048 的整数。此外,16 位浮点数的最大值为 65504,超过此值将变为无穷大。这可能足以对 HDR 颜色或法线向量进行计算,但不足以对顶点位置和许多其他类型的数据进行操作。中间计算很容易超出最大值,例如在两个向量的点积中。如果激活此实验解决了在着色器中看到计算结果不正确、NaN 或 INF 值的问题,那么很可能应该修改着色器以使用完整精度(float)。它也可能表明着色器编译器存在错误,尽管可能性较小。
禁用本机 16 位类型支持
此实验禁用了对着色器中显式 16 位数据类型的支持(D3D12_FEATURE_DATA_D3D12_OPTIONS4::Native16BitShaderOpsSupported),该类型在着色器模型 6.2 中可用,例如 float16_t 类型。激活此实验后,应用程序将无法使用利用本机 16 位类型的着色器,并且应回退到使用完整精度数字的实现。如果激活此实验修复了错误,则可能表明 16 位版本的着色器存在错误。可能,16 位数字的精度或范围不足以进行某些计算。它也可能表明着色器编译器存在错误,尽管可能性较小。
禁用 AMD 供应商扩展
激活此实验将禁用对图形 API 的自定义 AMD 扩展的支持。在 DirectX 12 中,这意味着通过 AMD GPU Services (AGS) 库(AGSDX12ReturnedParams::ExtensionsSupported)可用的扩展将被返回为不支持。在 Vulkan 中,这意味着 VK_AMD_ 和 VK_AMDX_ 前缀的设备扩展不可用。
如果应用程序使用了此类自定义供应商扩展,此实验可以帮助进行调试。激活此实验后修复了错误,表明问题可能在于其中一个扩展的错误使用。
禁用计算队列支持
激活此实验后,Vulkan 实现将不公开仅计算队列。就好像 GPU 不支持异步计算队列一样;对于设置了 QUEUE_COMPUTE_BIT 但未设置 QUEUE_GRAPHICS_BIT 的队列族,queueCount 将为零。Vulkan 应用程序通常应做好准备,并回退到仅在图形队列上执行其工作负载的实现。
在 DirectX 12 中,无法公开异步计算队列不支持的情况。激活此实验后,GPU 将在图形队列上执行提交到计算队列的所有命令,并与图形工作负载串行化。
此实验可用于调试异步计算相关问题。如果激活它修复了错误,可能表明存在同步问题或图形队列上执行的 3D 工作负载(绘制调用)与计算队列中并行运行的计算分派之间的资源访问问题。
禁用复制队列支持
在 DirectX 12 中激活此实验会使提交到复制队列的所有复制命令在图形队列上执行,这有助于调试在多个队列上并行运行的工作负载的同步问题。
优化
此组中的实验修改了着色器编译器和通用驱动程序行为,以提高性能。虽然优化不应改变逻辑,但在某些情况下禁用它们可能有助于调试各种类型的问题。
禁用浮点优化
激活时,编译器会跳过着色器代码中与浮点数计算相关的某些优化,例如将 MUL + ADD 指令合并为 FMA 指令。虽然通常优化不应改变编译器逻辑,但它们可能会改变某些操作的精度,因此数值结果与未优化版本在最低有效位上可能不是完全相同的。如果激活此实验修复了错误(例如,仅位置着色器与完整顶点着色器之间数值结果的差异),则可能表明应用程序过度依赖计算精度。更改着色器代码中的某些表达式可能会有所帮助。它也可能表明着色器编译器存在错误,尽管可能性较小。
禁用着色器编译器优化
