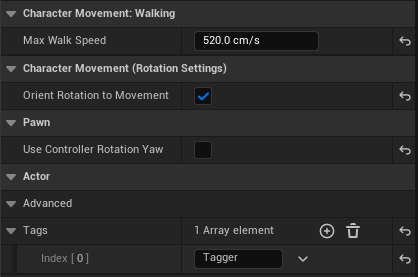
Begin Object Class=/Script/BlueprintGraph.K2Node_Event Name="K2Node_Event_0" ExportPath="/Script/BlueprintGraph.K2Node_Event'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_Event_0'" EventReference=(MemberParent="/Script/CoreUObject.Class'/Script/Schola.BlueprintScholaEnvironment'",MemberName="ResetEnvironment") bOverrideFunction=True NodePosX=16 bCommentBubblePinned=True NodeGuid=E2A5B12444A450635F4486BF48069DA0 CustomProperties Pin (PinId=2DF3BE574CF904A5941D578BF60EE8EC,PinName="OutputDelegate",Direction="EGPD_Output",PinType.PinCategory="delegate",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(MemberParent="/Script/CoreUObject.Class'/Script/Schola.BlueprintScholaEnvironment'",MemberName="ResetEnvironment"),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=C487F102410B330085732985E04BBF29,PinName="then",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_MacroInstance_1 FF108732412CAAFD501F8597007E0C1E,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_Event Name="K2Node_Event_1" ExportPath="/Script/BlueprintGraph.K2Node_Event'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_Event_1'" EventReference=(MemberParent="/Script/CoreUObject.Class'/Script/Schola.BlueprintScholaEnvironment'",MemberName="InitializeEnvironment") bOverrideFunction=True NodePosX=-80 NodePosY=688 EnabledState=Disabled bCommentBubblePinned=True bCommentBubbleVisible=True NodeComment="此节点已禁用,不会被调用。\n拖动引脚以构建功能。" NodeGuid=161E55214DB5494D390D3583F14878EC CustomProperties Pin (PinId=7622FEEE47133C552E38A884D9DE3149,PinName="OutputDelegate",Direction="EGPD_Output",PinType.PinCategory="delegate",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(MemberParent="/Script/CoreUObject.Class'/Script/Schola.BlueprintScholaEnvironment'",MemberName="InitializeEnvironment"),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=28D9494C41CEF81513F3DB8A9C8F8E2E,PinName="then",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_VariableGet Name="K2Node_VariableGet_0" ExportPath="/Script/BlueprintGraph.K2Node_VariableGet'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_VariableGet_0'" VariableReference=(MemberName="Agents",MemberGuid=7506987E42853972E743F28D0C20162E,bSelfContext=True) NodePosX=80 NodePosY=80 NodeGuid=8B67C54342717EA4ADAAA58DCEBC6AE5 CustomProperties Pin (PinId=7E2259074CA25A353E11D4A2E934E350,PinName="Agents",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=Array,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_MacroInstance_1 C12E5CDA44F0CBFA380363B1E838CFCD,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=15338A234FAB34B99DCF58865F29756A,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "Target", "目标"),PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment_C'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=True,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_MacroInstance Name="K2Node_MacroInstance_1" ExportPath="/Script/BlueprintGraph.K2Node_MacroInstance'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_MacroInstance_1'" MacroGraphReference=(MacroGraph="/Script/Engine.EdGraph'/Engine/EditorBlueprintResources/StandardMacros.StandardMacros:ForEachLoop'",GraphBlueprint="/Script/Engine.Blueprint'/Engine/EditorBlueprintResources/StandardMacros.StandardMacros'",GraphGuid=99DBFD5540A796041F72A5A9DA655026) ResolvedWildcardType=(PinCategory="object",PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",ContainerType=Array) NodePosX=240 NodeGuid=859D80F04C40C518A577C6A274B71823 CustomProperties Pin (PinId=FF108732412CAAFD501F8597007E0C1E,PinName="Exec",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_Event_0 C487F102410B330085732985E04BBF29,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=C12E5CDA44F0CBFA380363B1E838CFCD,PinName="Array",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=Array,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_VariableGet_0 7E2259074CA25A353E11D4A2E934E350,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=4803ECAC4D7C84C77D1B81A5A490FC20,PinName="LoopBody",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CallFunction_0 7BE2FA184D8D2D4FE6AD77824944B4E2,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=5C11CE014B1FB1D9068E22A8A46634F3,PinName="Array Element",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_Knot_2 708C81754E9F710D4546D484A9068EAD,K2Node_Knot_3 CE362F354FC45C78A80BF981BFE7C1C8,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=C7B6ACE44A70B47878C0C1B64FFD3025,PinName="Array Index",Direction="EGPD_Output",PinType.PinCategory="int",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=78F66B62412288D0501EBDAE7EC205C1,PinName="Completed",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_CallFunction Name="K2Node_CallFunction_0" ExportPath="/Script/BlueprintGraph.K2Node_CallFunction'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_CallFunction_0'" FunctionReference=(MemberParent="/Script/CoreUObject.Class'/Script/NavigationSystem.NavigationSystemV1'",MemberName="K2_GetRandomLocationInNavigableRadius") NodePosX=480 NodeGuid=0401AAB849412CEBFF9DFE96F93A62A8 CustomProperties Pin (PinId=7BE2FA184D8D2D4FE6AD77824944B4E2,PinName="execute",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_MacroInstance_1 4803ECAC4D7C84C77D1B81A5A490FC20,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=A6E573794EC15D1535269FA63FDB7234,PinName="then",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CallFunction_2 