AMD FidelityFX™ Variable Shading
AMD FidelityFX Variable Shading 将可变速率着色引入您的游戏。
注意:要使 Work Graphs 中的 Mesh Nodes 功能在支持 Work Graphs with Mesh Nodes 预览功能的 Adrenalin 驱动程序上生效,需要将以下注册表项(类型为
REG_SZ)设置为:HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Control\Class\{4d36e968-e325-11ce-bfc1-08002be10318}\0000\UMD\DXC\#3226567005=1
请注意,
\0000\中的数字可能更大,具体取决于您计算机上启用了多少显卡,或者安装了多少驱动程序更新。如果您在{4d36e968-e325-11ce-bfc1-08002be10318}下有多个编号的子密钥,请确保为每个存在的子密钥将#3226567005设置为1。
要开始使用 Mesh 节点,您首先需要一个支持 Mesh 节点的 Microsoft Agility SDK 和 Microsoft DirectX® 着色器编译器。您可以在 Microsoft 自已的公告博客文章中找到两者的下载链接。
您还需要一张支持 Mesh 节点的显卡(AMD Radeon™ RX 7000 系列显卡)以及支持 Mesh 节点功能的 AMD 驱动程序,您可以在此处找到。
由于 Mesh 节点目前是一项实验性预览功能,您还需要启用 Windows 中的开发人员模式。
注意:本入门指南着重于 DirectX® 12 中 GPU Work Graphs 的新 Mesh 节点功能。如果您还不熟悉 DirectX® 12、Work Graphs 或 Mesh Shaders,建议您在继续之前先了解这些主题。
这篇博客文章描述了在HelloMeshNodes示例中使用 Mesh 节点。HelloMeshNodes示例本身结合了已有的HelloWorkGraphs示例中的 Work Graphs 部分以及 Microsoft 的D3D12 HelloTriangle示例中的窗口、交换链和主循环。
HelloMeshNodes 的 Work Graph 包含两个计算节点和两个 Mesh 节点,它们递归地计算和渲染科赫雪花分形。

在接下来的部分,我们将一步一步地介绍使用 Work Graph 中的 Mesh 节点所需的所有内容。
由于我们将 Microsoft Agility SDK 更新到了 1.715.0-preview,我们还需要更新 D3D12SDKVersion 导出。
extern "C" { __declspec(dllexport) extern const UINT D3D12SDKVersion = 715; } // or laterMesh 节点还需要实验性的状态对象功能和实验性的 Shader Model 6.9,因此在创建 ID3D12Device 之前,我们需要启用这些实验性功能。
UUID ExperimentalFeatures[2] = { D3D12ExperimentalShaderModels, D3D12StateObjectsExperiment };HRESULT hr = D3D12EnableExperimentalFeatures(_countof(ExperimentalFeatures), ExperimentalFeatures, nullptr, nullptr);Mesh 节点是 Work Graphs 1.1 功能集的一部分,一旦我们成功创建了 ID3D12Device,就需要检查它是否支持此 Work Graphs 层级。我们可以使用 D3D12_FEATURE_D3D12_OPTIONS21 来检查支持的层级是否至少为 D3D12_WORK_GRAPHS_TIER_1_1。
D3D12_FEATURE_DATA_D3D12_OPTIONS21 options = {};device->CheckFeatureSupport(D3D12_FEATURE_D3D12_OPTIONS21, &options, sizeof(options));
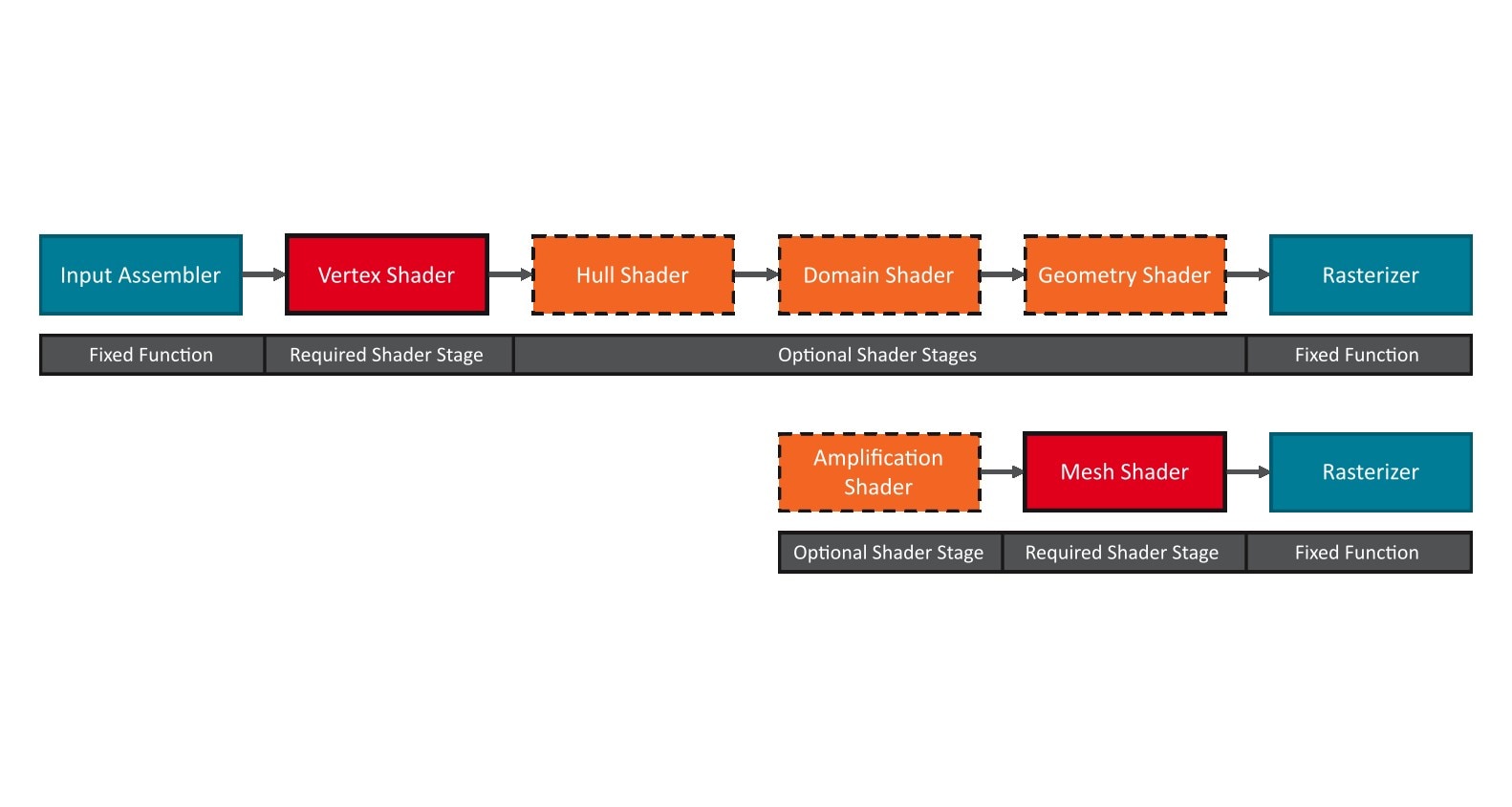