激活时,该实验会禁用着色器编译器优化,这可能导致着色器代码不够优化。这可能会导致着色器运行时间更长。
如果启用此实验修复了错误,则可能表明该错误与各个绘制调用的时序有关。这可能是同步问题,例如缺少屏障。它也可能表明着色器编译器存在错误。
禁用屏障优化
此实验禁用了驱动程序在同步和绘制调用之间的屏障级别所做的一些优化。默认情况下,驱动程序通过插入细粒度的屏障来最大限度地优化命令执行,以同时确保正确性和最大性能。例如,像素着色器可能需要等待前一个绘制调用的像素着色器完成,但该绘制调用的顶点着色器可以更早开始执行。此实验禁用了其中一些优化,这可能会降低性能。如果激活此实验修复了错误,则可能表明同步存在错误,例如缺少或错误的屏障。
禁用加速结构优化
此实验禁用驱动程序在构建光线追踪加速结构时所做的一些优化,这可能会增加其内存占用并降低光线追踪中的遍历性能。它不应改变逻辑。
如果激活此实验可以修复 bug,则可能表明应用程序错误地处理了光线追踪分派之间的同步(例如,缺少或错误的 barrier)。它也可能表明应用程序没有正确处理加速结构所需的增大尺寸或用于构建它们的 scratch buffer。虽然可能性较小,但也可能表明驱动程序存在 bug。
顶点/hull/… 着色器 wave 大小
AMD RDNA 架构支持每个 wave 32 或 64 个线程。在编译每个着色器时,着色器编译器将使用启发式方法来确定使用每个 wave 32 或 64 个线程,以达到最佳性能。此实验允许在可能的情况下,为特定的着色器阶段(例如,顶点或像素着色器)强制执行特定的着色器编译模式。这不应改变逻辑,但会影响性能。
如果一个着色器使用了显式的 wave 函数(在 Vulkan 中称为 subgroup 函数),例如 WaveReadLaneFirst,并且切换此实验可以修复 bug,这可能表明该着色器依赖于特定的 wave 大小才能正常工作,而这不应该是其应该依赖的。虽然可能性较小,但也可能表明着色器编译器存在 bug。
还可以使用此实验来比较具有不同 wave 大小的相同着色器的 draw call 的执行性能。如果性能分析(例如,使用 RGP)显示驱动程序选择的 wave 大小对于特定着色器来说不是最佳的,您可以使用 Shader Model 6.6 的 [WaveSize()] 属性来准备一个具有显式 wave 大小的着色器优化版本,以便在可能时使用。
在某些情况下,此实验对某些着色器没有影响,因为驱动程序会进行覆盖。您可以使用运行时工具(如 Radeon GPU Profiler)来确认此实验已激活并作用于硬件。
禁用光线追踪着色器内联
AMD GPU 上的 DXR 着色器可以有两种模式进行编译。在 RGP 或 RRA 等工具中,可以将其观察为:
-
<Indirect>:单独的光线生成、最近命中、任意命中、丢失着色器等保持独立,被调用和返回。
-
<Unified>:参与光线追踪管线的全部着色器被内联在一起,这可能会增加编译管线状态对象(PSO)所需的时间,但可能会提高该着色器的执行性能。
此决策由着色器编译器基于一些启发式方法做出,以达到最佳性能。这不应改变逻辑。此实验强制编译器始终选择 Indirect 模式。
如果激活此实验缩短了游戏启动和加载的时间(在创建管线状态对象 PSOs 时),则表明创建光线追踪 PSOs 占用了大量时间。为了最快的加载时间,PSO 创建应在多个后台线程中进行。
如果激活此实验修复了 bug:CPU 在 PSO 创建时崩溃或挂起、GPU 在着色器执行时崩溃,或返回了不正确的结果,则表明着色器编译器存在 bug。
