AMD FidelityFX™ Hybrid Shadows 示例
本示例演示了如何将光线追踪阴影和光栅化阴影图结合起来,以实现高质量和高性能。
性能 指南
优化现代实时渲染器可能是一项艰巨的任务。显式 API 提供了比以往更多的帧制作控制权,让您能够实现更高的帧率、更美的像素,并最终更好地利用硬件。
我们的 AMD RDNA™ 性能指南,更新至 RDNA 3,将通过一系列零散的技巧和窍门,帮助您指导您完成优化过程,旨在支持您的性能优化之旅。
本页上的许多性能建议都可通过 Microsoft® PIX 和 Vulkan® 的最佳实践验证层获得。
| DirectX® 12 | Vulkan® |
|---|---|
| 如果您是 DirectX® 12 开发者,您会发现许多 AMD 特定的检查已集成到 Microsoft® PIX 性能调整和调试工具中。 | 如果您是 Vulkan® 开发者,从 SDK 版本 1.2.189 起,您会发现在最佳实践验证层中已集成 AMD 特定的检查。 |
命令缓冲区是低级图形 API 的核心。DirectX®12 (DX12) 和 Vulkan® 中花费的 CPU 时间大部分将用于将绘制命令记录到命令缓冲区中。其中一个最大的优化是应用程序现在可以对命令缓冲区的记录进行多线程处理。
在上一代 API 中,多线程的能力受到驱动程序所能提供的能力的严重限制。
低级 API 允许命令缓冲区生成的并行化。使用这一点可以获得比高级 API 更好的 CPU 利用率。
驱动程序不会为低级 API 启动额外的线程。应用程序负责多线程。
避免使用过多小的命令缓冲区。
命令分配器不是线程安全的。
建议为每个录制命令的线程每帧配备一个命令分配器。
命令分配器的数量应大于(或等于)录制命令的线程数乘以飞行中的帧数。
命令分配器会随着从中分配的最大命令缓冲区而增长。
最小化提交到 GPU 的命令缓冲区数量。
每次提交都会产生 CPU 和 GPU 成本。
尝试将命令缓冲区批处理到单个提交中以减少开销。
理想情况下,提交应仅在同步队列或帧结束时发生。
避免使用捆绑包和辅助命令缓冲区。
它们可能会损害 GPU 性能(它们仅有利于 CPU 性能)。
每帧填充命令缓冲区即可。
如果使用,每个捆绑包/辅助命令缓冲区至少要有 10 次绘制。
| DirectX® 12 | Vulkan® |
|---|---|
|
|
所有较小的状态结构都组合成一个称为管线状态对象 (Pipeline State Object) 的单一状态。这使得驱动程序能够提前了解所有信息,以便将着色器编译成正确的程序集。这消除了在上一代 API 中,由于状态更改而导致驱动程序在绘制调用时重新编译着色器时可能发生的卡顿。这还使得状态优化更容易,因为不再需要跟踪多个小状态。
PSO 的编译可能需要很长时间。
驱动程序不会为编译生成额外的线程。
编译 PSO 是多线程处理的绝佳任务。
避免在堆栈较小的线程上或对时间敏感的代码中编译 PSO。
避免即时编译 PSO。
考虑先使用 uber-shader,然后稍后编译专门化。
同时编译使用相同着色器的管线可能会因锁争用而导致序列化。
使用管线缓存来跨多次运行重用 PSO。
尽量减少使用的 PSO 数量。
在创建 PSO 后,不再需要保留着色器代码。
在渲染时最小化管线状态更改。
管线与前一个管线越相似,更改的成本就越低。
更改绑定的 PSO 可能会回滚硬件上下文。
按管线对绘制调用进行排序。
将使用/不使用几何着色器阶段或细分阶段的管线组合在一起。
驱动程序不会执行冗余状态跟踪。
| DirectX® 12 | Vulkan® |
|---|---|
|
|
障碍物是向 API 和驱动程序传达操作之间依赖关系的方式。障碍物通过允许应用程序决定 GPU 是否可以重叠工作,从而为新的操作开辟了广阔的空间。它们也是通过添加过多障碍物来减慢渲染速度的简单方法,或者由于未正确转换资源而导致损坏。验证层通常有助于识别缺失的障碍物。