return (options.WorkGraphsTier >= D3D12_WORK_GRAPHS_TIER_1_1);与将任何计算内核转换为 Work Graph 节点的方式类似,我们也可以通过在 HLSL 代码中添加一些属性来对任何 Mesh Shader 执行相同的操作。最终的语法是已有的 Mesh Shader 属性和新的 Mesh 节点属性的混合。例如,我们将看一下以下 Mesh 节点声明:
[Shader("node")][NodeLaunch("mesh")][NodeDispatchGrid(1, 1, 1)][NodeId("LineMeshNode", 0)][NumThreads(32, 1, 1)][OutputTopology("triangle")]void LineMeshShader( uint gtid : SV_GroupThreadId, DispatchNodeInputRecord<LineRecord> inputRecord, out indices uint3 triangles[4], out primitives Primitive prims[4], out vertices Vertex verts[6])[Shader("node")]:指示此函数将在 Work Graph 中使用。[NodeLaunch("mesh")]:指示此函数将是一个 Mesh 节点。[NodeDispatchGrid(1, 1, 1)]:Mesh 节点的功能类似于广播节点,它们可以定义每次调用该节点时要启动的 Mesh Shader 线程组的固定调度网格,或使用 [NodeMaxDispatchGrid(x, y, z)] 属性定义动态调度网格的限制。SV_DispatchGrid 语义的 uint/uint2/uint3 来作为输入记录。调度网格的最大大小受到与广播节点相同的限制。[NodeId("LineMeshNode", 0)]:指定将在此 Work Graph 中引用该节点的节点 ID。节点数组索引不是必需的,如果未明确定义,将默认为 0。NodeId 属性,则将使用 Mesh Shader 函数名。或者,也可以在创建 Work Graph 时通过覆盖来设置 Mesh 节点 ID。这可用于从同一个 Mesh Shader 创建多个不同的 Mesh 节点。[NumThreads(32, 1, 1)]:定义 Mesh Shader 线程组内的线程三维网格。在此情况下,我们定义了一个 Mesh Shader,因此一个线程组中的总线程数限制为 128(请参阅 Mesh Shader 规范)。[OutputTopology("triangle")]:Mesh Shader 的强制属性,定义输出图元的拓扑(请参阅 Mesh Shader 规范)。LineMeshShader:我们 Mesh Shader 函数的导出名称。稍后我们将需要它来定义一个通用程序,并将此函数转换为完整的 Mesh Shader 流水线。除非您使用 Shader 库的导出覆盖,否则此名称在整个 Work Graph 中必须是唯一的。此外,如果未定义 [NodeId(...)] 属性,则此函数名将用作节点 ID。DispatchNodeInputRecord<LineRecord> inputRecord:与广播节点类似,这定义了 Mesh 节点输入记录,并取代了之前在 Amplification Shader 中使用的 Mesh Payload 语法。Amplification Shader 不能与 Work Graphs/Mesh Nodes 结合使用。out indices、out primitives 和 out vertices 参数没有变化。Mesh 节点不支持 Amplification Shader,但您可以轻松地将任何现有的 Amplification Shader 实现重写为广播节点以实现相同的功能。
总结来说,除了 Work Graph 特定的属性以及接收输入 Payload 的稍有不同的语法外,Mesh Shader 的工作原理保持不变。您可以在我们的 Mesh Shader 博客文章系列中找到有关 Mesh Shader 内部工作原理、编写最佳实践以及一些用例的更多信息。通过 Mesh 节点,您还可以通过本地根签名(local root signature)定义对 Mesh Shader 的资源绑定。当在同一个 Work Graph 中组合具有不同资源绑定的多个现有 Mesh Shader 时,这可能会很方便。