禁用着色器缓存
着色器编译分为两个阶段。
- 首先,高级着色语言(HLSL 或 GLSL)被编译为独立于 GPU 的中间表示,由图形 API 定义(DirectX 12 中的 DXIL,Vulkan 中的 SPIR-V)。这应该在应用程序准备发布给最终用户时离线进行。
- 第二阶段发生在图形驱动程序中,当创建管线状态对象 (PSO) 时。然后,将中间表示编译为适合特定 GPU 的汇编 (ISA)。这通常在运行时发生(例如,当游戏启动或加载关卡时),并且可能花费大量时间。为了优化此过程,编译后的着色器会被驱动程序缓存。
此实验禁用了驱动程序实现的着色器缓存。这不应改变逻辑,但会影响 PSO 创建的持续时间。
如果激活此实验使应用程序启动和加载时间大大延长,则表明应用程序 PSOs 的创建花费了大量时间,而这些时间通过缓存得到了优化,但新用户在首次启动应用程序时会遇到这种情况。激活此实验将使 PSO 的行为类似于从未运行过该应用程序的系统。这可以提供对冷着色器缓存的应用程序启动时间的更可靠的测量。
安全功能
此组中的实验通常提供额外的安全功能,这些功能可能会降低性能,但可以使应用程序更加正确和稳定。激活安全功能有助于暴露代码中可能导致应用程序不稳定的错误。
单独提交命令缓冲区
单独提交每个命令缓冲区以在 GPU 上执行 - 禁用在单个提交调用中链接多个命令缓冲区,因此即使它们是单个提交的一部分,它们也不会并发执行。
强制 NonUniformResourceIndex
强制着色器编译器将所有动态描述符索引视为已用 NonUniformResourceIndex 进行了修饰。这有助于识别着色器中缺少 NonUniformResourceIndex 使用但索引为非统一的 bug。
将上传堆放在显存中
启用对 CPU 可见的显存的自动使用,该显存优先于系统内存,供 UPLOAD 堆中创建的资源使用。这有助于识别通过在 GPU_UPLOAD 堆中创建一些缓冲区来提高 GPU 数据上传性能的机会。
禁用颜色纹理压缩
GPU 使用内部压缩格式来处理纹理。这不应与通用数据压缩文件格式(如 ZIP)或算法(如 Deflate)混淆,也不应与显式块压缩纹理像素格式(如 BC6、ASTC)混淆。内部压缩格式是无损的,对开发者是透明的,用于提高性能。内部压缩格式通常会增加纹理大小,而不是减小,因为需要额外的空间来存储元数据。这种压缩通常用于渲染目标和深度模具纹理。驱动程序会基于一些启发式方法来决定是否压缩纹理,以达到最佳性能。这可以在 RGP 的“Render/depth targets”选项卡中的 DCC 列中观察到。
压缩纹理可能对错误数据更敏感。纹理必须使用 Clear、Copy 或 DiscardResource 操作正确初始化,以便压缩元数据有效。不使用这些操作会导致未定义的结果,因为纹理可能被创建在可能包含垃圾数据的内存位置,例如,被创建在比之前存在的其他资源更大的内存堆中,或者与在每个渲染帧的不同时间段使用的其他资源进行内存别名。使用着色器作为渲染目标或 UAV 覆盖整个纹理不被视为正确初始化。在这种情况下,可能会出现视觉伪影,甚至导致 GPU 崩溃。
此实验会禁用除深度模具纹理(通常是渲染目标)以外的纹理的压缩。如果激活此实验可以修复视觉伪影等 bug,则表明纹理初始化不正确——缺少 Clear、Copy,或者缺少或错误的 barrier。
禁用深度模具纹理压缩