每帧最小化使用的障碍物数量。
障碍物会耗尽 GPU 的工作。
不要发出读到读障碍。第一次就将资源转换为正确的状态。
将一组障碍物批处理到一个调用中,以减少障碍物的开销。
除非需要,否则避免使用 GENERAL / COMMON 布局。
尽量减少组合的状态数量。
| DirectX® 12 |
|---|
| 在可能的情况下,仅设置非像素着色器资源或像素着色器资源状态,而不是组合它们。 |
Vulkan® 和 DirectX®12 都公开了显式管理 GPU 内存的功能。虽然这提供了许多新的优化机会,但编写高效的 GPU 内存管理器也可能很困难。因此,我们为 Vulkan® 和 DirectX®12 创建了易于使用的开源库。
创建大型内存堆,并从堆中子分配资源。
建议的堆分配大小为 256MB。
对于 VRAM 少于 1GB 的显卡,应使用较小的尺寸。
尽量保持分配是静态的。分配和释放内存成本很高。
通过混用临时资源来帮助减少内存占用。
确保在资源初始化期间发出正确的障碍物并仅使用必要的标志。
不当使用放置/稀疏资源可能导致挂起和/或视觉损坏。
确保完全初始化(Clear、Discard 或 Copy)放置的资源,以避免挂起和/或损坏。
使用 QueryVideoMemoryInfo 和 VK_EXT_memory_budget 查询当前内存预算。
建议仅使用总 VRAM 的 80%,以降低被驱逐的概率。
不要每帧调用内存查询函数。
相反,可以使用 RegisterVideoMemoryBudgetChangeNotificationEvent 函数让操作系统在预算更改时通知应用程序。
为资源的预期用途选择正确的内存类型。
平铺/稀疏资源
我们不推荐使用它们,因为它们对 GPU 和 CPU 的性能都有影响。
而是使用子分配和 Copy/Transfer 队列来整理内存。
切勿将高流量资源(例如渲染目标、深度目标、UAV/存储缓冲区、加速结构)放置在平铺/稀疏资源中。
当用户的系统启用了 ReBAR 时,整个 VRAM 都可供 CPU 访问(Vulkan:DEVICE_LOCAL + HOST_VISIBLE 内存类型,DX12:GPU_UPLOAD 堆类型)。
将其用于可以由 CPU 直接写入并由 GPU 读取的缓冲区,避免在两个缓冲区之间进行复制。
CPU 访问通过 PCIe®,但当使用良好的访问模式时,它们的性能很好 - 内存仅使用 memcpy 复制或顺序写入,从不读取。
| 相关工具 | |
|---|---|
Radeon™ Memory Visualizer (RMV) 能够检测 Radeon™ 驱动程序堆栈的各个级别,并能够了解应用程序内存分配在应用程序生命周期中任何时间点的完整状态。
|  Radeon™ Memory Visualizer (RMV) 是一个工具,可让您深入了解应用程序如何使用图形资源的内存。 |
| DirectX® 12 | Vulkan® |
|---|---|
|
|
许多硬件优化依赖于资源以特定方式使用。驱动程序使用资源创建时提供的数据来确定可以启用哪些优化。因此,仔细处理资源创建以获得尽可能多的优化至关重要。
仅设置所需的资源使用标志。
避免将 STORAGE / UAV 用途与渲染目标一起使用。
这可以防止在 GCN 3 之前的旧代 AMD GPU 上压缩颜色。
如果您只对节省内存感兴趣,请用单独的资源别名化相同的内存分配。
在可用时使用非线性布局。
尽可能使用 4x MSAA 或更低。
上传图像时,使用缓冲区到图像以及图像到缓冲区的副本,而不是图像到图像的副本。
如果可以将资源标记为只读,请务必这样做,因为这有助于硬件为其启用压缩。
避免在渲染和深度目标上进行共享访问。
避免在渲染目标、深度目标和 UAV/存储缓冲区上使用 TYPELESS 或 MUTABLE 格式。
FLOAT、INT、NORM 等)。渲染目标的 Mipmapped 数组将无法获得压缩优化。
在 GCN 和 RDNA 上,24 位深度格式的成本与 32 位格式相同。