CF9470BF440ABB07A20AADB8FF01B2F3,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=7D1074764D26E2B3BF3B19922E9FBFBC,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "Target", "目标"),PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/NavigationSystem.NavigationSystemV1'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultObject="/Script/NavigationSystem.Default__NavigationSystemV1",PersistentGuid=00000000000000000000000000000000,bHidden=True,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=95661674461F2C15F70DDDB6733047CB,PinName="WorldContextObject",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/CoreUObject.Object'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=True,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=03CC41BF4027085FD70A6C8DF0B83E75,PinName="Origin",PinType.PinCategory="struct",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.ScriptStruct'/Script/CoreUObject.Vector'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=True,PinType.bIsConst=True,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="0, 0, 0",AutogeneratedDefaultValue="0, 0, 0",LinkedTo=(K2Node_CallFunction_6 AA682079412CBBAB2133B6AA15EB50D2,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=True,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=29751CE444FB25F6AB1C91A1783E1D0F,PinName="RandomLocation",Direction="EGPD_Output",PinType.PinCategory="struct",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.ScriptStruct'/Script/CoreUObject.Vector'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="0, 0, 0",AutogeneratedDefaultValue="0, 0, 0",LinkedTo=(K2Node_CallFunction_2 A83B7E3A43A33CD5DC9E6B804D8252CC,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=4AC7F3BC4A1641FD474D5FBA215BBB29,PinName="Radius",PinType.PinCategory="real",PinType.PinSubCategory="float",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="1000.000000",AutogeneratedDefaultValue="0.0",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=44949B314BF3179BDF4D2094823D58E2,PinName="NavData",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/NavigationSystem.NavigationData'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,AutogeneratedDefaultValue="None",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=D62D85A24D2EF96B79B957BB924AA724,PinName="FilterClass",PinType.PinCategory="class",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/NavigationSystem.NavigationQueryFilter'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=True,PinType.bSerializeAsSinglePrecisionFloat=False,AutogeneratedDefaultValue="None",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=280A2E5A4E07FFDB8D24E9BB07267313,PinName="ReturnValue",Direction="EGPD_Output",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="false",AutogeneratedDefaultValue="false",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_CallFunction Name="K2Node_CallFunction_2" ExportPath="/Script/BlueprintGraph.K2Node_CallFunction'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_CallFunction_2'" FunctionReference=(MemberName="K2_SetActorLocation",bSelfContext=True) NodePosX=832 NodePosY=-16 NodeGuid=E2C24ABF4F65BAF9D965EDA4FDE6E843 CustomProperties Pin (PinId=CF9470BF440ABB07A20AADB8FF01B2F3,PinName="execute",PinToolTip="\n执行",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CallFunction_0 A6E573794EC15D1535269FA63FDB7234,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=278ECEC24053F5411BE6E38F9024E143,PinName="then",PinToolTip="\n执行",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_DynamicCast_1 4979277B47BF10A3EFE678B6B2BA4EF7,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=39844A7F4CA136C54493B8823DE0F250,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "Target", "目标"),PinToolTip="目标\nActor Object Reference",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Actor'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_Knot_4 292148C04999D59D10B9D7A9FBFA7B1F,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=A83B7E3A43A33CD5DC9E6B804D8252CC,PinName="NewLocation",PinToolTip="新位置\nVector\n\nActor移动到的新位置。",PinType.PinCategory="struct",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.ScriptStruct'/Script/CoreUObject.Vector'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="0, 0, 0",AutogeneratedDefaultValue="0, 0, 0",LinkedTo=(K2Node_CallFunction_0 29751CE444FB25F6AB1C91A1783E1D0F,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=B521A36B42104242E05A76BBDA5E5296,PinName="bSweep",PinToolTip="bSweep\nBoolean\n\n是否沿着目标位置进行扫掠,沿途触发重叠并可能因阻挡而提前停止。仅根组件会进行扫掠并检查碰撞,子组件会无扫掠地移动。如果碰撞关闭,则此项无效。",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="false",AutogeneratedDefaultValue="false",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=8EC080E9453776F468A424A314AF3B65,PinName="SweepHitResult",PinToolTip="SweepHitResult\nHit Result Structure\n\n如果进行了扫掠,则为移动的命中结果。",Direction="EGPD_Output",PinType.PinCategory="struct",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.ScriptStruct'/Script/Engine.HitResult'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=9BEC3F5244634775B210F481155A4CCD,PinName="bTeleport",PinToolTip="bTeleport\nBoolean\n\n是否传送物理状态(如果此对象启用了物理碰撞)。如果为true,则物理速度不变(因此布娃娃部件不受位置变化影响)。如果为false,则根据位置变化更新物理速度(会影响布娃娃部件)。如果启用了CCD且不传送,则会影响沿整个扫掠体积的物体。请注意,在传送时,任何子/附加组件也会被传送,并保持其当前偏移量,即使它们正在被模拟。