像素着色器可以与常规 Mesh Shader 流水线以相同的方式编写 - 或者在例如仅深度阴影通道的情况下省略。像素着色器无法访问 Mesh Shader 的输入记录,因此着色所需的数据(例如,材质 ID)必须通过顶点或图元属性进行传递。
float4 MeshNodePixelShader(in float4 color : COLOR0) : SV_TARGET{ return color;}像素着色器仍然可以与 Mesh Shader 或其他节点位于同一个文件中,但在使用 lib_6_* 目标进行编译时它们将被忽略,因此需要单独编译。
现在我们已经声明了第一个 Mesh 节点及其所有属性,我们可以从 Work Graph 中的任何计算节点向其发送记录。此外,我们还可以发送图表入口记录。将记录发送到 Mesh 节点时使用的语法与其他节点相同。在此示例中,我们有一个线程启动入口节点,它正在调用我们的 LineMeshNode 节点在屏幕上绘制一条线。
[Shader("node")][NodeLaunch("thread")]void MyComputeNode( [MaxRecords(1)] [NodeId("LineMeshNode", 0)] NodeOutput<LineRecord> meshNodeOutput) { ThreadNodeOutputRecords<LineRecord> outputRecord = meshNodeOutput.GetThreadNodeOutputRecords(1);
outputRecord.Get().start = float2(-1, 0); outputRecord.Get().end = float2( 1, 0);
outputRecord.OutputComplete();}注意:此代码仅作为调用 Mesh 节点示例。为了获得最佳性能,我们建议一次性启动更大的 Mesh 节点工作负载。您可以在最佳实践部分阅读更多关于这方面以及其他建议。
为了使我们的着色器可用,我们需要首先使用DirectX® Shader Compiler将其编译为 DirectX® 中间语言 (DXIL)。这可以在离线或运行时使用 IDxcCompiler 接口完成。在 HelloMeshNodes 示例中,着色器编译由 CompileShader 函数处理,您可以在此处找到其完整源代码。
ID3DBlob* CompileShader(const std::string& shaderCode, const wchar_t* entryPoint, const wchar_t* targetProfile);Mesh 节点和 [NodeLaunch("mesh")] 属性的支持仅在 Shader Model 6.9 及更高版本中可用,因此我们需要将着色器库编译为 lib_6_9。如前所述,使用 lib_6_9 编译着色器时,不包括像素着色器,因此我们需要使用 ps_6_9 目标再次单独编译着色器源代码,并将入口点指定为上面我们的 MeshNodePixelShader 函数。
// Contains mesh nodes (i.e., mesh shaders with node attributes) and all other compute nodesCComPtr<ID3DBlob> workGraphBlob = CompileShader(shaderSourceCode, nullptr, L"lib_6_9");// Contains pixel shader for mesh nodesCComPtr<ID3DBlob> pixelShaderBlob = CompileShader(shaderSourceCode, L"MeshNodePixelShader", L"ps_6_9");编写和编译完所有着色器代码后,我们可以开始关注创建带 Mesh 节点的 Work Graph 状态对象。
创建带 Mesh 节点的 Work Graph 状态对象在很大程度上与之前的步骤相同,我们将在此处跳过大部分步骤,只关注 Mesh 节点特有的更改。
CD3DX12_STATE_OBJECT_DESC stateObjectDesc(D3D12_STATE_OBJECT_TYPE_EXECUTABLE);我们可以使用 IncludeAllAvailableNodes() 函数或 D3D12_WORK_GRAPH_FLAG_INCLUDE_ALL_AVAILABLE_NODES 标志来启用将所有可用节点自动填充到我们的 Work Graph 中。稍后我们将看到这种自动填充与新的 Mesh 节点如何交互。
