事件窗口
RGP 的这个部分是用户进行大部分事件级别分析的地方。RGP 事件只是在应用程序或驱动程序发出的命令缓冲区中的一个 API 调用。
事件窗口允许过滤事件字符串。事件字符串由事件索引、API 调用和参数组成。只有包含过滤字符串的事件才会显示。这对整个事件字符串都有效,而不仅仅是事件索引。例如,如果过滤字符串是“8”,则事件 31 可能会显示,如果它的任何参数包含“8”。
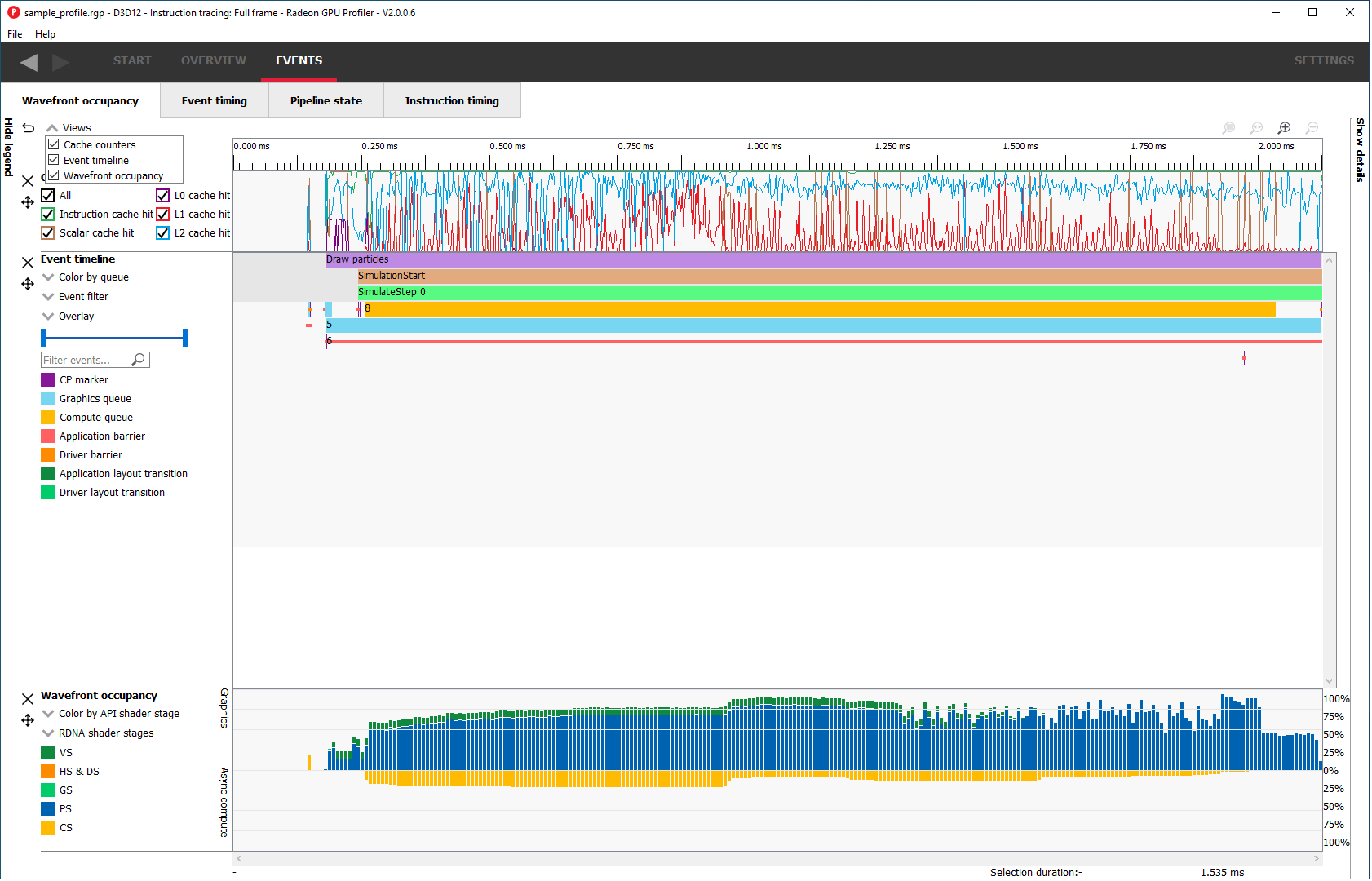
Wavefront 占用率
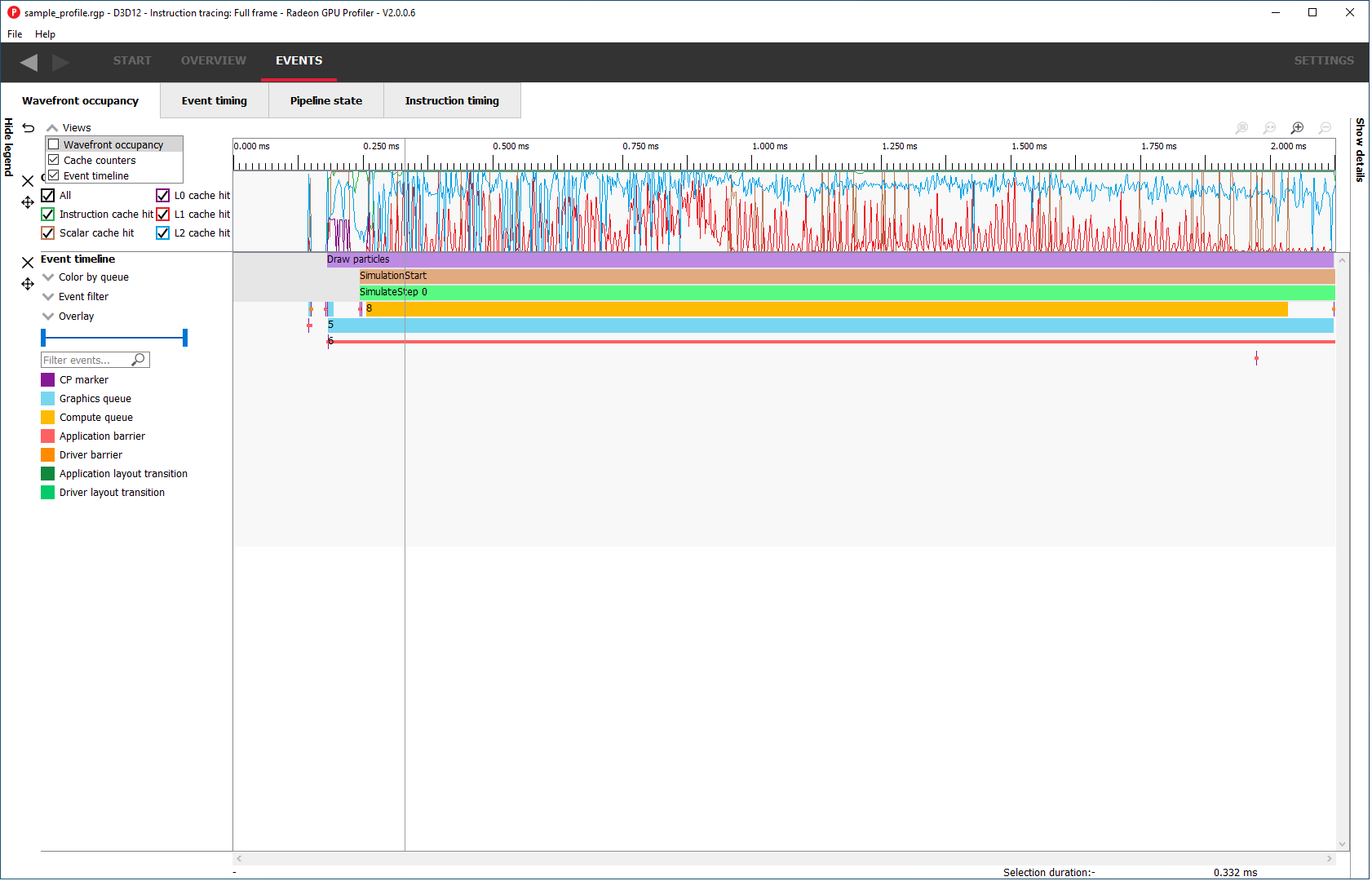
本节为用户提供了一个交互式时间线,显示 GPU 利用率、GPU 计数器数据以及配置文件中的所有事件。
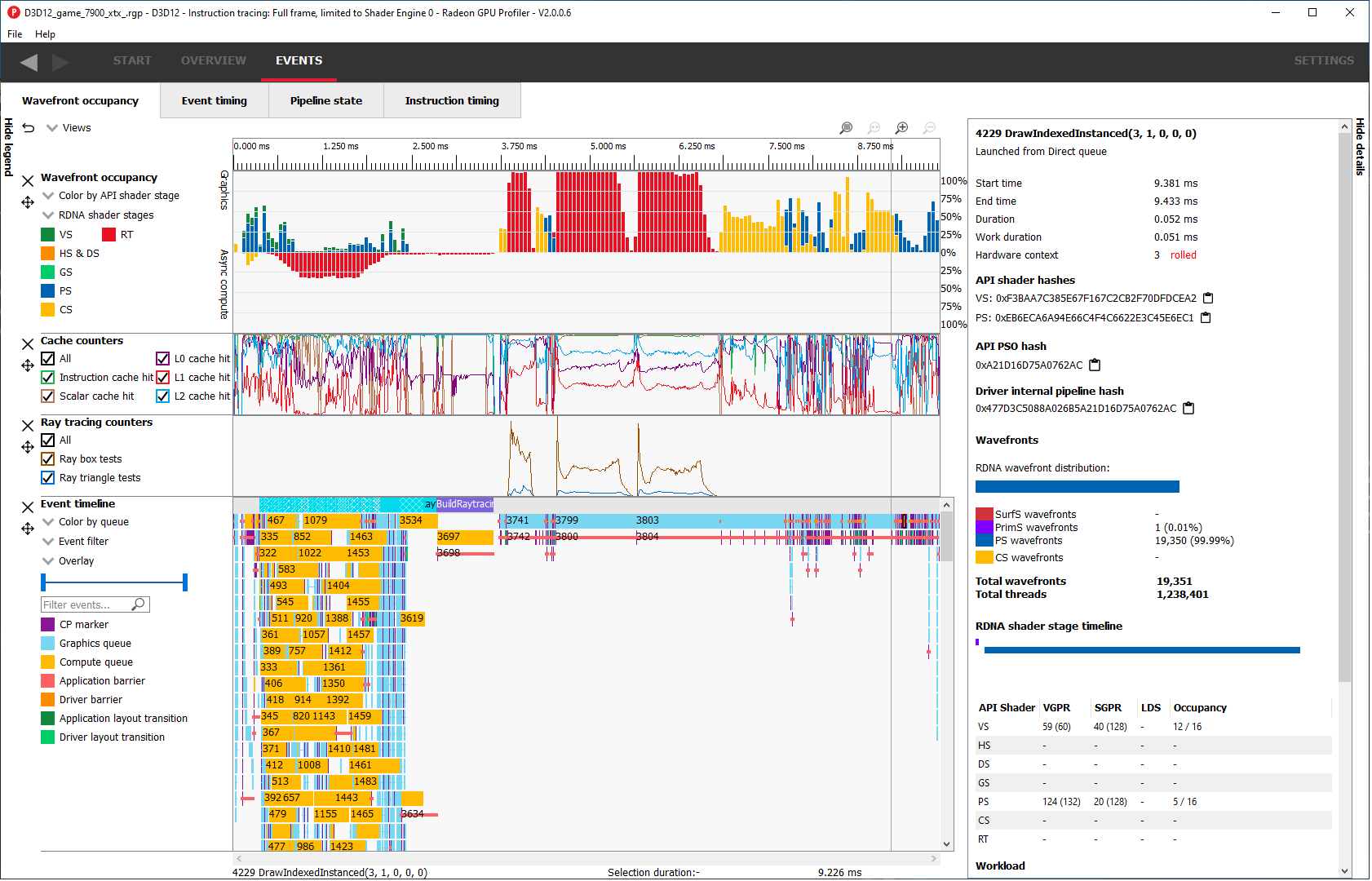
有五个组成部分:图例侧边栏、Wavefront 时间线视图、一个或多个计数器视图、事件时间线视图和详细信息侧边栏。
请注意,只有在 RDP 中启用“收集计数器”复选框时,计数器视图才可用。
图例侧边栏
按左上角的“隐藏图例”将隐藏带有可视化控件的侧边栏以及每个视图的颜色编码图例。每个单独图例的内容取决于其视图。
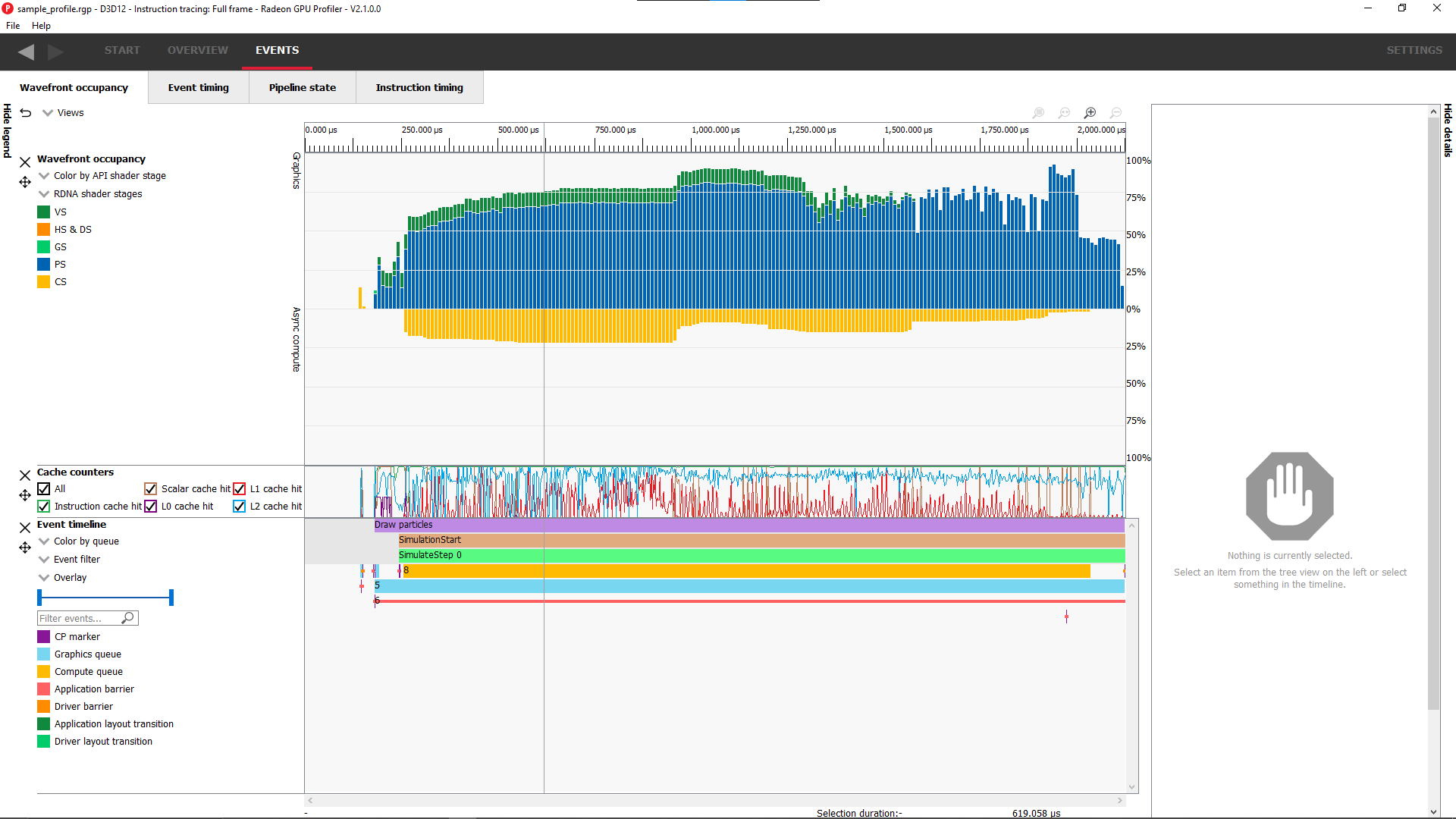
Wavefront 时间线视图
此部分显示了有多少 wavefront 正在运行。所有 wavefront 都被分组到由垂直条表示的存储桶中。上半部分显示图形队列上的 wavefront,下半部分显示异步计算队列上的 wavefront。