在不传送的情况下设置位置将不会更新模拟的子/附加组件的位置。",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="false",AutogeneratedDefaultValue="false",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=820EC2D841E3BB57782AB7A2104EA2C3,PinName="ReturnValue",PinToolTip="返回值\nBoolean\n\n指示是否成功设置了位置(如果未扫掠),或者是否发生了移动(如果进行了扫掠)。",Direction="EGPD_Output",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="false",AutogeneratedDefaultValue="false",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_CallFunction Name="K2Node_CallFunction_6" ExportPath="/Script/BlueprintGraph.K2Node_CallFunction'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_CallFunction_6'" bIsPureFunc=True bIsConstFunc=True FunctionReference=(MemberName="K2_GetActorLocation",bSelfContext=True) NodePosX=176 NodePosY=160 NodeGuid=668F581C40EA2D447E270298C2E58E57 CustomProperties Pin (PinId=52028A6C45C5C88E50BED4B3A3DE8568,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "Target", "目标"),PinToolTip="目标\nActor Object Reference",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Actor'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=AA682079412CBBAB2133B6AA15EB50D2,PinName="ReturnValue",PinToolTip="返回值\nVector\n\n返回此Actor的根组件的位置",Direction="EGPD_Output",PinType.PinCategory="struct",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.ScriptStruct'/Script/CoreUObject.Vector'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="0, 0, 0",AutogeneratedDefaultValue="0, 0, 0",LinkedTo=(K2Node_CallFunction_0 03CC41BF4027085FD70A6C8DF0B83E75,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_DynamicCast Name="K2Node_DynamicCast_0" ExportPath="/Script/BlueprintGraph.K2Node_DynamicCast'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_DynamicCast_0'" TargetType="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/RunnerTrainer.RunnerTrainer_C'" NodePosX=1136 NodePosY=176 NodeGuid=840EB31E45EE1D8444EA579365511F27 CustomProperties Pin (PinId=D8FED54E4B9118D7D7EBF7B5BA9B2906,PinName="execute",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_DynamicCast_1 B2C0D9084A63EB24E9F394AED49B25B7,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=195A225741144DB60E231F9F17EB2251,PinName="then",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_VariableSet_2 1AA219C548DB672F707F3296E9863207,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=4B17C9704ADD7DA0BD4F4D825A6ABCBE,PinName="CastFailed",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=F69841634A59460A05F61CB131C77E27,PinName="Object",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/CoreUObject.Object'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CallFunction_4 619D6E2E409916737B32469EF3507D5B,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=2B773ADE487EA96C815CB3BD3ABB91B3,PinName="AsRunner Trainer",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/RunnerTrainer.RunnerTrainer_C'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_VariableSet_2 6D012F384091D2ED5C5BC8AE525C7C96,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=7A64C1E84FE20432CEB5889F4C68DC36,PinName="bSuccess",Direction="EGPD_Output",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=True,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_DynamicCast Name="K2Node_DynamicCast_1" ExportPath="/Script/BlueprintGraph.K2Node_DynamicCast'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_DynamicCast_1'" TargetType="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TaggerTrainer.TaggerTrainer_C'" NodePosX=1136 NodeGuid=186D7DBA41DF62AA49B5EB96FCB2E07C CustomProperties Pin (PinId=4979277B47BF10A3EFE678B6B2BA4EF7,PinName="execute",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CallFunction_2 278ECEC24053F5411BE6E38F9024E143,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=B0D5A05448DF45805F0008A9E56E421E,PinName="then",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_VariableSet_0 98DD5DBA474BC69FAF3D30931CBBCEC9,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=B2C0D9084A63EB24E9F394AED49B25B7,PinName="CastFailed",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_DynamicCast_0 D8FED54E4B9118D7D7EBF7B5BA9B2906,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=4BF25D7643C842D6ABE26989D3772B9C,PinName="Object",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/CoreUObject.Object'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CallFunction_4 619D6E2E409916737B32469EF3507D5B,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=F557DFFB419A2CEE1F1E96839013A1F4,PinName="AsTagger Trainer",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TaggerTrainer.TaggerTrainer_C'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_VariableSet_0 931A89754722DE362CD09EBFC2F2B13D,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=9D06AA2D4ACF35666795839AD913D525,PinName="bSuccess",Direction="EGPD_Output",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=True,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_CallFunction Name="K2Node_CallFunction_4" ExportPath="/Script/BlueprintGraph.K2Node_CallFunction'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_CallFunction_4'" bIsPureFunc=True bIsConstFunc=True FunctionReference=(MemberParent="/Script/CoreUObject.Class'/Script/Engine.Pawn'",MemberName="GetController") NodePosX=880 NodePosY=208 NodeGuid=B0C2D93C4D7BFE80AEA616A215896D33 CustomProperties Pin (PinId=18F38D9B4BE77B0E2C8EC3801F36610F,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "Target", "目标"),PinToolTip="目标\nPawn