在 AMD 上使用 32 位格式,以获得与 24 位相同的内存成本获得更高的精度。
16 位深度不一定比 32 位深度压缩得更好。
使用反向深度(近平面为 1.0)以改善浮点值的分布。
尽量利用深度缓冲区的完整范围。
将所有值集中在范围的一小部分可能会降低深度测试性能。
通过使近 Z 值尽可能高来改善深度分布。
使用深度分区来处理近距离几何体(例如玩家手),以进一步改善此分布。
将顶点数据分成多个流。
将位置数据分配在其自己的流中可以提高仅深度通道的性能。
如果某个属性在所有通道中都不使用,请考虑将其移至新通道。
避免为每个绘制调用设置顶点流。
更新顶点流会消耗 CPU 时间。
使用顶点和实例绘制偏移量来使用流中偏移量的数据。
顶点数据也可以存储在 SBO/结构化缓冲区中,并在顶点着色器中获取,而不是使用顶点流。
如果可能,避免使用原始重启索引。
从过于稀疏的资源读取可能不利于缓存利用率。
尝试写入渲染目标中的所有颜色通道,因为部分写入会禁用压缩。
当将字段打包到 G-Buffer 中时,将高度相关的位放在高有效位 (MSB) 中,将噪声数据放在低有效位 (LSB) 中。
描述符用于着色器寻址资源。应用程序负责在创建 PSO 时提供资源布局的描述。这允许应用程序根据对最常访问的资源的了解来优化描述符的布局。
尽量减小根签名/描述符集布局的大小,以避免用户数据溢出到内存。
尽量保持在 13 DWORD 以下。
将经常更改或需要低延迟的参数放在前面。这将有助于最小化这些参数溢出的可能性。
最小化根描述符和动态缓冲区的用法。
避免将描述符的着色器阶段标志设置为 ALL。使用最少必需的标志。
最小化描述符集更新的数量。
将属于一起的资源引用在同一个集合中。
考虑使用无绑定系统来帮助减少 CPU 从绑定描述符中获得的开销。
在使用这些的多个版本时,按根签名和管线布局对绘制进行排序。
驱动程序可以将静态和不可变采样器嵌入到着色器中,从而减少内存加载。
尝试在着色器中重用采样器。与绑定多个具有相同值的采样器相比,这允许着色器编译器重用采样器描述符。
只有每帧都会更改的常量应该放在根签名或推送常量中。
避免复制描述符。
DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE 的堆。优先使用 CopyDescriptorsSimple / vkUpdateDescriptorSet 而不是 CopyDescriptors / vkUpdateDescriptorSetWithTemplate。
| DirectX® 12 | Vulkan® |
|---|---|
|
|
对图形程序员工具箱的一个重要新 addition 是能够控制 GPU 和 CPU 之间的同步。同步不再隐藏在 API 后面。命令缓冲区的提交应尽量少,因为提交需要调用内核模式以及 GPU 上的一些隐式障碍物。
已提交的工作不需要信号量/围栏在同一队列上进行同步 — 使用命令缓冲区中的障碍物。
命令缓冲区将按提交顺序执行。
跨队列同步通过提交边界的围栏或信号量完成。
最小化使用的队列同步量。
信号量和围栏有开销。
每个围栏都有 CPU 和 GPU 成本。
提交或呈现时不要让 CPU 空闲:CPU 可以继续为下一帧准备命令列表。
当将帧渲染与异步计算重叠时,从不同的队列进行呈现,以减少停顿的可能性。
| DirectX® 12 | Vulkan® |
|---|---|
|
|
AMD 硬件具有快速清除功能。与填充完整目标相比,这些清除操作快得多,这一点怎么强调都不为过。快速清除有一些要求才能充分发挥其作用。
快速清除的设计速度比普通清除快约 100 倍。
快速清除需要完全清除图像。
渲染目标快速清除需要以下颜色之一。
RGBA(0,0,0,0)
RGBA(0,0,0,1)
RGBA(1,1,1,0)
RGBA(1,1,1,1)
深度目标快速清除需要 1.f 或 0.f 的深度值(模板设置为 0)。