CD3DX12_WORK_GRAPH_SUBOBJECT* workGraphDesc = stateObjectDesc.CreateSubobject<CD3DX12_WORK_GRAPH_SUBOBJECT>();workGraphDesc->IncludeAllAvailableNodes();workGraphDesc->SetProgramName(ProgramName);DirectX® 12 命令列表使用两个独立的根签名(root signatures)分别跟踪计算流水线(例如 commandList->SetComputeRoot*(...))和图形流水线(例如 commandList->SetGraphicsRoot*(...))的资源绑定。直到现在,Work Graphs 只包含计算节点(即计算着色器),因此资源绑定是通过计算根签名设置的。随着 Mesh 节点的添加,Work Graph 现在也可以包含图形节点,因此在这种情况下,整个 Work Graph 必须使用*图形*根参数作为其全局根签名,而*不是*计算根参数。这通过设置 WORK_GRAPHS_USE_GRAPHICS_STATE_FOR_GLOBAL_ROOT_SIGNATURE 状态对象标志来指示。
auto configSubobject = stateObjectDesc.CreateSubobject<CD3DX12_STATE_OBJECT_CONFIG_SUBOBJECT>();configSubobject->SetFlags(D3D12_STATE_OBJECT_FLAG_WORK_GRAPHS_USE_GRAPHICS_STATE_FOR_GLOBAL_ROOT_SIGNATURE);当然,与常规 Mesh Shader 相比,Mesh 节点也可以使用本地根签名(local root signatures)以及 Work Graph 的全局根签名。通过 D3D12_SET_WORK_GRAPH_DESC 设置本地根参数(用于计算节点和 Mesh 节点)以及通过 [NodeLocalRootArgumentsTableIndex()] 将它们绑定到节点的过程保持不变。
接下来,我们可以将之前编译的两个二进制着色器 blob 添加到我们的 Work Graph 中。对于 Work Graph 库,即用 lib_6_9 编译的那个,一切都保持不变。这将把我们着色器源代码中的所有常规计算节点和 Mesh 节点添加到状态对象中。
{ CD3DX12_DXIL_LIBRARY_SUBOBJECT* libraryDesc = stateObjectDesc.CreateSubobject<CD3DX12_DXIL_LIBRARY_SUBOBJECT>(); CD3DX12_SHADER_BYTECODE libraryCode(workGraphBlob); libraryDesc->SetDXILLibrary(&libraryCode);}接下来,我们可以以相同的方式添加像素着色器库。这将把 MeshNodePixelShader 像素着色器添加到我们的状态对象中。
{ CD3DX12_DXIL_LIBRARY_SUBOBJECT* libraryDesc = stateObjectDesc.CreateSubobject<CD3DX12_DXIL_LIBRARY_SUBOBJECT>(); CD3DX12_SHADER_BYTECODE libraryCode(pixelShaderBlob); libraryDesc->SetDXILLibrary(&libraryCode);}图形流水线不仅定义了将在各个流水线阶段执行的着色器组合,还定义了额外的状态,例如渲染目标、光栅化状态或混合状态。
对于 Mesh Shader,此状态在 D3DX12_MESH_SHADER_PIPELINE_STATE_DESC 描述中设置。
对于 Mesh 节点,设置 Mesh 和像素着色器以及所有其他图形流水线状态的过程是通过**通用程序**完成的。
与定义整个流水线状态在一个结构中的图形流水线状态描述结构不同,通用程序提供了定义图形流水线的模块化方法。我们 Work Graph 中的每个通用程序都由我们状态对象描述中的 CD3DX12_GENERIC_PROGRAM_SUBOBJECT 定义,我们将通过*导出*向其添加不同的着色器,并通过一组其他*子对象*来描述流水线状态。