Object Reference",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_Knot_2 9E578CF6479EC14DA2A9DEB2C40DA4D7,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=619D6E2E409916737B32469EF3507D5B,PinName="ReturnValue",PinToolTip="返回值\nController Object Reference\n\n返回此Actor的控制器。",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Controller'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_DynamicCast_0 F69841634A59460A05F61CB131C77E27,K2Node_DynamicCast_1 4BF25D7643C842D6ABE26989D3772B9C,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_VariableSet Name="K2Node_VariableSet_0" ExportPath="/Script/BlueprintGraph.K2Node_VariableSet'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_VariableSet_0'" VariableReference=(MemberParent="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TaggerTrainer.TaggerTrainer_C'",MemberName="CaughtTarget",MemberGuid=F276D4F74ACD6490A8B878B662AB449A) SelfContextInfo=NotSelfContext NodePosX=1392 NodePosY=16 NodeGuid=D594AB40462AF30A16199AA67C478CA1 CustomProperties Pin (PinId=98DD5DBA474BC69FAF3D30931CBBCEC9,PinName="execute",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_DynamicCast_1 B0D5A05448DF45805F0008A9E56E421E,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=F173D44641DD3325B37C2998E6BFF0F5,PinName="then",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=04976F864BA99474B4B188B26C0C8745,PinName="CaughtTarget",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="false",AutogeneratedDefaultValue="false",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=1D12A4084193C95813AD71BC4D81B3C5,PinName="Output_Get",PinToolTip="检索变量的值,可替代单独的Get节点",Direction="EGPD_Output",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="false",AutogeneratedDefaultValue="false",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=931A89754722DE362CD09EBFC2F2B13D,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "Target", "目标"),PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TaggerTrainer.TaggerTrainer_C'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_DynamicCast_1 F557DFFB419A2CEE1F1E96839013A1F4,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_VariableSet Name="K2Node_VariableSet_2" ExportPath="/Script/BlueprintGraph.K2Node_VariableSet'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_VariableSet_2'" VariableReference=(MemberParent="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/RunnerTrainer.RunnerTrainer_C'",MemberName="Caught Target",MemberGuid=8D3007844B02CFE2ACAB31B29002F599) SelfContextInfo=NotSelfContext NodePosX=1392 NodePosY=192 NodeGuid=130A8FA64BC1AD7D56809C8255762BA4 CustomProperties Pin (PinId=1AA219C548DB672F707F3296E9863207,PinName="execute",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_DynamicCast_0 195A225741144DB60E231F9F17EB2251,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=C503B27541164C473F88E79BF5DEE75D,PinName="then",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=55C89E5F4FA58762544CCC9CF29A0147,PinName="Caught Target",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="false",AutogeneratedDefaultValue="false",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=D06FCE6548C71B530FFE2CA1D473A25D,PinName="Output_Get",PinToolTip="检索变量的值,可替代单独的Get节点",Direction="EGPD_Output",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="false",AutogeneratedDefaultValue="false",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=6D012F384091D2ED5C5BC8AE525C7C96,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "Target", "目标"),PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/RunnerTrainer.RunnerTrainer_C'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_DynamicCast_0 2B773ADE487EA96C815CB3BD3ABB91B3,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_Event Name="K2Node_Event_2" ExportPath="/Script/BlueprintGraph.K2Node_Event'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_Event_2'" EventReference=(MemberParent="/Script/CoreUObject.Class'/Script/Engine.Actor'",MemberName="ReceiveBeginPlay") bOverrideFunction=True NodePosX=64 NodePosY=-563 NodeGuid=29508A2342C1D362357408B2576D91BC CustomProperties Pin (PinId=24AFE79849E3E0971C8D6BA7D587D086,PinName="OutputDelegate",Direction="EGPD_Output",PinType.PinCategory="delegate",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(MemberParent="/Script/CoreUObject.Class'/Script/Engine.Actor'",MemberName="ReceiveBeginPlay"),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=210F946844E44D528488F490E363DD30,PinName="then",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_MacroInstance_0 FF108732412CAAFD501F8597007E0C1E,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_CustomEvent Name="K2Node_CustomEvent_1" ExportPath="/Script/BlueprintGraph.K2Node_CustomEvent'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_CustomEvent_1'" CustomFunctionName="OnActorHit_Event" NodePosX=64 NodePosY=-272 NodeGuid=AD7675024F5F7F54BAE001A7D39B62D8 CustomProperties Pin (PinId=EA43A4C7464528E8A9E53D940B6D732E,PinName="OutputDelegate",Direction="EGPD_Output",PinType.PinCategory="delegate",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(MemberParent="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment_C'",MemberName="OnActorHit_Event",MemberGuid=AD7675024F5F7F54BAE001A7D39B62D8),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_Knot_1 