深度目标数组必须一次性清除所有切片才能进行快速清除。
使用 Discard / LOAD_OP_DONT_CARE 在跳过清除时打破依赖关系。
| Vulkan® |
|---|
|
GCN 和 RDNA 硬件支持通过附加队列提交计算着色器,该队列不会被固定功能硬件阻止执行。这允许在图形队列受图形管线前端的限制时,将 GPU 填满工作。
异步计算队列可用于在图形队列并行的情况下向 GPU 发出计算命令。
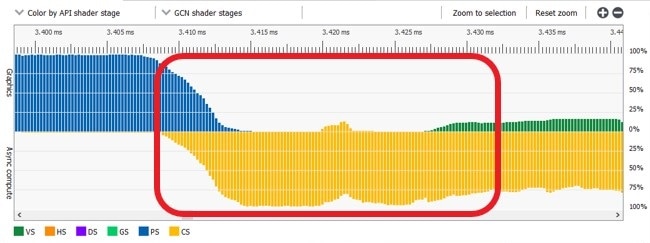
异步计算填满计算单元,而图形波形则耗尽。
使用异步计算工作来重叠前端繁重的图形工作。
常见的重叠机会包括 Z 预通道、阴影渲染和后处理。
下一帧渲染开始时可以与帧后处理重叠。
当与导出绑定着色器并行执行时,异步计算性能较差。
与较大的工作组相比,较小的工作组(64 个线程)在异步运行时通常性能更好。
在计算分派之后或之前提交的任何图形工作都可以在没有障碍物的情况下重叠。
小型分派与流水线化计算相比,作为异步计算效果更好。
大型分派后跟大型绘制是流水线化计算效果良好的另一个地方。
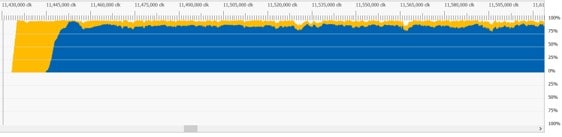
流水线化计算与像素着色器重叠
除了拥有计算队列之外,GCN 和 RDNA 还拥有专用的复制队列。这些复制队列映射到 GPU 上的特殊 DMA 引擎,这些引擎旨在最大化 PCIe 总线上的传输。Vulkan 和 DX12 通过复制/传输队列直接访问此硬件。
使用复制队列通过 PCIe 移动内存。
这比其他队列稍快。
它允许独立的图形和计算工作在不等待的情况下运行。
复制队列还可以移动 GPU 上的内存,并可用于异步整理内存。
当目标和源都在 GPU 上时,使用计算或图形队列进行复制
目标和源都在 GPU 上。
结果需要立即得到,或者队列否则空闲。
UPLOAD 和 GPU_UPLOAD 堆(DX12)/HOST_VISIBLE 和非HOST_CACHED 类型(Vulkan)中的内存是未缓存且写组合的。通过映射指针访问时要小心。
仅使用 memcpy 或顺序逐字节写入。避免随机访问。
切勿从中读取。注意意外读取,例如 pMappedPtr[i] += v。
| DirectX® 12 |
|---|
UPLOAD 内存中的资源可供着色器访问。
|
ExecuteIndirect 是 **DirectX® 12** 的一项功能,允许 GPU 生成工作负载,而无需读取回 CPU。
ExecuteIndirect 中的最快路径是避免更改任何根签名属性。
在 RDNA 之前的硬件上,对根签名的任何更改都会导致驱动程序进入缓慢路径。
RDNA 为 ExecuteIndirect 内的根签名更改添加了一条优化路径。
要获得根签名更改的最佳性能
避免通过 ExecuteIndirect 更新顶点缓冲区绑定。
避免更新任何可能已溢出到内存的根签名值。
通过 ExecuteIndirect 更新时,请保持根签名更新连续。
如果任何绘制被剔除,请务必压缩参数缓冲区并提供计数缓冲区。
避免使用圆弧函数(如 atan、acos 等)。它们可能会生成需要 100 多个周期的代码。
尽量少用超越函数(sin、cos、sqrt、log、rcp)。这些函数以四分之一速率运行。
RDNA 可以以四分之一速率并行执行超越函数。
使用 tan 时要小心,因为它会展开为 3 个超越函数:sin / cos。
使用近似值来帮助提高性能。FidelityFX CAS 包含一个快速近似函数库。
GCN 和 RDNA 通过 AGS、着色器模型 6 或 SPIR-V 子组操作支持跨波操作。
着色器内在函数可用于减少 VGPR(向量通用寄存器)压力。
FP16 可用于减少 VGPR 分配计数。
可以通过 readFirstLane 内在函数将 VGPR 标量化。
在采样单个通道时,使用 Gather4 来提高纹理获取速度。