用户可以通过选择图中的范围并使用选项卡右上角的缩放按钮来检查区域。用户还可以将鼠标悬停在此视图上并使用鼠标滚轮进行缩放,以便在特定点上居中。可以通过使用鼠标按钮拖动以选择所需区域来选择一个 wavefront 区域,如下所示。

您可以通过选择 Ctrl + Z 或单击“放大到选择”来放大该区域(结果如下所示)。

如果您已放大,您也可以拖动图形。首先按住空格键,然后按住鼠标按钮。图形现在将随鼠标移动。
用户可以使用 Wavefront 占用率图例顶部的“按...着色”组合框以不同的方式可视化 wavefront。
-
按 API 阶段着色。 默认。显示哪些 wavefront 对应于哪个 Vulkan/DX12 管道阶段。
-
按 RDNA(或 GCN)着色器阶段着色。 显示哪些 wavefront 对应于哪个 RDNA/GCN 管道阶段。
-
按硬件上下文着色。 显示 wavefront 在哪个硬件上下文(0-7)上运行。这有助于可视化发生的上下文切换次数。
-
按限制因素着色。 显示该着色器占用率的限制因素。
-
按着色器引擎着色。 显示 wavefront 在哪个着色器引擎上运行。
-
按事件着色。 显示哪些 wavefront 对应于配置文件中的哪个事件。每个事件都被分配了唯一的颜色。
-
按通道着色。 根据渲染目标或附件类型(颜色、仅深度、计算、光线追踪)将 wavefront 分组到不同的通道中。这四种类型被分配了基本颜色,每种类型的每个通道被分配了该基本颜色的不同阴影。这有助于可视化应用程序尝试渲染场景的不同部分的时间。
-
按 API PSO 着色 根据着色器的 API PSO 哈希值显示哪些 wavefront 对应于哪个着色器。
-
按光线追踪着色 显示哪些 wavefront 对应于执行光线追踪的着色器。传统光线追踪事件的 wavefront 以及具有内联光线追踪的着色器的 wavefront 将使用指定的光线追踪颜色显示。所有其他 wavefront 将显示为灰色。
-
按间接命令着色 显示哪些 wavefront 对应于配置文件中的哪个间接命令。每个间接命令都被分配了唯一的颜色。所有其他 wavefront 将显示为灰色。
颜色模式可以跨 Wavefront 占用率和事件时间窗进行同步。为此,只需按住 Ctrl 键即可从任何“按...着色”组合框中选择模式。选定的颜色模式将用于 Wavefront 时间线和 Wavefront 占用率窗格中的事件时间线,以及事件时间窗格。
在“按...着色”组合框下方是另一个组合框,用于帮助可视化某些 RDNA 或 GCN 管道阶段的占用率。在管道阶段组合框下方是一个颜色编码的图例,用作颜色提醒。请注意,这些颜色可以在设置中自定义。
OpenCL、HIP 或纯计算 DirectX 和 Vulkan 的 RGP wavefront 占用率在 wavefront 占用率中只有计算。这是因为像 OpenCL 或 HIP 这样的计算 API 只分派计算着色器 waves。出于同样的原因,许多着色选项(例如硬件上下文和 RDNA/GCN 阶段)不适用于纯计算配置文件。

缓存计数器
本节可视化了在分析过程中收集的缓存计数器数据。缓存计数器数据仅在 Radeon RX 5000 系列及更新的 GPU 上可用。在分析过程中,计数器数据以固定速率采样,大约每 4096 个时钟周期采样一次。

每个计数器都显示为折线图,显示该特定计数器的值在整个帧中的变化情况。通过将计数器数据与 wavefront 占用率和帧中的事件相关联,您可以更好地了解帧的不同部分如何有效利用各种 GPU 缓存。
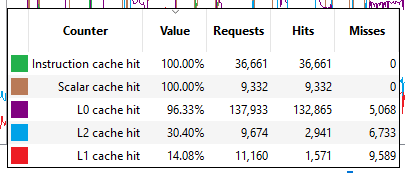
目前有五个缓存计数器在分析过程中收集。每个缓存计数器报告命中率,即请求命中缓存中已有数据的百分比。
-
指令缓存命中 命中了指令缓存中数据的读取请求的百分比。指令缓存为正在执行的着色器提供着色器代码。每个请求的大小为 64 字节。
-
标量缓存命中 来自正在执行的着色器代码的读取请求命中了标量缓存中数据的百分比。标量缓存包含在 wavefront 中不因每个线程而异的数据。每个请求的大小为 64 字节。
-
L0 缓存命中 命中了 L0 缓存中数据的读取请求的百分比。L0 缓存包含向量数据,这些数据可能因 wavefront 中的每个线程而异。每个请求的大小为 128 字节。
-
L1 缓存命中 命中了 L1 缓存中数据的读取或写入请求的百分比。L1 缓存由单个着色器引擎中的所有 WGP 共享。每个请求的大小为 128 字节。
-
L2 缓存命中 命中了 L2 缓存中数据的读取或写入请求的百分比。L2 缓存由 GPU 中的许多块共享,包括命令处理器、几何引擎、所有 WGP、所有渲染后端等。每个请求的大小为 128 字节。
通过将鼠标悬停在计数器图例左侧的计数器名称上,可以查看每个计数器的描述。
L0、L1 和 L2 缓存的大小(可能因 GPU 而异)在“概述”选项卡的“系统信息”窗格中报告。
L1 缓存不在 Radeon RX 9000 系列 GPU 上执行任何实际缓存,因此 L1 缓存计数器不会在在此硬件上捕获的配置文件中显示。
用户可以使用左侧的图例选择要包含在图中的计数器。

图例中的每个计数器键都是一个三态按钮。按下按钮会在 3 种状态之间循环:可见、可见且已选择、不可见。
选择一个计数器将填充选定计数器下方的区域。可以同时为一个或多个计数器执行此操作。在此图像中,用户单击了 L1 和 L2 缓存命中计数器的颜色框。

当鼠标悬停在计数器图上时,将显示一个工具提示。此工具提示显示光标最接近点的计数器值,以及与该点相关的“请求”和“命中”和“未命中”的数量。当在 wavefront 占用率视图中选择一个区域时,工具提示将显示代表所选区域的聚合数据。按住 Ctrl 键将暂时隐藏工具提示。
可以在 Radeon Developer Panel 中捕获配置文件时禁用缓存计数器的收集。在这种情况下,缓存计数器图将不可见。
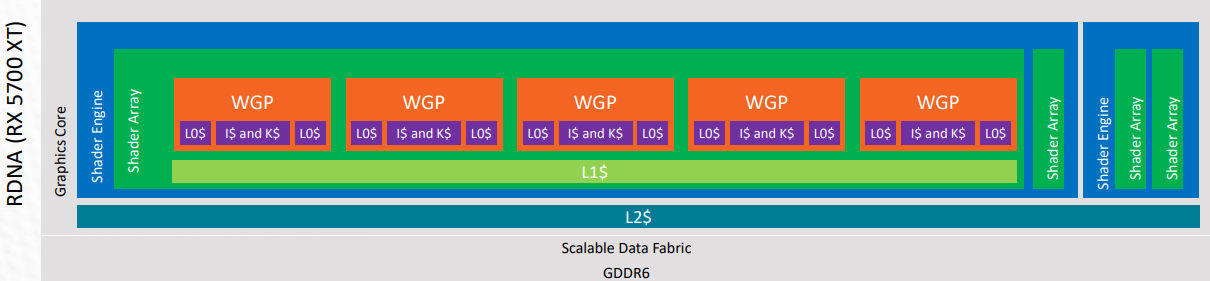
为了更好地理解 RDNA 硬件的缓存内存层次结构,请参阅以下可视化表示。这摘自 gpuopen.com 上的 RDNA 架构演示。
光线追踪计数器
在分析使用光线追踪的游戏时,第二行计数器数据将显示光线追踪计数器值。这些计数器仅在 Radeon RX 6000 系列及更新的 GPU 上可用。