883B07CB4E48A8349C5D03907A6756D5,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=C706DC8D420B8DA0A0097FA8D45DDAA7,PinName="then",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_IfThenElse_0 03A0AC65494394A18D552589B29A9CCC,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=53D8B433423A60D9733060ACECCABFA0,PinName="SelfActor",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Actor'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CallFunction_3 5987309043BB2E3774B410AEA0C17456,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=4372A593493BAF75BA26E9B138441C23,PinName="OtherActor",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Actor'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CallFunction_8 67E7D5C54FAB47CCDD5B92A5588C82AA,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=045B07CB4B77BEF51D77E8A17D756394,PinName="NormalImpulse",Direction="EGPD_Output",PinType.PinCategory="struct",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.ScriptStruct'/Script/CoreUObject.Vector'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=F9941B1A42C1BAC55FF93E9B351D7317,PinName="Hit",Direction="EGPD_Output",PinType.PinCategory="struct",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.ScriptStruct'/Script/Engine.HitResult'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=True,PinType.bIsConst=True,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties UserDefinedPin (PinName="SelfActor",PinType=(PinCategory="object",PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Actor'"),DesiredPinDirection=EGPD_Output) CustomProperties UserDefinedPin (PinName="OtherActor",PinType=(PinCategory="object",PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Actor'"),DesiredPinDirection=EGPD_Output) CustomProperties UserDefinedPin (PinName="NormalImpulse",PinType=(PinCategory="struct",PinSubCategoryObject="/Script/CoreUObject.ScriptStruct'/Script/CoreUObject.Vector'"),DesiredPinDirection=EGPD_Output) CustomProperties UserDefinedPin (PinName="Hit",PinType=(PinCategory="struct",PinSubCategoryObject="/Script/CoreUObject.ScriptStruct'/Script/Engine.HitResult'",bIsReference=True,bIsConst=True),DesiredPinDirection=EGPD_Output) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_AssignDelegate Name="K2Node_AssignDelegate_0" ExportPath="/Script/BlueprintGraph.K2Node_AssignDelegate'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_AssignDelegate_0'" DelegateReference=(MemberParent="/Script/CoreUObject.Class'/Script/Engine.Actor'",MemberName="OnActorHit") NodePosX=944 NodePosY=-560 NodeGuid=091B833F4AACC21AE14D4493691D459D CustomProperties Pin (PinId=54BCC3C040BBAE24809340B08A50B18A,PinName="execute",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_IfThenElse_1 D598840449EC8BE11C27619D156F7995,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=4CC11E3E4D1AC1C744F2D88F0030DCB3,PinName="then",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=406B8F9C41691D76511A5DA31480BA8A,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "BaseMCDelegateSelfPinName", "目标"),PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Actor'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_MacroInstance_0 5C11CE014B1FB1D9068E22A8A46634F3,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=54F9F2D24AAC34266BFBA8ACE4631D7A,PinName="Delegate",PinFriendlyName=NSLOCTEXT("K2Node", "PinFriendlyDelegatetName", "事件"),PinType.PinCategory="delegate",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(MemberParent="/Script/CoreUObject.Package'/Script/Engine'",MemberName="ActorHitSignature__DelegateSignature"),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=True,PinType.bIsConst=True,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_Knot_0 5EF85817428989E5072F899B0B220925,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_CallFunction Name="K2Node_CallFunction_8" ExportPath="/Script/BlueprintGraph.K2Node_CallFunction'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_CallFunction_8'" bIsPureFunc=True bIsConstFunc=True FunctionReference=(MemberName="ActorHasTag",bSelfContext=True) NodePosX=256 NodePosY=-192 NodeGuid=556245CF4CE675CAB899BA9DA2912004 CustomProperties Pin (PinId=67E7D5C54FAB47CCDD5B92A5588C82AA,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "Target", "目标"),PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Actor'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CustomEvent_1 4372A593493BAF75BA26E9B138441C23,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=F7B1DE6A4F8D4A63058938AFD261E0FB,PinName="Tag",PinType.PinCategory="name",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="Runner",AutogeneratedDefaultValue="None",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=99B2EAEF406D499660B11FAF5FBB64AE,PinName="ReturnValue",Direction="EGPD_Output",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="false",AutogeneratedDefaultValue="false",LinkedTo=(K2Node_IfThenElse_0 2468A564476859196A61DCAB1102A6A0,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_VariableGet Name="K2Node_VariableGet_1" ExportPath="/Script/BlueprintGraph.K2Node_VariableGet'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_VariableGet_1'" VariableReference=(MemberName="Agents",MemberGuid=7506987E42853972E743F28D0C20162E,bSelfContext=True) NodePosX=80 NodePosY=-480 NodeGuid=4A00B1094D4956D25FD5DF8F8703C8EA CustomProperties Pin (PinId=44F71E344E6F479D0A6FDFBC449100C6,PinName="Agents",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=Array,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_MacroInstance_0 