虽然 Gather4 不会减少带宽,但它会减少到纹理单元的流量,并提高缓存命中率。
Gather4 可能会减少所需的 VGPR 数量。
GCN 以 64 个线程的组(称为 wave64)运行着色器线程。
RDNA 以 32 个线程的组(称为 wave32)运行着色器线程。
在运行着色器时,波中未使用的线程将被掩码化。
将工作组大小设为 64 的倍数,以在所有 GPU 代代上获得最佳性能。
为了最大限度地提高计算着色器中的带宽,请在每个波长以 256 字节的合并块写入图像。
经验法则是让一个 8x8 的线程组写入 8x8 像素块。
使用线程的交错布局可以提高带宽和缓存命中率。
ARmpRed8x8(),用于此目的。线程组共享内存映射到 LDS(局部数据共享)。
LDS 内存会在 RDNA 和 GCN 上进行分块。
它分布在 32 个块中。
每个块是 32 位(1 个 DWORD)。
块冲突会增加指令延迟。
优先使用数组结构或添加填充以减少访问跨距和块冲突。

Float4 数组

读取 X(8 个块冲突)

浮点数数组

读取 X(2 个块冲突)
计算着色器可以增加使用 LDS 或更好地利用线程进行优化的机会。
对全屏通道使用计算着色器。
与全屏四边形相比,这可以提高高达 2% 的性能,具体取决于硬件配置。
消除了三角形边缘创建的辅助通道的需要。
通常比全屏四边形能提高缓存命中率。
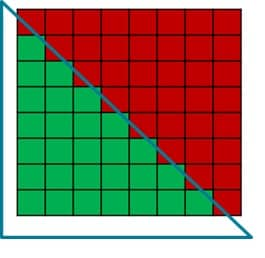
一个三角形不会用 8x8 的图块填满整个波。
在 RDNA 3 之前的硬件上,对于高度发散的工作负载,计算着色器可能比像素着色器更快,因为像素着色器可能会被其他波阻止导出。
使用几何着色器或剔除距离来剔除图元成本很高。
通过将任何顶点位置设置为 NaN,从顶点着色器中剔除图元。
在运行时间长的着色器中有其他路径时,请避免使用 discard。
discard。尽量减少像素着色器写入的总数据量,以节省内存带宽。
避免使用 RGB32 格式。
不要为每个着色的像素写入反馈。
使用随机丢弃技术来降低写入反馈资源的成本。
Vega 添加了快速打包数学 (RPM) 以实现双速率 16 位浮点数。
在 DXC 中使用标志 -enable-16bit-types 来获得真正的 16 位类型。
使用 Texture2D<float16_t4/int16_t4> 来获取 16 位样本和加载。
当像素着色受限时,使用 VRS 来减少像素着色。
使用以下功能可能会导致 VRS 填充率下降到 1x1。
深度导出。
后深度覆盖。
光栅化有序访问视图。
尽量减少每帧绑定或取消绑定 VRS 着色率图像的次数。
|  RGP 让您能够前所未有地深入了解 GPU。轻松分析图形、异步计算使用情况、事件计时、管道停滞、障碍物、瓶颈和其他性能低效问题。  Radeon™ Raytracing Analyzer (RRA) 是一个工具,可让您调查光线追踪应用程序的性能并突出显示潜在的瓶颈。  使用 Radeon™ Raytracing Analyzer (RRA) 提高光线追踪性能。 优化光线追踪管道可能很困难。了解如何使用 RRA 发现和诊断常见的 RT 陷阱,以及如何修复它们! |
| DirectX® 12 |
|---|
|
虽然调试不是优化,但仍然值得提及一些用于调试的技巧,这些技巧在优化渲染时会很有用。
调试运行时/验证层是您的朋友。
应用程序必须无警告,否则可能在某些实现或未来的硬件和驱动程序上失败。
它可能无法捕获所有未定义的行为。
缓冲区标记有助于追踪 TDR。
将标记写入用外部内存创建的缓冲区。否则,缓冲区可能会随着设备的丢失而丢失。
不要在生产版本中为每个绘制调用添加缓冲区标记。这可能会限制正在进行的任务量。
对于生产版本,请为每个通道使用一个标记。
调试标记会出现在 RenderDoc、PIX 和 RGP 等工具中。
实现一种简单的等待 GPU 完成的方法。这将有助于追踪同步问题。
| DirectX® 12 |
|---|
|