目前在分析过程中收集了两个光线追踪计数器。这些计数器提供了有关帧执行的光线测试数量的信息。
-
光线盒测试 光线盒交叉测试的数量。
-
光线三角形测试 光线三角形交叉测试的数量。
光线追踪计数器的用户交互与缓存计数器的用户交互相同。
事件时间线视图
此部分显示配置文件中的所有事件。这包括应用程序发出的和驱动程序发出的提交。每个事件可能包含一个或多个活动的着色器阶段,这些阶段以矩形块显示。块越长,着色器执行时间越长。如果有一个以上的着色器活动,则每个着色器阶段都通过细线连接,以表示它们属于同一事件。此视图仅显示实际的着色器工作;它不显示事件何时被提交。
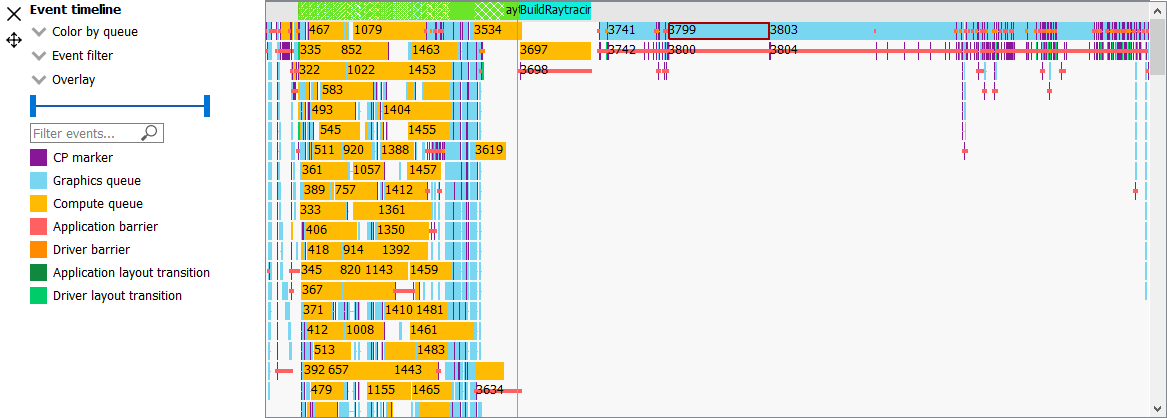
用户可以通过单击单个事件来查看详细信息侧边栏(如下所述)的详细信息。通过选择上方的 Wavefront 图形中的所需区域来缩放此图形。此外,可以通过选择事件并单击“放大到选择”来缩放单个事件。有关更多信息,请参阅“缩放控件”部分。
用户可以使用左侧的“按...着色”组合框以不同的方式可视化事件。
-
按队列着色。 默认。显示哪些事件提交到了图形或异步计算队列。此外,CP 标记以独特颜色显示,以及障碍物和布局转换,以便轻松区分。请注意,来自驱动程序的障碍物和布局转换与来自应用程序的障碍物和布局转换颜色不同,这在时间线视图下方的图例中显示。
-
按硬件上下文着色。 显示事件在哪个上下文上运行。这有助于可视化发生的上下文切换次数。
-
按上下文切换着色。 显示哪些事件自上一个事件以来发生了上下文切换。
-
按限制因素着色。 显示该事件中任何着色器占用率的最大限制因素。
-
按事件着色。 将以独特的颜色显示每个事件。
-
按通道着色。 根据渲染目标或附件类型(颜色、仅深度、计算)将事件分组到不同的通道中。这三种类型被分配了基本颜色,每种类型的每个通道被分配了该基本颜色的不同阴影。这有助于可视化应用程序尝试渲染场景的不同部分的时间。
-
按命令缓冲区着色。 使用与命令缓冲区关联的颜色显示每个事件,从而易于查看事件是否在同一个命令缓冲区中。
-
按用户事件着色。 将根据每个事件周围的用户事件对其进行着色。
-
按 API PSO 着色 将根据其 API PSO 哈希值对事件进行着色。
-
按指令时间着色 将仅对包含详细指令时间信息的事件进行着色。所有其他事件将显示为灰色。
-
按光线追踪着色 将仅对光线追踪事件进行着色。所有其他事件将显示为灰色。
-
按间接命令着色 将根据事件来自哪个间接命令来对每个事件进行着色。来自同一间接命令的事件获得相同的唯一颜色。所有其他事件将显示为灰色。
在“按...着色”组合框下方是“事件过滤器”组合框。这允许用户仅在时间线上可视化某些类型的事件。例如,用户可以选择显示绘制、分派、清除、障碍物、布局转换、复制、解析、包含指令跟踪数据的事件以及光线追踪事件。还有一个选项可以打开或关闭 CP 标记。关闭 CP 标记将仅显示活动的着色器块。
在“事件过滤器”组合框下方是“覆盖图”组合框。这允许用户选择要在时间线上显示的固定“覆盖图”。覆盖图显示在时间线顶部的一个或多个行中。它们有助于可视化每个事件的各种状态。可以启用多个覆盖图。支持以下覆盖图:
-
全部。 将显示所有可用的覆盖图。
-
用户事件。 默认。显示所有用户事件,如果捕获的帧包含任何此类事件。用户事件根据嵌套级别堆叠,交叉图案表示多个重叠的用户事件区域。将鼠标光标移到一个用户事件上会显示一个工具提示,其中列出了光标下的所有用户事件,包括每个用户事件间隔的计时信息。
-
硬件上下文。 显示所有硬件上下文。每个硬件上下文都有自己的行。这允许用户可视化每个上下文的生命周期。
-
命令缓冲区。 显示所有命令缓冲区。命令缓冲区根据提交时间堆叠,因此如果一个命令缓冲区在先前的命令缓冲区完成之前提交,则新命令缓冲区将堆叠在先前的命令缓冲区下方。
-
渲染目标。 显示所有渲染目标。如果在给定时间段内有一个以上的渲染目标处于活动状态,则活动渲染目标将被堆叠。这允许用户可视化帧持续时间内渲染目标的使用情况。
事件持续时间百分比过滤器允许用户仅查看持续时间在特定百分比内的事件。例如,选择滑块的最右侧区域将突出显示成本最高的事件。使用持续时间百分比过滤器上的滑块按钮时,工具提示将显示与选定百分比相对应的时间持续时间范围。您还可以找到一个文本框,用于按事件名称过滤时间线。

Wavefront 时间线视图中提供的缩放和拖动功能在这里也可用。
最后,底部有颜色图例,用作颜色提醒。请注意,这些颜色可以在设置中自定义。
详细信息侧边栏
按右上角的“隐藏详细信息”将隐藏带有更深入信息的侧边栏。此面板的内容将根据用户最后选择的内容而变化。如果事件时间线中选择了一个事件,详细信息侧边栏将如下所示:

单个事件的详细信息侧边栏包含以下数据:
-
事件的 API 调用名称
-
它启动的队列
-
用户事件层次结构(如果存在)
-
开始、结束和持续时间
-
硬件上下文及其是否已回滚
-
事件使用的所有着色器的 API 着色器哈希
-
事件的 API PSO 哈希
-
事件的驱动程序内部管道哈希
-
显示每个 RDNA 或 GCN 硬件阶段 Wavefront 分布的彩色条
-
RDNA 或 GCN 硬件阶段和 Wavefront 计数的列表
-
总 Wavefront 计数
-
总线程数
-
显示活动阶段和持续时间的 RDNA 或 GCN 着色器时间线图形
-
显示每个 API 着色器阶段资源使用情况的表
-
VGPR 和 SGPR 列指的是使用的向量和标量通用寄存器,括号中显示分配的寄存器数量。
-
LDS 列指的是每个着色器阶段使用的本地数据存储量,以字节为单位报告。
-
占用率列指的是着色器的理论 Wavefront 占用率。报告为“A / B”,其中 A 是可以运行的 Wavefront 数量,“B”是硬件支持的最大 Wavefront 数量。
-
通过将鼠标悬停在表头上来查看数据的工具提示。
-
-
“API 着色器阶段控件”指示所选事件的活动着色器阶段。
-
图元、顶点、控制点和像素计数
“持续时间”显示从第一个着色器开始到最后一个着色器结束的时间,包括着色器之间没有实际工作(由连接着色器“块”的线条表示)的任何空间。“工作持续时间”仅显示着色器实际工作的实际时间。这是所有着色器块的总和,忽略了没有工作的连接线。如果着色器之间有重叠,重叠时间仅计算一次。如果所有着色器都重叠,则持续时间将与工作持续时间相同。
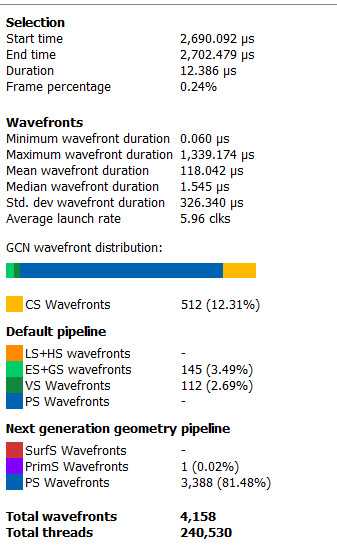
如果用户通过单击和拖动鼠标选择一个范围,详细信息侧边栏将显示所选区域中包含的所有 wavefront 数据的摘要(如下所示)。
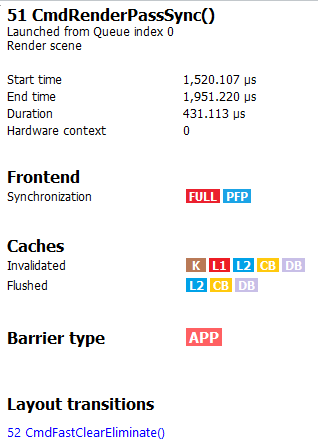
如果用户选择了一个障碍物,详细信息侧边栏将显示与该障碍物相关的信息,例如障碍物标志和与该障碍物关联的任何布局转换。它还将显示障碍物类型(是来自应用程序还是驱动程序)。请注意,障碍物类型取决于视频驱动程序是否支持此功能。如果不支持,则会显示为“N/A”。下面显示了一个用户插入的障碍物示例。
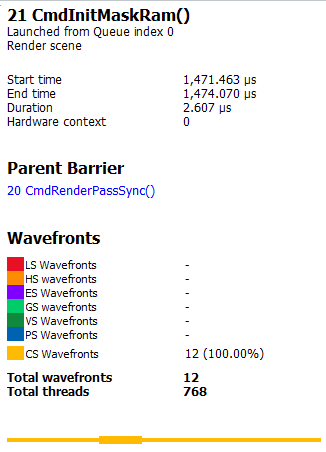
如果驱动程序需要插入障碍物,还将显示插入该障碍物的详细原因(如下所示)。

如果用户选择了一个布局转换,详细信息侧边栏将显示与布局转换相关的信息(如下所示)。
用户还可以右键单击“事件时间线”视图中的任何事件或覆盖图,然后导航到“事件时间”、“管道状态”或“指令时间”窗格,或者导航到“概述”选项卡中的一个窗格。选定的事件或覆盖图将在所选视图中显示。
此外,用户可以使用此上下文菜单中的“放大到选择”选项来放大事件。
下面是右键上下文菜单外观的屏幕截图。
Wavefront 占用率自定义 RGP 的 Wavefront 占用率部分是可自定义的。用户可以隐藏视图并重新排序视图的垂直位置。用户还可以调整视图的高度。
要隐藏视图,只需按视图旁边的 X 按钮即可。