C12E5CDA44F0CBFA380363B1E838CFCD,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=7E2879E941E45255B268EB91D1C1A16F,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "Target", "目标"),PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment_C'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=True,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_MacroInstance Name="K2Node_MacroInstance_0" ExportPath="/Script/BlueprintGraph.K2Node_MacroInstance'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_MacroInstance_0'" MacroGraphReference=(MacroGraph="/Script/Engine.EdGraph'/Engine/EditorBlueprintResources/StandardMacros.StandardMacros:ForEachLoop'",GraphBlueprint="/Script/Engine.Blueprint'/Engine/EditorBlueprintResources/StandardMacros.StandardMacros'",GraphGuid=99DBFD5540A796041F72A5A9DA655026) ResolvedWildcardType=(PinCategory="object",PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",ContainerType=Array) NodePosX=240 NodePosY=-560 NodeGuid=2F9150FB469BBFE06C2ABF8603ABE149 CustomProperties Pin (PinId=FF108732412CAAFD501F8597007E0C1E,PinName="Exec",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_Event_2 210F946844E44D528488F490E363DD30,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=C12E5CDA44F0CBFA380363B1E838CFCD,PinName="Array",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=Array,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_VariableGet_1 44F71E344E6F479D0A6FDFBC449100C6,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=4803ECAC4D7C84C77D1B81A5A490FC20,PinName="LoopBody",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_IfThenElse_1 BDC0DBC84E5200F4874A728C81CC9F3B,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=5C11CE014B1FB1D9068E22A8A46634F3,PinName="Array Element",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_AssignDelegate_0 406B8F9C41691D76511A5DA31480BA8A,K2Node_CallFunction_5 67E7D5C54FAB47CCDD5B92A5588C82AA,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=C7B6ACE44A70B47878C0C1B64FFD3025,PinName="Array Index",Direction="EGPD_Output",PinType.PinCategory="int",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=78F66B62412288D0501EBDAE7EC205C1,PinName="Completed",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_IfThenElse Name="K2Node_IfThenElse_0" ExportPath="/Script/BlueprintGraph.K2Node_IfThenElse'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_IfThenElse_0'" NodePosX=544 NodePosY=-288 NodeGuid=45AF444540E8DDB291B7BF9E856319FA CustomProperties Pin (PinId=03A0AC65494394A18D552589B29A9CCC,PinName="execute",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CustomEvent_1 C706DC8D420B8DA0A0097FA8D45DDAA7,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=2468A564476859196A61DCAB1102A6A0,PinName="Condition",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="true",AutogeneratedDefaultValue="true",LinkedTo=(K2Node_CallFunction_8 99B2EAEF406D499660B11FAF5FBB64AE,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=2BE86EDC4053183318E2849BFF81DE11,PinName="then",PinFriendlyName=NSLOCTEXT("K2Node", "true", "true"),Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CallFunction_13 79DDBAB4457C12963480678CAE89C52C,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=BDED667E4C2A1D29A5C50DB4F270B253,PinName="else",PinFriendlyName=NSLOCTEXT("K2Node", "false", "false"),Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_DynamicCast_2 0DFABE2143324D597AF2DB8A02A9C0F5,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_CallFunction Name="K2Node_CallFunction_13" ExportPath="/Script/BlueprintGraph.K2Node_CallFunction'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_CallFunction_13'" FunctionReference=(MemberName="SetRunnerTagged",MemberGuid=13D346EA4979265E7C225E8E6EC055FD,bSelfContext=True) NodePosX=832 NodePosY=-336 NodeGuid=41323579437466F09538B48823AD2AD4 CustomProperties Pin (PinId=79DDBAB4457C12963480678CAE89C52C,PinName="execute",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_IfThenElse_0 2BE86EDC4053183318E2849BFF81DE11,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=483C431B4615079BE9002DA9A7062E33,PinName="then",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=06A967B94CBD6591278DB59A0C786350,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "Target", "目标"),PinType.PinCategory="object",PinType.PinSubCategory="self",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_CallFunction Name="K2Node_CallFunction_5" ExportPath="/Script/BlueprintGraph.K2Node_CallFunction'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_CallFunction_5'" bIsPureFunc=True bIsConstFunc=True FunctionReference=(MemberName="ActorHasTag",bSelfContext=True) NodePosX=464 NodePosY=-464 NodeGuid=4364D8D14E6E7DB38A7E79B64D7D3430 CustomProperties Pin (PinId=67E7D5C54FAB47CCDD5B92A5588C82AA,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "Target", "目标"),PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Actor'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_MacroInstance_0 5C11CE014B1FB1D9068E22A8A46634F3,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=F7B1DE6A4F8D4A63058938AFD261E0FB,PinName="Tag",PinType.PinCategory="name",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="Tagger",AutogeneratedDefaultValue="None",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=99B2EAEF406D499660B11FAF5FBB64AE,PinName="ReturnValue",Direction="EGPD_Output",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="false",AutogeneratedDefaultValue="false",LinkedTo=(K2Node_IfThenElse_1 