默认情况下,每个通用程序子对象将自动填充到我们 Work Graph 中的一个 Mesh 节点(如果设置了 D3D12_WORK_GRAPH_FLAG_INCLUDE_ALL_AVAILABLE_NODES),但我们也可以使用显式的节点覆盖从同一个通用程序创建多个 Mesh 节点。
auto genericProgramSubobject = stateObjectDesc.CreateSubobject<CD3DX12_GENERIC_PROGRAM_SUBOBJECT>();由于我们上面已经添加了 Mesh 和像素着色器的二进制着色器代码,我们可以通过它们的导出名称引用它们并将它们添加到通用程序子对象中。在这两种情况下,导出名称分别是各自着色器的函数名称。每个 Mesh 或像素着色器可以被引用多次以构建不同的 Mesh Shader 流水线。
genericProgramSubobject->AddExport(L"LineMeshShader");genericProgramSubobject->AddExport(L"MeshNodePixelShader");要定义图形流水线的其余状态,例如渲染目标、光栅化状态或混合状态,我们可以通过 genericProgramSubobject->AddSubobject(...); 向通用程序添加不同的子对象。这些状态定义子对象中的每一个也必须包含在我们 Work Graph 的状态对象描述中。
例如,我们将添加一个 CD3DX12_RENDER_TARGET_FORMATS_SUBOBJECT,并根据我们的交换链定义渲染目标格式状态。
auto renderTargetFormatSubobject = stateObjectDesc.CreateSubobject<CD3DX12_RENDER_TARGET_FORMATS_SUBOBJECT>();renderTargetFormatSubobject->SetNumRenderTargets(1);renderTargetFormatSubobject->SetRenderTargetFormat(0, DXGI_FORMAT_R8G8B8A8_UNORM);与 Mesh 和像素着色器类似,这些子对象可以添加到同一状态对象描述中的多个不同的通用程序子对象。您可以将它们视为模块化构建块,使用它们来根据您的需求组装不同的图形流水线。
其他“构建块”,例如光栅化状态、混合状态或深度-模板状态,可以以相同的方式创建和配置。您可以在此处找到通用程序中支持的子对象的完整列表。如果通用程序缺少特定流水线状态部分的子对象(或“构建块”),则会使用默认值。
一旦我们创建了通用程序的所有“构建块”,我们就可以如下添加它们:
// Add "building blocks" to define the graphics pipeline state for our mesh nodegenericProgramSubobject->AddSubobject(*rasterizerSubobject);genericProgramSubobject->AddSubobject(*depthStencilSubobject);genericProgramSubobject->AddSubobject(*depthStencilFormatSubobject);genericProgramSubobject->AddSubobject(*renderTargetFormatSubobject);...通过这些,我们成功创建了一个 Mesh 节点的通用程序。由于我们通过 workGraphDesc->IncludeAllAvailableNodes(); 设置了 D3D12_WORK_GRAPH_FLAG_INCLUDE_ALL_AVAILABLE_NODES,此通用程序将自动添加到 Work Graph 中。此节点的节点标识符由 Mesh Shader 的 [NodeId(...)] 属性定义,或者,如果未设置此属性,则由我们的 Mesh Shader 函数名定义。或者,我们也可以覆盖 Mesh 节点 ID,我们将在下一节中讨论。
如果未使用 D3D12_WORK_GRAPH_FLAG_INCLUDE_ALL_AVAILABLE_NODES,我们必须显式地将 Mesh 节点添加到 Work Graph 中。对于 Mesh 节点,这是通过 workGraphDesc->CreateProgramNode(...) 完成的,而不是用于常规计算节点的 workGraphDesc->CreateShaderNode(...)。