要显示隐藏的视图,请使用选项卡左上角的“视图”组合框。
“视图”组合框也可用于隐藏视图。
要重新排序视图在选项卡中的垂直位置,您可以拖动要重新排序的视图并将其放入新位置。
要执行此操作,请将鼠标移到要移动的视图旁边的拖动按钮上方。视图周围会出现一个虚线蓝色矩形,表示在释放鼠标后将拖动的视图。
按住拖动按钮。将出现一条实线蓝色线条,表示释放鼠标后的新视图位置。
视图将被放置到其新位置,直到您再次移动它。视图组合框将更新以反映其新位置。
通过单击并拖动视图的底部,可以调整视图的大小。
Wavefront 占用率部分的自定义被视为正常 RGP 设置,并在关闭和重新打开 RGP 时保留。
要将 Wavefront 占用率自定义恢复到原始状态,请按选项卡左上角的“恢复到默认值”按钮。
请注意,图例侧边栏的可见状态也会被保存。
事件时间
事件时间窗显示事件列表及其相应的计时。左侧列的树视图显示每个事件名称及其唯一的索引(从 0 开始),并按顺序排列。事件可以按组排序,组类别以粗体显示。
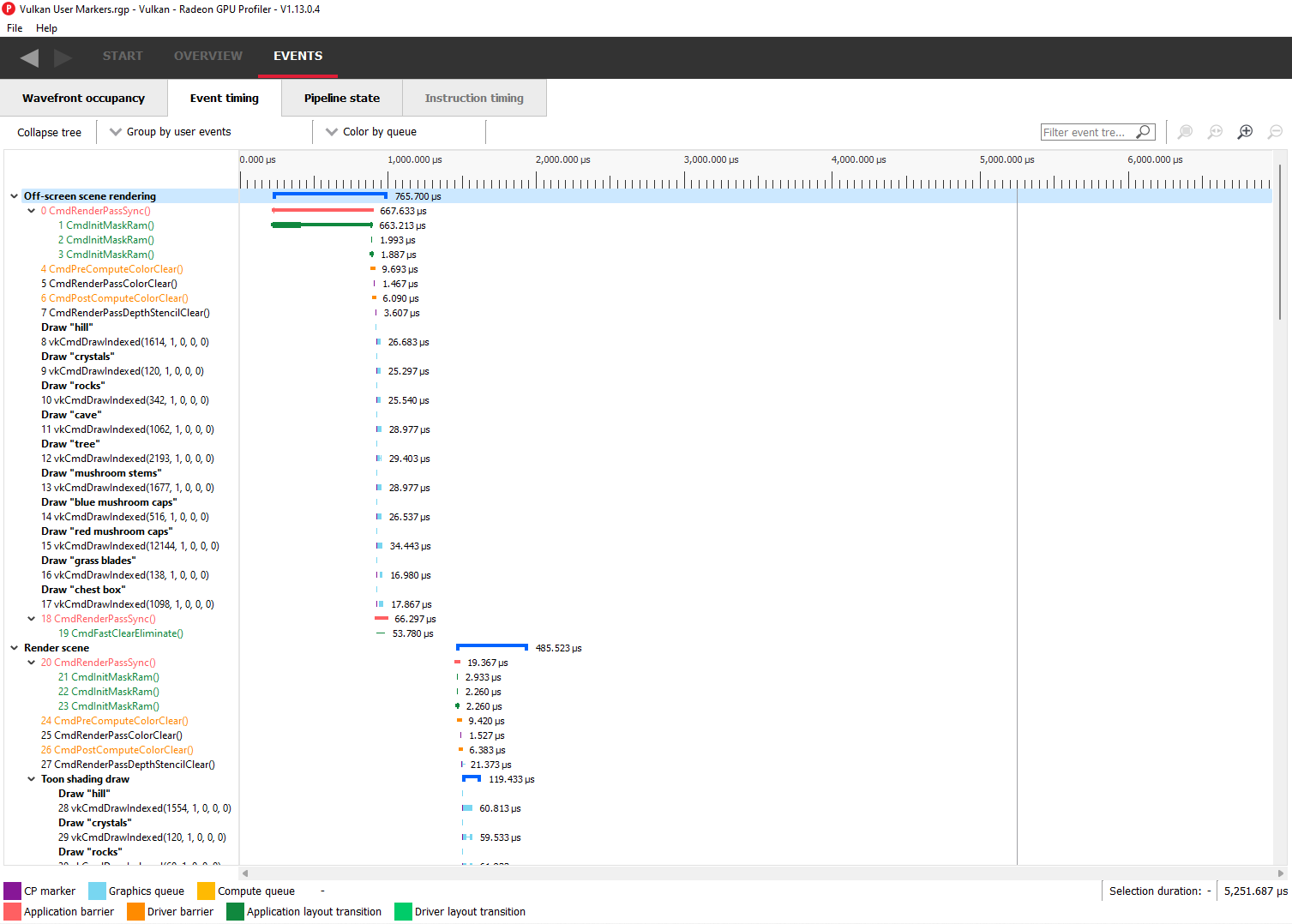
树状视图右侧的窗格显示了每个事件持续时间的图形表示。树节点右侧的深蓝色条显示了该节点中所有事件的持续时间。
在每个事件(上图中以浅蓝色显示)的图形中,左侧的第一个小块是 CP 标记,指示事件的发出时间。此后,过一段时间,着色器会执行实际工作。CP 标记与实际工作开始之间的时间延迟可能表明应用程序存在瓶颈。着色器之一可能正在等待一个资源,该资源当前正被另一个正在进行的波形占用,并且在获得该资源之前无法开始。第一个着色器开始工作和最后一个着色器完成工作的时间是此列中显示的数字。每个着色器阶段都由一个矩形块表示。块越长,着色器执行所需的时间越长。着色器通过实线连接,以显示它们在管道中是连接的。对于组,深色线跨越组内的所有事件,显示该组完成工作所需的时间。
此窗格的缩放设置与波形图占用率窗格类似。有关更多信息,请参阅缩放控件部分。
分组模式
事件可以组合在一起。通常,这些组不会影响事件顺序,但有时会影响(按状态桶排序)。
-
按通道分组将根据渲染目标或附件类型(颜色、仅深度、计算、光线追踪)显示事件。
-
按硬件上下文分组将按硬件上下文对事件进行分组,从而可以轻松查看哪些事件导致了上下文的更改。
-
按状态桶分组(未排序)将按状态桶对事件进行排序,但不会按持续时间对状态桶进行排序。理论上,状态桶中的所有事件都使用相同的着色器。状态桶的持续时间由与状态桶组文本对应的深蓝色线表示。
-
按状态桶分组(串行化)将采用组内的所有事件计时,并汇总着色器忙碌的总时间,忽略事件之间的所有空隙。这会将着色器工作串行化,并且不考虑某些着色器会并行执行。这用于突出显示您有很多小型着色器,它们的累积工作量可能很大。例如,如果您有两个同时开始的着色器,一个需要 2000 个时钟周期,另一个需要 10000 个时钟周期,则总持续时间将是 12000 个时钟周期。
-
按状态桶分组(重叠)会考虑着色器执行的并行性,因此会突出显示执行时间长的着色器。使用相同的上述示例,由于两个着色器同时开始,因此在这种情况下总持续时间将是 10000 个时钟周期。
-
按命令缓冲区分组将根据事件所在的命令缓冲区对其进行分组。
-
按用户事件分组将根据事件被哪些用户事件包围来对其进行分组。
-
按 PSO 分组将按其 API PSO 哈希值对事件进行分组。
默认分组模式是按用户事件分组(如果配置文件中存在用户事件)。否则,默认将按通道分组。
请注意,按硬件上下文或命令缓冲区分组将首先按队列对事件进行分组。按通道或用户事件分组将按时间顺序对事件进行分组,而不管它们源自哪个队列。按状态桶分组仅显示图形队列中的事件。按硬件上下文分组如下所示
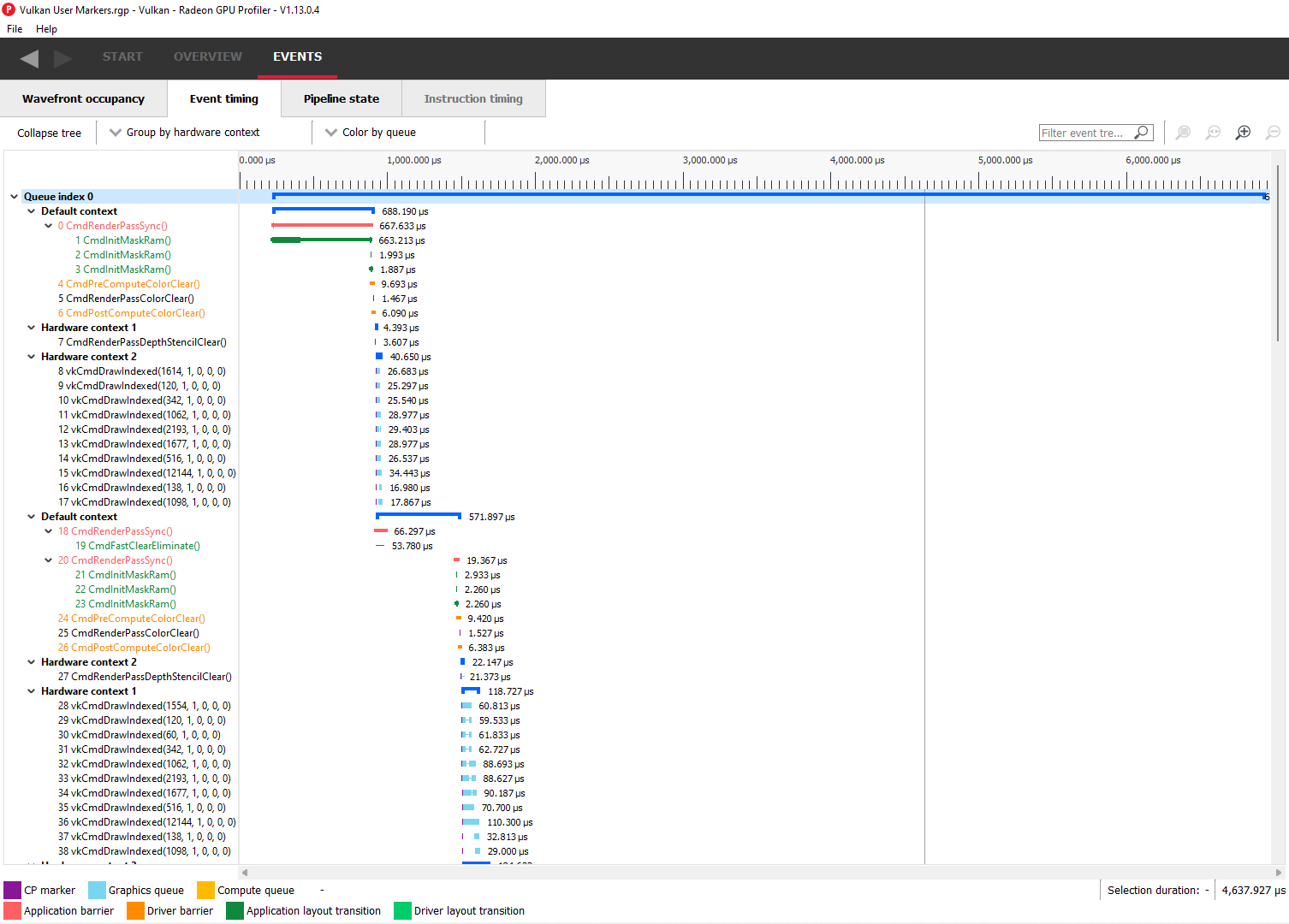
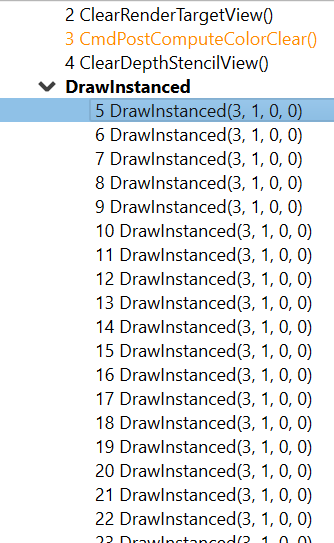
请注意,当分析使用间接绘制D3D12 调用的应用程序时,事件树视图将在逻辑上将单个绘制调用分组到同一父节点下。这可以在下面看到,其中单独的DrawInstanced事件被分组到具有相同名称的父节点下
颜色模式
事件可以使用与波形图占用率视图相同的方式使用不同的配色方案进行渲染。
用户还可以右键单击任何事件,然后导航到波形图占用率或管道状态窗格,以及“概述”选项卡中的“障碍”、“最昂贵的事件”和“上下文滚动”窗格,并在这些窗格以及侧面板中查看选定的事件。
波形图占用率和事件计时窗口同步
波形图占用率视图和事件计时视图的时间比例缩放和水平平移可以同步或独立调整。有关同步的更多信息,请参阅缩放同步标题
事件的构成
下面显示了两个典型的绘制调用事件的示例