CCF81E624FAB60F4D808F9AB58477921,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_IfThenElse Name="K2Node_IfThenElse_1" ExportPath="/Script/BlueprintGraph.K2Node_IfThenElse'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_IfThenElse_1'" NodePosX=752 NodePosY=-560 NodeGuid=5D8DDDB344ED11B6C8FAEBB3B0F7E7B9 CustomProperties Pin (PinId=BDC0DBC84E5200F4874A728C81CC9F3B,PinName="execute",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_MacroInstance_0 4803ECAC4D7C84C77D1B81A5A490FC20,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=CCF81E624FAB60F4D808F9AB58477921,PinName="Condition",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="true",AutogeneratedDefaultValue="true",LinkedTo=(K2Node_CallFunction_5 99B2EAEF406D499660B11FAF5FBB64AE,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=D598840449EC8BE11C27619D156F7995,PinName="then",PinFriendlyName=NSLOCTEXT("K2Node", "true", "true"),Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_AssignDelegate_0 54BCC3C040BBAE24809340B08A50B18A,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=296A70FE42DA36E63C6C2796167C74BC,PinName="else",PinFriendlyName=NSLOCTEXT("K2Node", "false", "false"),Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_CallFunction Name="K2Node_CallFunction_3" ExportPath="/Script/BlueprintGraph.K2Node_CallFunction'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_CallFunction_3'" bIsPureFunc=True bIsConstFunc=True FunctionReference=(MemberName="GetInstigatorController",bSelfContext=True) NodePosX=544 NodePosY=-193 NodeGuid=89EE8C7E4409F6A48875F8A9C766F046 CustomProperties Pin (PinId=5987309043BB2E3774B410AEA0C17456,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "Target", "目标"),PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Actor'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CustomEvent_1 53D8B433423A60D9733060ACECCABFA0,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=91CE33B54A85A1E1EDBB77B0690F3941,PinName="ReturnValue",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Controller'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_DynamicCast_2 95FF715E470705A3B5E7E1ADC1DED1B1,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_DynamicCast Name="K2Node_DynamicCast_2" ExportPath="/Script/BlueprintGraph.K2Node_DynamicCast'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_DynamicCast_2'" TargetType="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TaggerTrainer.TaggerTrainer_C'" NodePosX=832 NodePosY=-208 NodeGuid=9919D2DF40D5D6387AF84CA2A813004E CustomProperties Pin (PinId=0DFABE2143324D597AF2DB8A02A9C0F5,PinName="execute",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_IfThenElse_0 BDED667E4C2A1D29A5C50DB4F270B253,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=229B57E440DB1C04917A459CC4124095,PinName="then",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_VariableSet_3 4EE016E44ED78EB044BD76A1225D24F7,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=2DF738FE47DEC0B445F0718989A86904,PinName="CastFailed",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=95FF715E470705A3B5E7E1ADC1DED1B1,PinName="Object",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/CoreUObject.Object'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CallFunction_3 91CE33B54A85A1E1EDBB77B0690F3941,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=395D1B6E4E2ECF90F061D080625604D4,PinName="AsTagger Trainer",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TaggerTrainer.TaggerTrainer_C'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_VariableSet_3 02DAB7894A4C5DD31AB8D09A25348DE3,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=EC3E6957476584A94666A8B4BB386EBD,PinName="bSuccess",Direction="EGPD_Output",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=True,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_VariableSet Name="K2Node_VariableSet_3" ExportPath="/Script/BlueprintGraph.K2Node_VariableSet'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_VariableSet_3'" VariableReference=(MemberParent="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TaggerTrainer.TaggerTrainer_C'",MemberName="HitWall",MemberGuid=B8C015344AB87443F60F2C98275882B1) SelfContextInfo=NotSelfContext NodePosX=1088 NodePosY=-193 ErrorType=1 NodeGuid=8F78D07E442C656DC115419F72B1E60A CustomProperties Pin (PinId=4EE016E44ED78EB044BD76A1225D24F7,PinName="execute",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_DynamicCast_2 229B57E440DB1C04917A459CC4124095,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=B4AD9D4445C798AA39669BB7A3346AAB,PinName="then",Direction="EGPD_Output",PinType.PinCategory="exec",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=E7A85BEF4424E7275FF3DAA6EDDAD23E,PinName="HitWall",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="true",AutogeneratedDefaultValue="false",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=6056A3EE43A0E9A8099542A3D790B04A,PinName="Output_Get",PinToolTip="检索变量的值,可替代单独的Get节点",Direction="EGPD_Output",PinType.PinCategory="bool",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,DefaultValue="false",AutogeneratedDefaultValue="false",PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=02DAB7894A4C5DD31AB8D09A25348DE3,PinName="self",PinFriendlyName=NSLOCTEXT("K2Node", "Target", "目标"),PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TaggerTrainer.TaggerTrainer_C'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_DynamicCast_2 