此实验禁用深度模具纹理的内部压缩。如果激活它修复了与渲染不正确相关的 bug,则表明深度模具纹理的初始化缺失或不正确。
在 RDNA 2 卡(AMD Radeon RX 6000 系列)上,在某些情况下,由于驱动程序覆盖,此实验对某些纹理没有影响。您可以使用运行时工具(如 Radeon GPU Profiler)来确认此实验已激活并作用于硬件。
未绑定描述符归零
此实验使用零初始化未绑定描述符。如果启用它修复了 bug,则可能表明应用程序正在访问未绑定的描述符表。
线程安全的命令缓冲区分配器
命令缓冲区分配器对象不是线程安全的,应一次仅从一个线程访问。当应用程序使用命令缓冲区的并行录制或多线程时,它通常为每个线程使用一个单独的命令分配器。
此实验使命令分配器线程安全,内部进行同步。如果激活它修复了 bug,则可能表明 bug 与使用命令分配器和命令缓冲区的线程之间的同步相关。
强制结构化缓冲区为原始
结构化缓冲区定义了一个步长,即单个结构实例所需的字节数,或者使用指针移动到下一个结构实例的步数。在为结构化缓冲区创建着色器资源视图 (SRV) 描述符时会传递此参数,但特定大小的结构也会在着色器代码中为要绑定到特定着色器资源槽的该结构化缓冲区进行声明。这两者应该匹配。如果不匹配,结果是未定义的,并且可能因 GPU 而异。
此实验强制 GPU 使用着色器中的步长而不是描述符。如果激活它修复了 bug,则可能表明 bug 是由应用程序代码或着色器代码中结构化缓冲区的声明不正确引起的。它也可能表明正在意外地使用原始缓冲区而不是结构化缓冲区。
垂直同步
垂直同步 (V-sync) 是游戏常用的设置,用于控制帧在屏幕上的显示行为。
关闭时,帧会在准备好时(渲染完成时)立即显示。它通常会提高每秒帧数 (FPS),使 GPU 更繁忙,最高可达 100%(如果游戏未受 CPU 工作负载限制),但可能会在屏幕上暴露一种称为撕裂的不愉快视觉效果。此模式非常适合在最大负载下测试系统和游戏,以及进行性能测量。
开启时,新帧仅在显示器准备好显示它们时才会显示。然后 FPS 将限制在显示器的刷新率(典型显示器为 60 Hz),GPU 负载较低,电池使用量较低,因为游戏被阻塞并等待下一帧渲染和显示。这消除了撕裂效果,因此此模式适合正常游戏。
V-sync 通常由应用程序控制。此实验允许覆盖它并强制将其打开或关闭。这允许对不提供 V-sync 控制的应用程序进行各种目的的测试。例如,如果强制开启 V-sync 修复了 bug,则可能表明 bug 对 draw call 和渲染通道的时间敏感,这可能是由渲染帧、命令缓冲区提交、present 调用等不正确的 CPU-GPU 同步引起的。如果强制 V-sync 开启修复了整个系统崩溃或关机的问题,则可能表明 GPU 或 CPU 过热存在问题。
设备时钟
Radeon Developer Panel (RDP) 允许开发人员选择多种时钟模式。
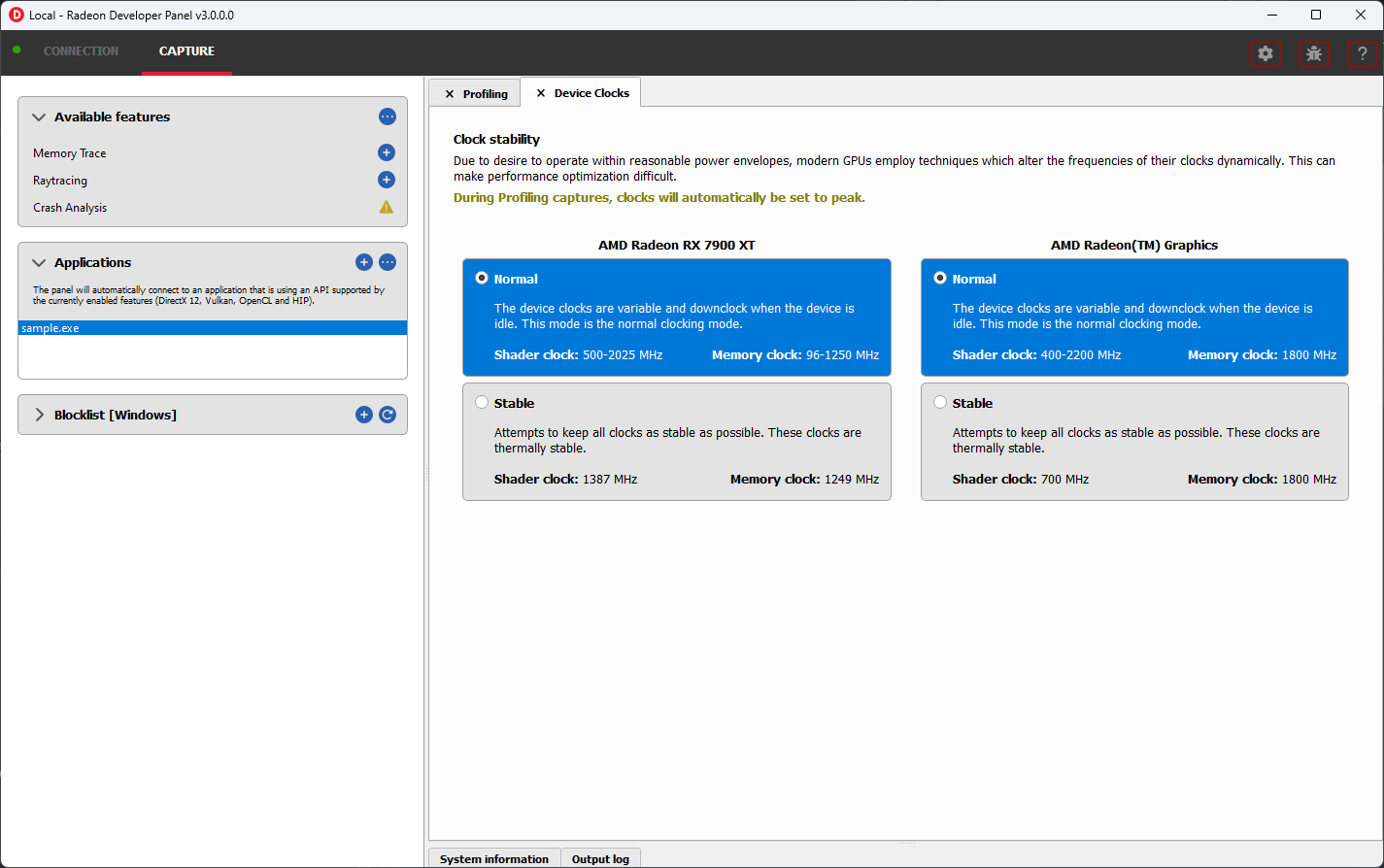
正常时钟模式将使 GPU 正常运行您的应用程序。为确保 GPU 在其设计的功耗和温度范围内运行,它会动态调整内部时钟频率。这意味着同一应用程序的性能剖析可能差异很大,使得并排比较变得不可能。
稳定时钟模式将以较低的固定时钟速率运行 GPU。尽管应用程序的运行速度可能比正常情况慢,但比较同一应用程序的性能剖析会容易得多。
在捕获 RGP 性能剖析时,设备的时钟模式将更改为峰值以进行捕获。