![]()
A 显示 CP 标记。这是 GPU 中的命令处理器发出要执行的工作的点。然后将其排队,直到 GPU 可以处理工作负载。
B 显示各种着色器阶段正在执行的工作。CP 标记和B开始之间的时间间隔表明 GPU 没有立即开始工作负载,而是忙于执行其他事情,例如之前的绘制调用。
C 显示着色器执行完成后需要进行的任何固定功能工作。当绘制调用仅进行深度渲染时,会出现这种情况。显示的固定功能工作是顶点着色器对顶点进行的图元装配和扫描转换。
用户还可以通过右键单击事件来获取有关事件的父命令缓冲区的信息。这将弹出一个上下文菜单,其中包含一个用于查找事件父命令缓冲区的菜单项。选择此菜单项将导航到“帧摘要”窗格,并将焦点设置在选定事件的父命令缓冲区上。在此之后,用户可以获得有关所讨论事件周围上下文的宝贵的系统级见解。
计算分派具有更简单的结构。下面显示了一个计算事件的示例。
![]()
在计算事件中,只启动计算着色器波形。此外,计算分派在着色器工作完成后没有固定功能工作。
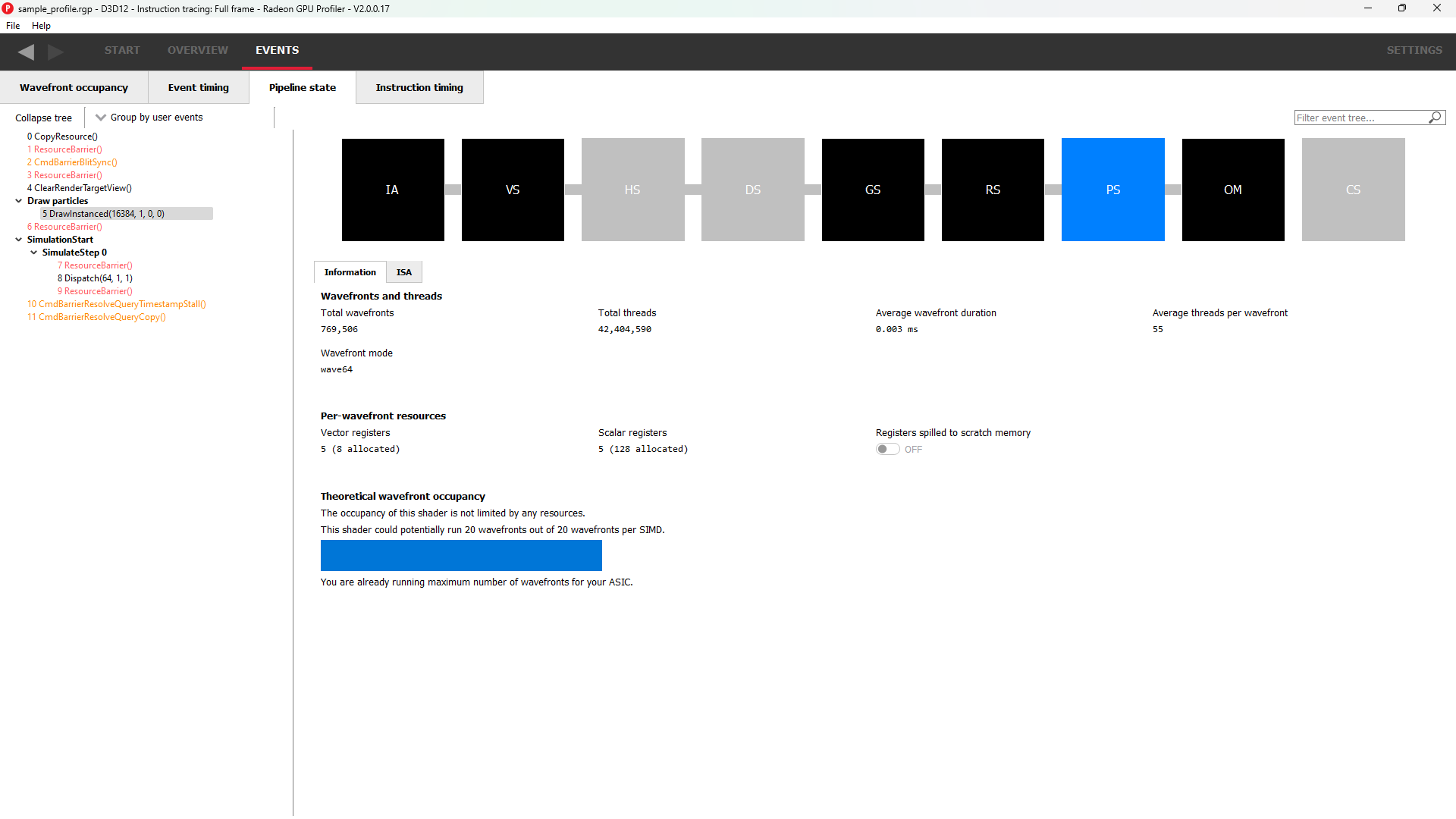
管道状态
管道状态窗口按阶段显示单个事件的渲染状态信息。在下面的示例中,该事件是使用 VS、GS 和 PS 的 DirectX12 DrawInstanced 调用。活动的阶段以黑色渲染,可以选择;灰色的阶段在此绘制中不活跃,无法选择。
用户已选择 PS 阶段进行查看,并以蓝色渲染以表示此。下面是用于在本次绘制的波形图活动摘要、每波形图寄存器资源使用情况以及着色器 ISA 反汇编之间切换的选项卡式显示。
寄存器值指示着色器使用的寄存器数量。括号中的值是为着色器分配的寄存器数量。
从这些信息以及对 RDNA 或 GCN 架构的了解,我们可以计算出像素着色器的理论最大波形图占用率。在这种情况下,理论上每 SIMD 可能有 8 个波形图,但可能会受到其他因素的限制。
切换到 ISA 选项卡将以 ISA 级别显示着色器代码。顶部将提供一些常规信息,例如使用的寄存器数量以及各种哈希值。该事件的。
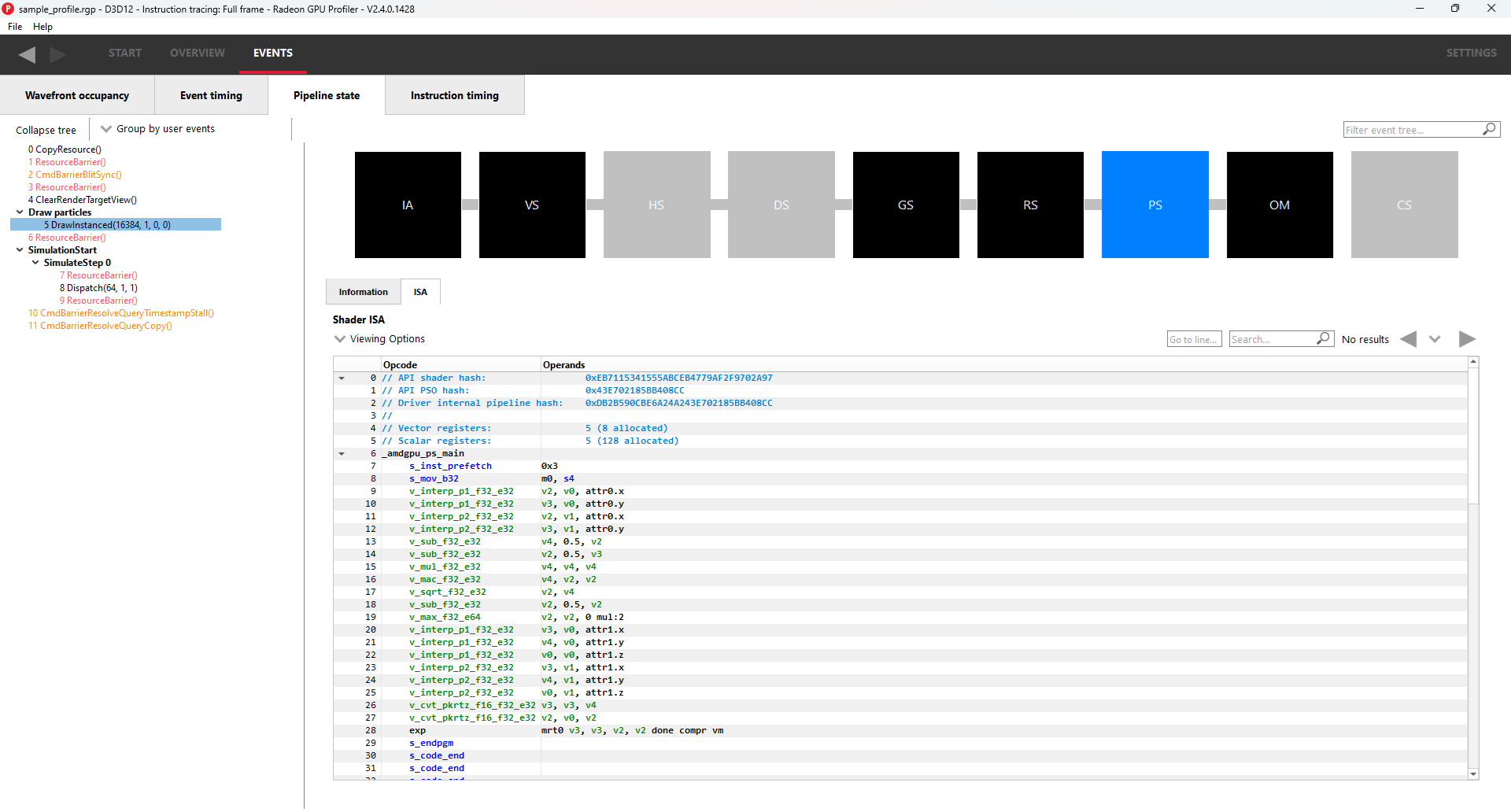
有关 ISA 选项卡的更多信息,请参阅ISA 视图部分。
分组模式
分组模式与事件计时窗格相同。
用户还可以右键单击任何事件,然后导航到波形图占用率或事件计时窗格,以及“概述”选项卡中的“障碍”、“最昂贵的事件”、“上下文滚动”、“渲染/深度目标”和“管道”窗格。用户可以在这些窗格以及侧面板中查看选定的事件。下面是右键单击上下文菜单的外观截图。
注意:DirectX 12 应用程序的输出合并器阶段可能会将 LogicOp 报告为 D3D12_LOGIC_OP_COPY,尽管它在应用程序中设置为 D3D12_LOGIC_OP_NOOP。如果启用了混合,这两种操作在语义上是相同的。noop 表示不对数据执行任何转换,因此输出与源相同。
注意:对于 OpenCL 或 HIP 应用程序,管道状态不显示图形特定阶段,因为它们在计算分派期间不活跃。
光线追踪事件
对于光线追踪事件,有两种可能的编译模式:统一和间接。AMD 驱动程序和编译器将为每个光线追踪事件选择模式。所选事件的编译模式将体现在事件名称中:使用统一模式的事件将带有<Unified>后缀,而使用间接模式的事件将带有<Indirect>后缀。对于 DirectX 光线追踪,完整事件名称是DispatchRays<Unified>或ExecuteIndirect<Rays><Unified>以及DispatchRays<Indirect>或ExecuteIndirect<Rays><Indirect>。对于 Vulkan,完整事件名称是vkCmdTraceRaysKHR<Unified>或vkCmdTraceRaysIndirectKHR<Unified>以及vkCmdTraceRaysKHR<Indirect>或vkCmdTraceRaysIndirectKHR<Indirect>。这两种编译模式之间的主要区别在于如何编译光线追踪管道中的各个着色器。在统一模式下,各个着色器将被内联到一个着色器中,从而产生一组单一的 ISA。在间接模式下,各个着色器将单独编译,并且每个着色器中的函数将成为其自己的 ISA 指令集。会在 ISA 中生成函数调用指令,以允许一个函数调用另一个函数。对于间接模式,事件的整体占用率受所有着色器资源使用情况的影响,即使是那些调用次数为零的着色器。即使使用最多矢量寄存器的着色器函数实际上没有被执行,但它使用了最多的寄存器这一事实意味着它可能是导致事件整体占用率降低的原因。