395D1B6E4E2ECF90F061D080625604D4,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_Knot Name="K2Node_Knot_0" ExportPath="/Script/BlueprintGraph.K2Node_Knot'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_Knot_0'" NodePosX=752 NodePosY=-336 NodeGuid=7DF5D5934B67F3C3AE842ABAE0013227 CustomProperties Pin (PinId=5FD8996940FBAEE991423CBB7DC1F29B,PinName="InputPin",PinType.PinCategory="delegate",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(MemberParent="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment_C'",MemberName="OnActorHit_Event",MemberGuid=AD7675024F5F7F54BAE001A7D39B62D8),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_Knot_1 D2FE482446B791A4100647819859B46E,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=True,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=5EF85817428989E5072F899B0B220925,PinName="OutputPin",Direction="EGPD_Output",PinType.PinCategory="delegate",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(MemberParent="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment_C'",MemberName="OnActorHit_Event",MemberGuid=AD7675024F5F7F54BAE001A7D39B62D8),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_AssignDelegate_0 54F9F2D24AAC34266BFBA8ACE4631D7A,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_Knot Name="K2Node_Knot_1" ExportPath="/Script/BlueprintGraph.K2Node_Knot'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_Knot_1'" NodePosX=320 NodePosY=-336 NodeGuid=2EB895A44E97C9C1D45AF595CDDD0B18 CustomProperties Pin (PinId=883B07CB4E48A8349C5D03907A6756D5,PinName="InputPin",PinType.PinCategory="delegate",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(MemberParent="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment_C'",MemberName="OnActorHit_Event",MemberGuid=AD7675024F5F7F54BAE001A7D39B62D8),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CustomEvent_1 EA43A4C7464528E8A9E53D940B6D732E,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=True,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=D2FE482446B791A4100647819859B46E,PinName="OutputPin",Direction="EGPD_Output",PinType.PinCategory="delegate",PinType.PinSubCategory="",PinType.PinSubCategoryObject=None,PinType.PinSubCategoryMemberReference=(MemberParent="/Script/Engine.BlueprintGeneratedClass'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment_C'",MemberName="OnActorHit_Event",MemberGuid=AD7675024F5F7F54BAE001A7D39B62D8),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_Knot_0 5FD8996940FBAEE991423CBB7DC1F29B,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_Knot Name="K2Node_Knot_2" ExportPath="/Script/BlueprintGraph.K2Node_Knot'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_Knot_2'" NodePosX=496 NodePosY=256 NodeGuid=D98E3AE842B081E192C0C6A632F229FB CustomProperties Pin (PinId=708C81754E9F710D4546D484A9068EAD,PinName="InputPin",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_MacroInstance_1 5C11CE014B1FB1D9068E22A8A46634F3,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=True,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=9E578CF6479EC14DA2A9DEB2C40DA4D7,PinName="OutputPin",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CallFunction_4 18F38D9B4BE77B0E2C8EC3801F36610F,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_Knot Name="K2Node_Knot_3" ExportPath="/Script/BlueprintGraph.K2Node_Knot'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_Knot_3'" NodePosX=464 NodePosY=-32 NodeGuid=6D47A4C4441B6E02DD2E1C9D1DF1F817 CustomProperties Pin (PinId=CE362F354FC45C78A80BF981BFE7C1C8,PinName="InputPin",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_MacroInstance_1 5C11CE014B1FB1D9068E22A8A46634F3,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=True,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=5869322341A6B2BA9D9B1189955032A1,PinName="OutputPin",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_Knot_4 C5618F654E86883CFA093F8368E58DDA,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object Begin Object Class=/Script/BlueprintGraph.K2Node_Knot Name="K2Node_Knot_4" ExportPath="/Script/BlueprintGraph.K2Node_Knot'/Game/Examples/Tag/Blueprints/TagEnvironment.TagEnvironment:EventGraph.K2Node_Knot_4'" NodePosX=752 NodePosY=-32 NodeGuid=AEB0AD544123977C11C688A0D3FE46C0 CustomProperties Pin (PinId=C5618F654E86883CFA093F8368E58DDA,PinName="InputPin",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_Knot_3 5869322341A6B2BA9D9B1189955032A1,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=True,bAdvancedView=False,bOrphanedPin=False,) CustomProperties Pin (PinId=292148C04999D59D10B9D7A9FBFA7B1F,PinName="OutputPin",Direction="EGPD_Output",PinType.PinCategory="object",PinType.PinSubCategory="",PinType.PinSubCategoryObject="/Script/CoreUObject.Class'/Script/Engine.Pawn'",PinType.PinSubCategoryMemberReference=(),PinType.PinValueType=(),PinType.ContainerType=None,PinType.bIsReference=False,PinType.bIsConst=False,PinType.bIsWeakPointer=False,PinType.bIsUObjectWrapper=False,PinType.bSerializeAsSinglePrecisionFloat=False,LinkedTo=(K2Node_CallFunction_2 39844A7F4CA136C54493B8823DE0F250,),PersistentGuid=00000000000000000000000000000000,bHidden=False,bNotConnectable=False,bDefaultValueIsReadOnly=False,bDefaultValueIsIgnored=False,bAdvancedView=False,bOrphanedPin=False,) End Object