选择使用间接编译模式的光线追踪事件时,管道状态窗格的外观会略有不同。
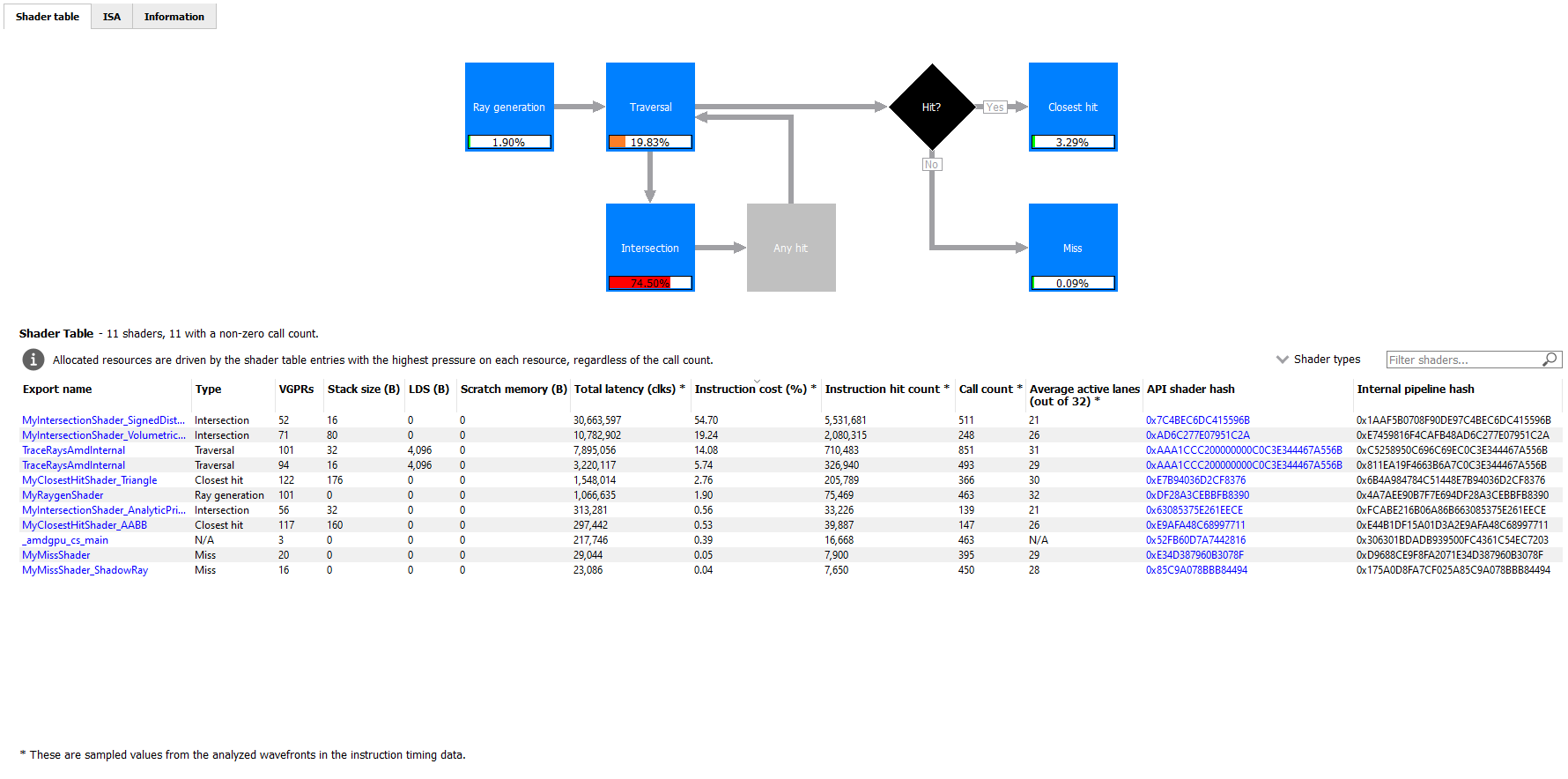
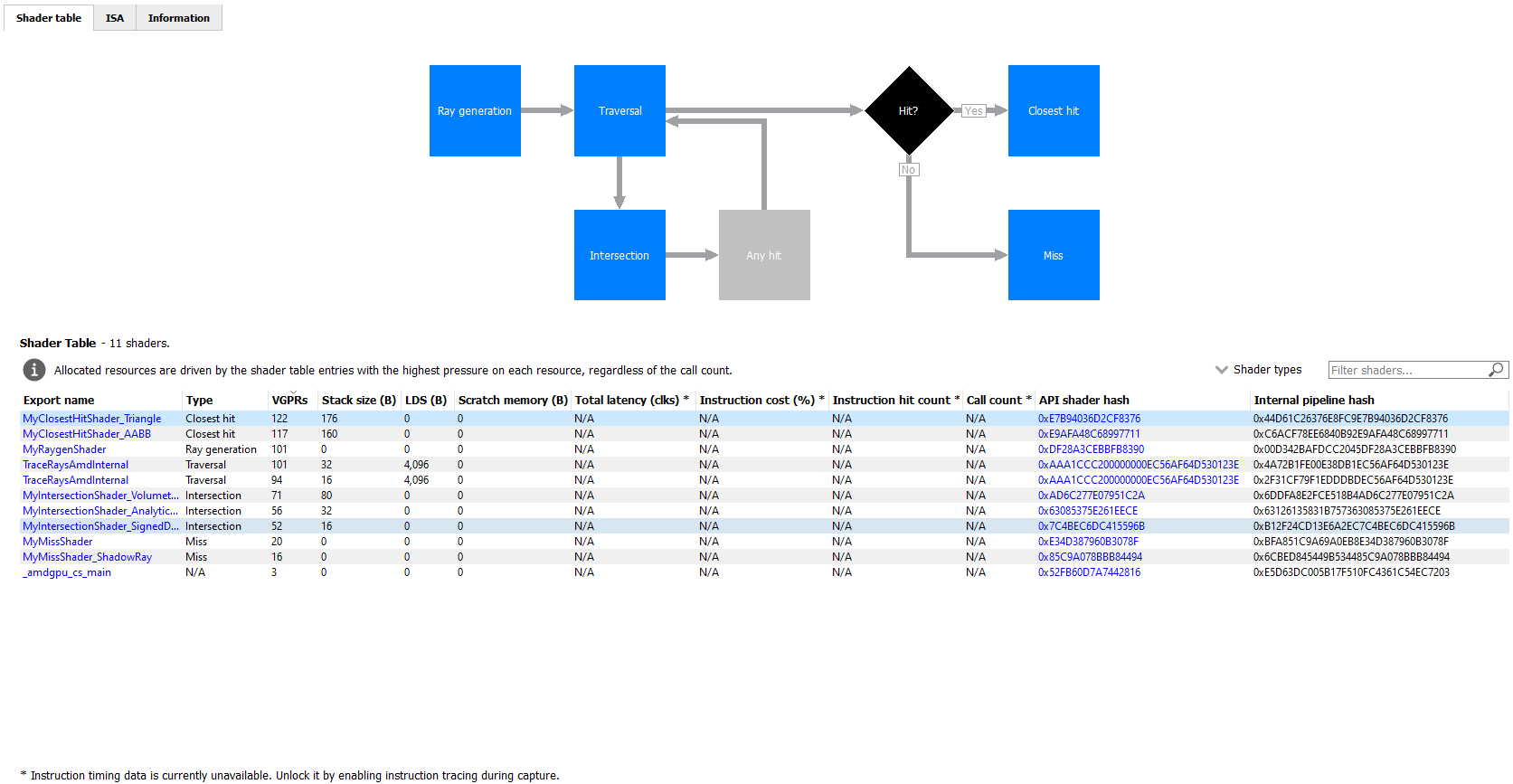
有三个选项卡可用:着色器表、ISA 和信息。
“着色器表”选项卡包含两个主要部分:一个表示光线追踪管道的交互式流程图和一个包含着色器函数列表的表。每个着色器函数都有一个关联的类型。此类型可以是光线生成、遍历、相交、任何命中、最近命中、丢失或可调用。着色器表列出了每个着色器函数、其类型、资源使用情况统计信息、指令计时统计信息以及 API 着色器哈希和内部管道哈希。您可以使用着色器类型组合框按着色器类型过滤表。您还可以使用筛选着色器…字段按导出名称过滤表。如果您单击着色器表中的任何超链接文本,它将导航到 ISA 选项卡并显示所选着色器函数的 ISA。您还可以使用右键单击上下文菜单导航到 ISA 选项卡或指令计时视图。上下文菜单还允许您在 Radeon GPU 分析器中分析该着色器函数的管道二进制文件。
如果在捕获配置文件时在 Radeon Developer Panel 中选中了“启用着色器插装”复选框,则该表还将包含一列,显示每个着色器函数在调用该函数的所有调用中的平均活动通道数。活动通道数在每个着色器执行开始时附近进行采样,从而指示整个光线追踪管道中的线程发散量。将鼠标悬停在此列的单元格上时,会显示一个工具提示,显示单个调用活动通道数的分布。这可以表明运行时通过管道的不同执行路径的数量。请注意,在 Radeon Developer Panel 中启用此设置可能会增加正在分析的应用程序的运行时开销。
流程图提供了光线追踪管道的视觉表示,并显示了每个阶段着色器的相对成本百分比。百分比条的颜色编码如下:红色表示阶段包含占事件总成本 50% 以上的着色器。橙色表示阶段包含总成本在 10% 到 50% 之间的着色器,绿色表示阶段的总成本小于 10%。
流程图还提供了一种快速筛选着色器表的方法。单击某个阶段时,表将仅显示该阶段的着色器函数。您可以通过按住 CTRL 键并单击其他阶段来筛选多个阶段。选定的阶段显示为蓝色,未选定的阶段显示为黑色,禁用的阶段(没有相应着色器函数的阶段)显示为灰色。您可以通过单击流程图中任何空白区域来删除所有过滤器。
对于使用指令跟踪捕获的配置文件,表和流程图都将包含完整的数据集。对于未启用指令跟踪捕获的配置文件,表中的几列将显示N/A而不是实际数据。同样,对于未启用指令跟踪捕获的配置文件,流程图将不显示百分比条。
下图显示了在没有指令计时数据的情况下此视图的外观。
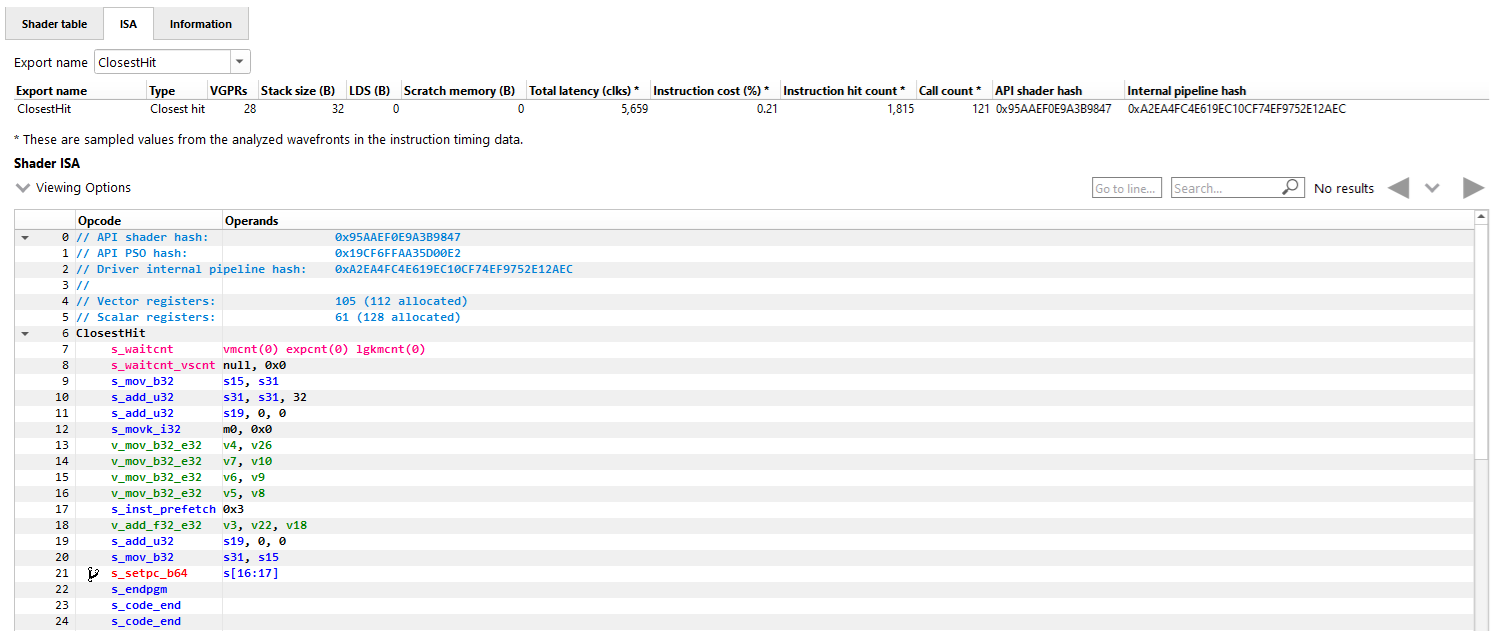
对于使用间接编译模式的光线追踪事件,ISA 选项卡的外观也会有所不同。除了正常的 ISA 列表外,还有一个下拉组合框,允许查看来自不同着色器函数的 ISA。对于选定的着色器函数,还会显示来自着色器表的相应行作为参考。
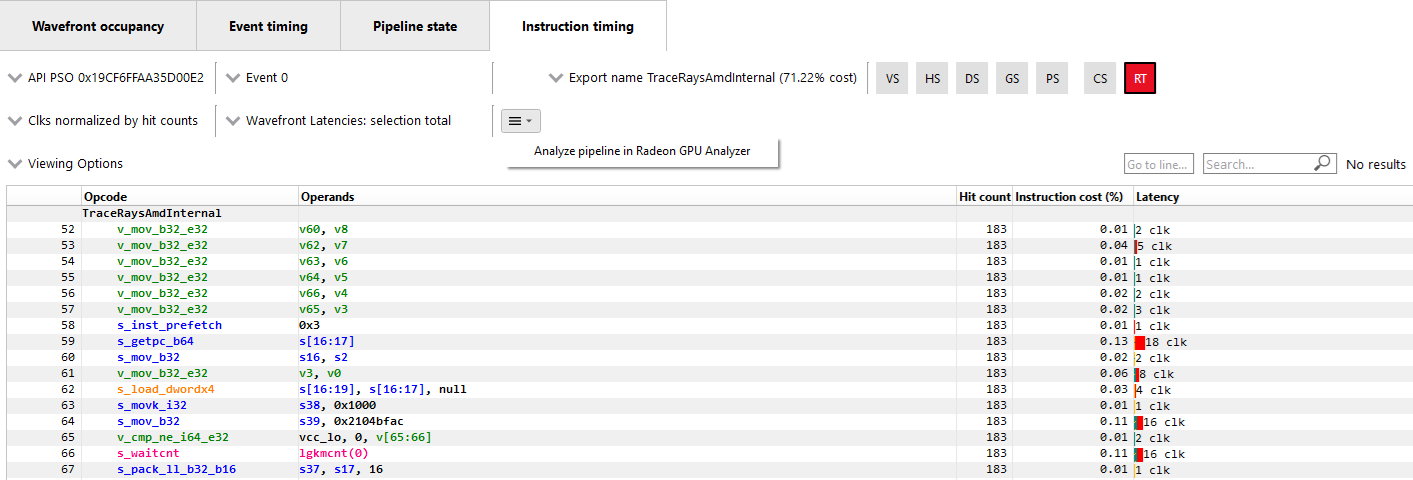
指令时间
指令计时窗格显示单个着色器的每条指令的平均发布延迟。指令计时信息是使用 AMD RDNA 和 GCN GPU 上的硬件支持生成的。生成指令计时不需要重新编译着色器或在着色器中插入任何插装。
指令计时窗格显示 RDNA 或 GCN ISA。有关 ISA 的更多详细信息,请参阅以下资源
下面显示了着色器的指令计时窗格。
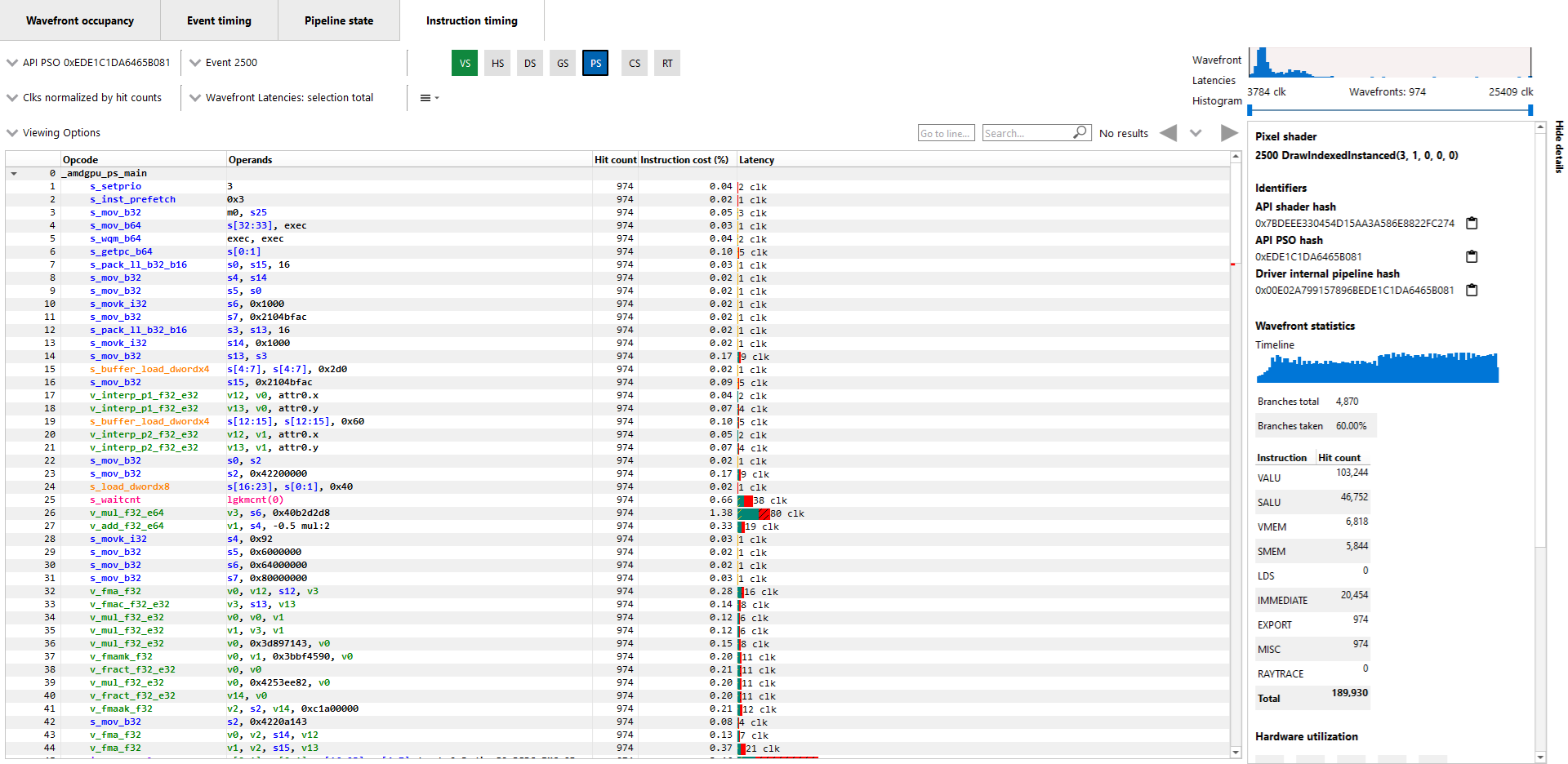
延迟:指令计时视图中的每条着色器行显示了从一条指令发布到下一条指令发布之间的时间。为了提供有关延迟含义的信息,下面显示了一些示例 ISA 语句。
最佳指令发布:在下面的图像中,我们看到五条指令。1 clk表示每条指令的发布与下一条指令的发布之间的延迟。此示例显示了一个理想的性能案例,其中每条指令以 1 个时钟间隔发布。

指令发布延迟:在下面的图像中,我们看到四条导出指令。第一条exp指令的间隔相当长,为 4,173 个时钟周期。这可以预期,因为导出指令的发布可能会延迟,原因包括内存资源不可用,这些资源可能被其他波形占用。因此,指令中存在长时间的延迟。由于看到了第一条导出指令的内存资源等待延迟,因此后续导出指令的持续时间要短得多。

等待计数和指令发布:在下面的图像中,我们看到八条指令。有一个向量缓冲区加载,后面跟着五条向量 ALU 指令,所有这些指令都以很小的延迟发布。然后我们看到一条s_waitcnt指令。s_waitcnt的发布间隔较长,为 885 个时钟周期。之前的tbuffer_load_format_x指令的短延迟可能看起来是反直觉的,因为它是一条内存加载指令。然而,这是预期的,因为s_waitcnt是一条用于同步的着色器指令,用于等待之前的指令(如之前的缓冲区加载)完成。s_waitcnt指令会发布,然后等待(在这种情况下是 885 个时钟周期),直到下一条指令(v_and_b32_e32)可以发布。

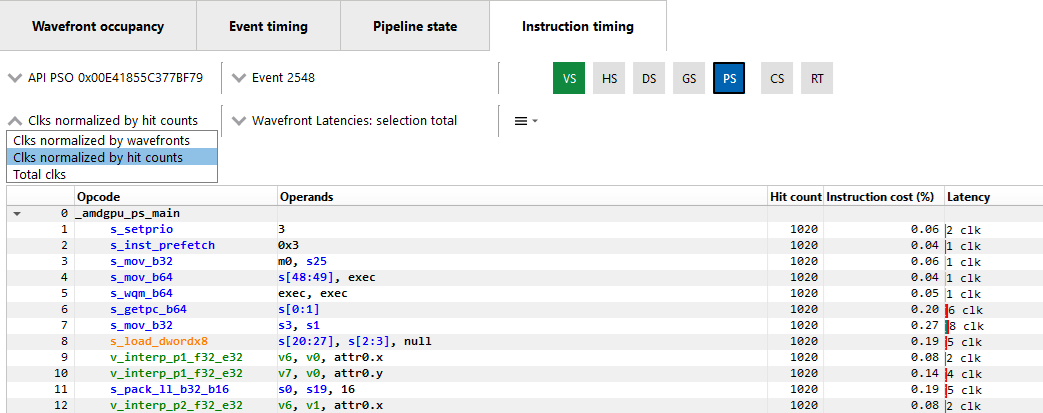
默认情况下,任何两条指令之间的延迟是该指令每命中一次的平均延迟。延迟也可以显示为每波形图的平均值或所有波形图的总和。这可以使用下面显示的归一化模式下拉菜单进行切换。
给定指令的时钟周期数也由条形表示。条形的长度对应于指令延迟的时钟周期数。条形中使用不同的颜色来指示指令延迟的哪些部分被其他波形槽上的工作隐藏,而后续指令正在等待在其槽上发布。这可以在下面的图像中看到。

实绿色表示给定指令的延迟有多少被 VALU 工作隐藏。实黄色表示有多少延迟被 SALU 或 SMEM 工作隐藏。由绿色和黄色组成的对角线阴影图案表示有多少延迟被 VALU 和 SALU 工作隐藏。带有黑色对角线阴影图案的区域是预发布停顿的部分。最后,实红色表示有多少延迟未被其他 GPU 工作隐藏。具有大红色段的条形很可能表示着色器执行期间发生的停顿。当鼠标悬停在延迟列的某一行上时,会显示一个工具提示,其中详细说明了该指令的延迟。
在上图中,指令的总延迟为 845 个时钟周期。在这 845 个时钟周期中,有 197 个时钟周期的延迟被其他槽上的 SALU 工作隐藏,有 453 个时钟周期的延迟被 VALU 工作隐藏。同时进行 SALU 和 VALU 工作的那 197 个时钟周期用阴影图案表示。197 到 453 个时钟周期之间的部分显示为绿色,因为只进行了 VALU 工作。453 到 845 个时钟周期之间的部分显示为红色,因为没有进行其他工作。由于同时进行的 VALU 工作较多,因此此条形中的绿色比黄色更普遍。
与下图形成对比,其中一条指令显示了更多延迟被 SALU 工作隐藏。在这种情况下,黄色比绿色更普遍。

当 SALU 和 VALU 工作隐藏的延迟量大于预发布停顿量时,将不显示黑色对角线阴影图案,并且工具提示将显示预发布停顿完全隐藏。如果 SALU 和 VALU 工作隐藏的延迟量小于预发布停顿量,则 VALU 和 SALU 工作之后的时间将具有黑色对角线阴影图案,如下图所示。

垂直滚动条中会显示一个红色指示器,对应于延迟最高的指令的位置。这使您可以快速找到着色器中的热点。
命中次数:每条指令的命中次数显示了为选定事件执行该指令的次数。当首次查看事件时,零命中次数的所有基本块(跨越着色器中的所有波形图)将自动折叠,如下所示。

基于当前延迟范围和延迟选择模式,命中次数为零的基本块也将被灰色显示,如下所示。

指令成本百分比:每个 ISA 指令的指令成本显示了整个着色器总发布延迟的百分比。对于具有分支的着色器,其中连续指令的命中次数可能不同,指令成本会包含该指令的额外命中次数。这使我们能够找到着色器中的热点。
ISA 指令的指令成本计算如下
指令成本 = 100 * (ISA 指令的所有延迟之和) / (着色器所有延迟之和)
筛选波形图:默认情况下,延迟、命中次数和指令成本值是使用为给定着色器分析的所有波形图计算的。还可以显示最快波形图和最慢波形图的信息,从而深入了解性能方面的任何异常值。可以使用波形图延迟下拉菜单(如下所示)在显示所有波形图、最快波形图和最慢波形图之间进行切换。
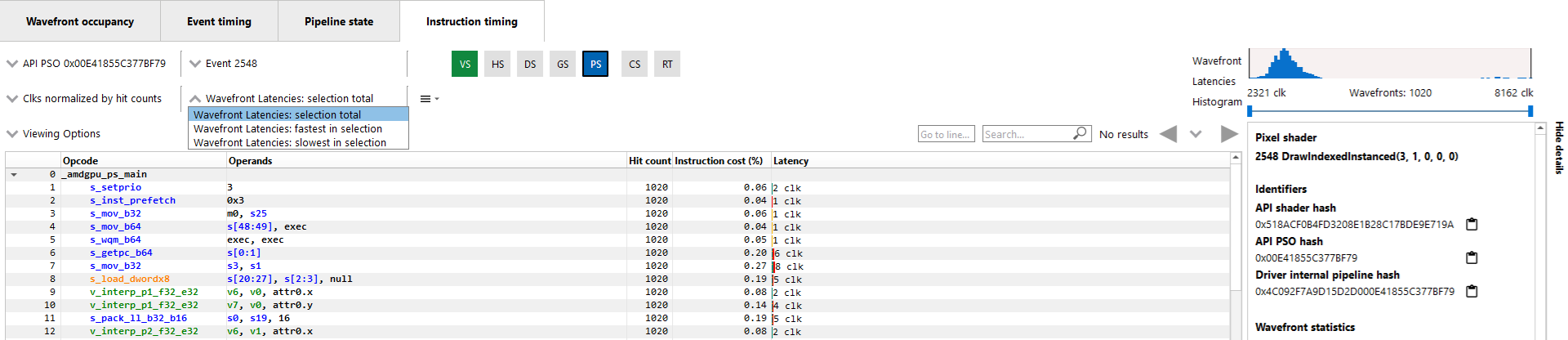
还可以使用波形图延迟直方图(如下所示)筛选要分析的波形图。

此直方图提供了当前着色器完整波形图集的视觉表示。最快的波形图位于直方图的左侧,最慢的波形图位于右侧。延迟值从左到右增加。直方图中每个条的高度给出了对应于条所表示的延迟值集合的波形图数量的相对指示。
直方图下方有一个滑块控件,可用于筛选波形图。两个滑块允许您指定要分析的波形图的时钟范围。只有落在指定范围内的波形图才会计入显示的延迟、命中次数和指令成本百分比值。如果设置了范围,则选择中的最快和选择中的最慢过滤器将显示该范围内的最快和最慢波形的信息。
如果所有分析的波形图的总延迟相同,则直方图将被隐藏,因为所有波形图最终都会落入单个桶中。因此,当仅为一个选定的着色器分析一个波形图时,直方图将被隐藏。任何时候隐藏直方图时,波形图延迟下拉菜单和侧面板“波形图统计信息”部分中的时间线也将被隐藏。
指令计时捕获粒度:指令计时信息是为整个 RGP 配置文件生成的,但数据仅限于单个着色器引擎。只有由单个着色器引擎执行的波形图才会计入指令计时窗格中显示的命中次数和计时信息。有关如何捕获指令计时信息的更多信息,请参阅 Radeon Developer Panel 文档。
要查看所有具有指令计时信息的事件,开发人员可以选择波形图占用率或事件计时视图中的“按指令计时着色”选项。
指令计时可用性:在某些情况下,某些事件可能没有指令计时信息。指令计时信息未出现在事件中的主要原因如下。
硬件架构和绘制调度:指令计时信息仅从 GPU 单个着色器引擎的某些计算单元进行采样。因此,波形图数量很少的事件可能没有指令数据。如果 GPU 将波形图调度到未启用指令跟踪的着色器引擎或计算单元,则可能发生这种情况。
内部事件:应注意,无法查看内部事件(如 Clear())的指令计时信息。
导航:可以通过右键单击事件并选择“在指令计时中查看”选项来访问事件的指令计时。由于通常在多个事件中使用相同的着色器,RGP 提供了一种简单的方法来在使用相同着色器的多个事件之间切换,使用下面显示的事件下拉菜单。
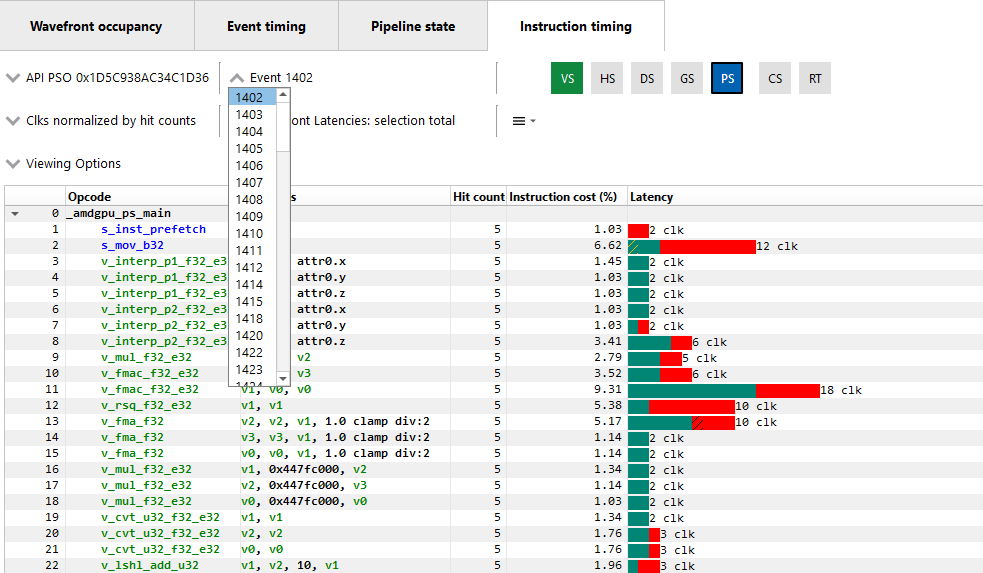
这允许开发人员研究着色器在不同事件中的行为。建议使用键盘快捷键(Shift + 向上和 Shift + 向下)更改 API PSO 选择,(Shift + 向左和 Shift + 向右)使用相同的着色器在不同事件之间移动。API 着色器阶段控件指示为选定事件激活的着色器阶段。单击活动阶段后,指令计时窗格将更新以显示所选着色器阶段的计时数据。
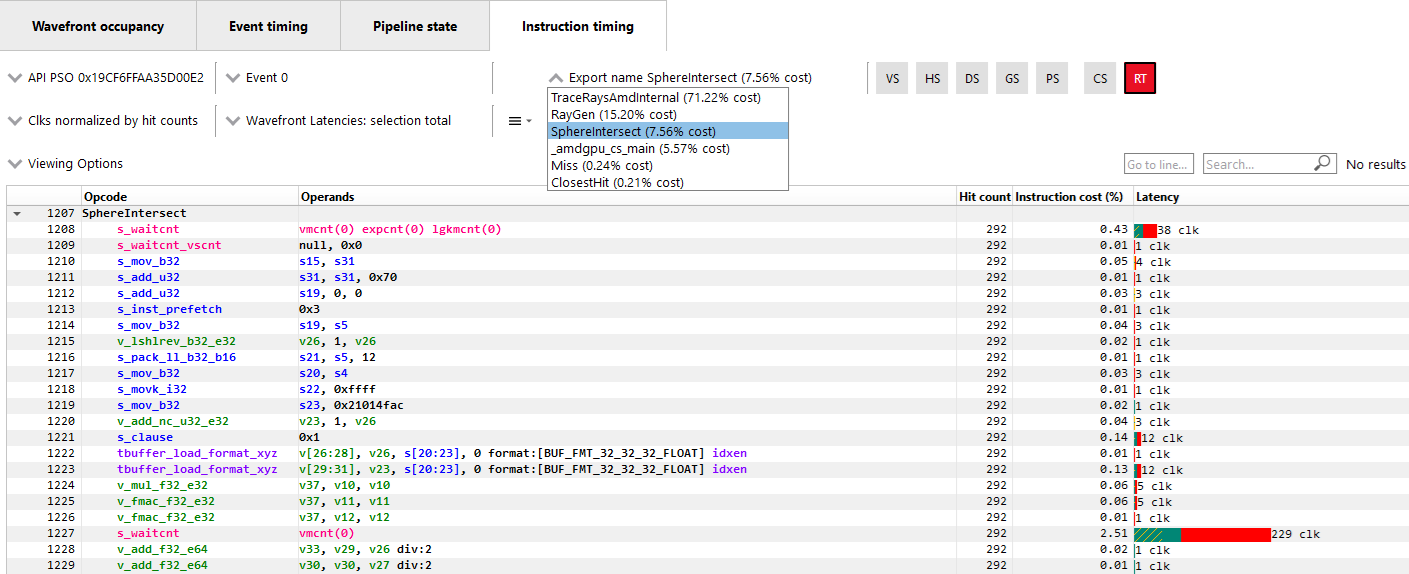
光线追踪事件导航:对于某些光线追踪事件,将提供一个额外的导出名称下拉菜单。是否显示此下拉菜单取决于 AMD 驱动程序和编译器为选定事件选择的编译模式。有两种可能的编译模式:统一和间接。所选事件的编译模式将体现在事件名称中:使用统一模式的事件将带有<Unified>后缀,而使用间接模式的事件将带有<Indirect>后缀。对于 DirectX 光线追踪,完整事件名称是DispatchRays<Unified>或ExecuteIndirect<Rays><Unified>以及DispatchRays<Indirect>或ExecuteIndirect<Rays><Indirect>。对于 Vulkan,完整事件名称是vkCmdTraceRaysKHR<Unified>或vkCmdTraceRaysIndirectKHR<Unified>以及vkCmdTraceRaysKHR<Indirect>或vkCmdTraceRaysIndirectKHR<Indirect>。这两种编译模式之间的主要区别在于如何编译光线追踪管道中的各个着色器。在统一模式下,各个着色器将被内联到一个着色器中,从而产生一组单一的 ISA。在间接模式下,各个着色器将单独编译,并且每个着色器中的函数将成为其自己的 ISA 指令集。会在 ISA 中生成函数调用指令,以允许一个函数调用另一个函数。
指令计时视图中 ISA 代码的呈现方式遵循驱动程序和编译器处理着色器的方式。对于统一模式,存在一个单一的 ISA 流,指令计时视图将其视为一个单一的着色器。对于间接模式,存在多个指令流,每个光线追踪管道中的着色器都有一个。指令流及其相关成本按着色器显示,并按顺序出现在指令计时视图中。仅显示非零成本的着色器函数。零成本的着色器仍然可以在管道状态窗格中查看。
为了帮助导航各种着色器函数,对于使用间接编译模式的任何事件,都可以使用导出名称下拉菜单。此下拉菜单允许开发人员在多个着色器之间切换。下拉菜单包含导出列表及其指令成本。导出将按指令成本排序。Ctrl + Shift + 向上 和 Ctrl + Shift + 向下 可用于在导出名称列表中移动。此导出名称下拉菜单如下所示。
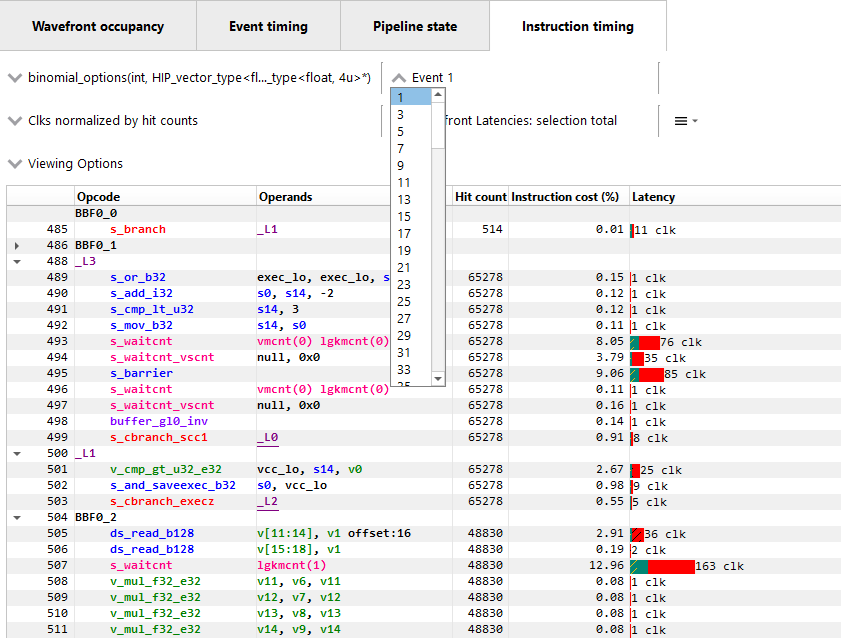
计算配置文件导航:对于为 OpenCL 或 HIP 应用程序收集的配置文件,导航控件略有不同。而不是 API PSO 下拉菜单,有一个事件名称/内核名称下拉菜单。此下拉菜单包含配置文件中找到的每个唯一内核分派的条目。选择事件名称或内核名称后,可以使用事件下拉菜单在分派选定内核的事件之间进行选择。API 着色器阶段控件在计算配置文件中不可用。键盘快捷键可用于循环浏览可用内核名称(Shift + 向上 和 Shift + 向下)以及使用选定内核在不同事件之间移动(Shift + 向左 和 Shift + 向右)。计算配置文件的导航控件如下所示。
还可以从指令计时窗格导出事件的管道二进制文件,以便在 Radeon GPU 分析器中进行分析。选择汉堡包下拉菜单(如下图所示),然后选择“在 Radeon GPU 分析器中分析管道”。为间接光线追踪事件选择此选项将保存并打开当前选定导出名称的管道二进制文件。
有关指令计时窗格中某些功能的更多信息,请参阅ISA 视图部分。
指令计时侧面板
指令计时侧面板提供有关显示的着色器的附加信息。
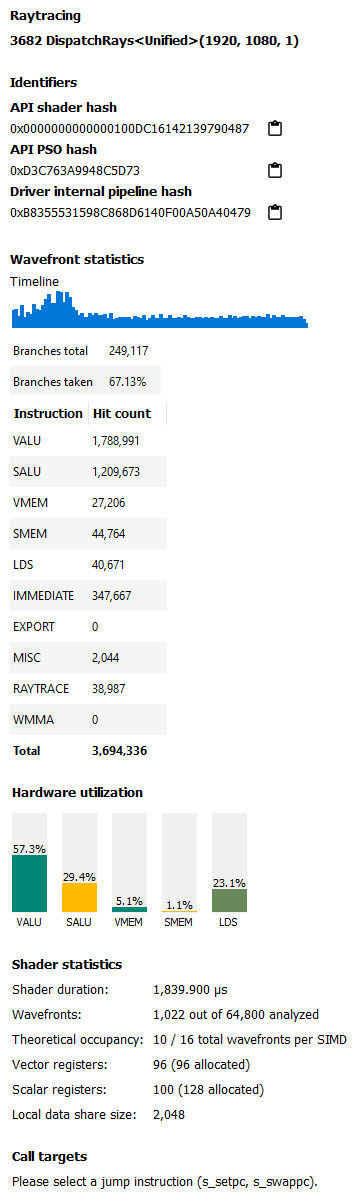
侧面板中的主要部分是
标识符:此部分包括多个哈希值,可用于标识使用的着色器及其所属的管道。
波形图统计信息:波形图统计信息提供有关选定波形图范围的信息。因此,显示的信息取决于波形图延迟下拉菜单中的选定模式以及波形图延迟直方图中选定的范围。
时间线提供了选定波形图执行时间的视觉表示。当使用直方图限制波形图范围时,时间线会更新,以便不在此范围内的波形图显示为灰色。只有在此范围内的波形图才显示为蓝色。这使您可以查看特定波形图的执行位置。例如,如果尚未预热内存缓存,则可能预期较慢的波形图会提前执行。结合使用时间线和直方图可以帮助确定瓶颈可能在哪里。
分支表显示着色器中的分支指令数量以及着色器实际执行的分支总数的百分比。
指令类型表提供了有关着色器执行的动态指令混合的信息。列表示 RDNA 和 GCN 支持的不同类型的指令。计数表示每种类别指令的数量。
每个类别的计数表示该着色器调用在此事件中的指令计数。同一着色器的不同执行可能具有不同的指令统计信息,具体取决于已启动的波形图数量和循环参数等因素。下面简要描述了指令类别。有关更多详细信息,请参阅AMD GPU ISA 文档。
-
VALU:包括向量 ALU 指令
-
SALU:包括标量 ALU 指令
-
VMEM:包括向量内存和扁平内存指令
-
SMEM:包括标量内存指令
-
LDS:包括局部数据共享指令
-
IMMEDIATE:包括立即指令,如 s_nop 和 s_waitcnt
-
EXPORT:包括导出指令
-
MISC:包括其他杂项指令,如 s_endpgm
-
RAYTRACE:包括光线追踪期间使用的 BVH 指令。仅在查看在支持光线追踪的 GPU 上捕获的配置文件时显示
-
WMMA:包括在波形矩阵乘累加运算期间使用的 WMMA 指令。仅在查看支持 WMMA 指令的 GPU 上捕获的配置文件时显示
指令类型表为着色器的结构提供了有用的摘要,特别是对于非常长的着色器。
硬件利用率:硬件利用率条形图显示了 GPU 每个功能单元的利用率,按着色器计算。
应注意,显示的利用率仅限于正在查看的着色器。例如,在所示图像中,该着色器的 VALU 利用率为 67.6%。这意味着所示的光线追踪着色器使用了 GPU VALU 容量的 67.6%。其他着色器可能正在 GPU 上并发执行。在显示条形图时,不会考虑它们对 VALU 的使用。
功能单元的利用率计算如下
利用率 % = 100 * (在功能单元上执行的所有指令的命中次数) / (已分析波形图的持续时间)
着色器统计信息:着色器统计信息部分提供了有关着色器的有用信息
-
着色器持续时间:这表示整个着色器的执行持续时间。它可以与在其他 RGP 视图(如波形图占用率和事件计时视图)中看到的相同着色器的时间进行关联。
-
波形图:这表示着色器中的总波形图数量以及用于构建指令计时可视化分析的波形图数量。预期不会分析所有波形图。原因与上面在讨论指令计时可用性时描述的相同。
-
理论占用率:根据寄存器信息和 GPU 架构知识,我们可以计算出该着色器的理论最大波形图占用率。
-
向量和标量寄存器:寄存器值指示着色器使用的寄存器数量。括号中的值是为着色器分配的寄存器数量。
-
局部数据共享大小:此值指示着色器使用的局部数据共享字节数。仅为计算着色器显示此值。
调用目标:在查看调用其他函数的着色器的数据时,当选择一个命中次数非零的“s_swappc”或“s_setpc”指令时,调用目标列表会在侧面板中显示。在 ISA 视图中,任何此类指令旁边都会显示一个字形。对于“s_swappc”指令,调用目标列表显示控制可以跳转到的导出名称,以及一个命中次数,指示每个目标被调用的次数。对于“s_setpc”指令,调用目标列表显示控制将返回的导出名称。此功能目前支持用于<Indirect>光线追踪事件以及调用执行中其他函数的 HIP 内核的管道。

RDNA 的指令计时:在 RDNA GPU 上,指令计时可能包括某些命中次数为 0 的指令。通常这是称为s_code_end的指令,也可能出现在着色器的s_endpgm指令之后。这是预期的,因为这是编译器添加的指令,用于指令预取或填充。硬件不执行此指令。
这些指令也可能出现在管道状态窗格的 ISA 视图中。