为了添加我们的 Mesh 节点,我们首先需要命名我们的通用程序子对象。此名称仅用于识别目的,并且必须在状态对象描述中是唯一的。
genericProgramSubobject->SetProgramName(L"TriangleMeshNodeGenericProgram");workGraphDesc->CreateProgramNode(L"TriangleMeshNodeGenericProgram");或者,我们也可以指定一个 Mesh 节点覆盖来将 Mesh 节点添加到图中。
即使使用了 D3D12_WORK_GRAPH_FLAG_INCLUDE_ALL_AVAILABLE_NODES,在创建 Work Graph 时仍然可以通过 Mesh 节点覆盖来修改和重命名 Mesh 节点。这很有用,例如,如果同一个 Mesh Shader 用于多个 Mesh 节点,因此自动填充的节点 ID(函数名或 [NodeId(...)] 属性)在图中不再是唯一的。
与通过 CreateProgramNode 显式创建的 Mesh 节点类似,我们首先需要为我们的通用程序命名。然后,我们可以在 Work Graph 描述中为该名称创建一个 Mesh 节点覆盖。通过此覆盖,我们可以设置节点 ID 和/或更改其他节点属性,例如调度网格或输入记录共享。
genericProgramSubobject->SetProgramName(L"TriangleMeshNodeGenericProgram");
auto nodeOverride = workGraphDesc->CreateMeshLaunchNodeOverrides(L"TriangleMeshNodeGenericProgram");nodeOverride->NewName({ L"TriangleMeshNode", 0 });通过 Agility SDK 版本 1.715.0-preview 和版本 1.614.1,节点覆盖与 D3D12_WORK_GRAPH_FLAG_INCLUDE_ALL_AVAILABLE_NODES 结合使用的行为略有改变。如果节点覆盖通过 nodeOverride->NewName(...) 指定了新的节点 ID,则原始自动填充的节点将从图中删除。这适用于 Mesh 节点和计算节点。
在 HelloMeshNodes 示例的情况下,TriangleMeshShader 没有 [NodeId(...)] 属性,并且 Work Graph 使用 D3D12_WORK_GRAPH_FLAG_INCLUDE_ALL_AVAILABLE_NODES 标志。使用此 Mesh Shader 定义一个通用程序将自动填充一个节点,其节点 ID 为 {L"TriangleMeshShader", 0}。由于同一个通用程序是 Mesh 节点覆盖的一部分,并且名称被覆盖,因此该节点将从图中删除,并添加具有节点 ID {L"TriangleMeshNode", 0} 的显式定义的节点。
由于 Work Graphs 能够实现 GPU 上 GPU 工作负载的完全动态调度,没有任何屏障,因此此调度工作的执行顺序不是确定的,并且可能在每次执行之间发生变化。对于 Mesh 节点,这意味着也无法保证不同 Mesh 节点及其记录的执行顺序。
在某些用例中,Mesh 节点也可以用作ExecuteIndirect++。这意味着 Mesh 节点的一个子集是 Work Graph 的入口节点,并从 CPU 或 GPU 输入接收其记录。在这种情况下,应用程序可以设置 D3D12_WORK_GRAPH_FLAG_ENTRYPOINT_GRAPHICS_NODES_RASTERIZE_IN_ORDER 标志以启用入口 Mesh 节点的确定性排序。
// Sets D3D12_WORK_GRAPH_FLAG_ENTRYPOINT_GRAPHICS_NODES_RASTERIZE_IN_ORDERworkGraphDesc->EntrypointGraphicsNodesRasterizeInOrder();这样,应用程序就可以像使用 ExecuteIndirect 一样使用 Mesh 节点 - 但支持流水线状态对象切换 - 并且它们还可以调度其他计算节点与 Mesh 节点并行调度。但是,由此计算节点产生的任何绘制都不会有任何保证的顺序。
如果您不需要为入口 Mesh 节点设置确定的光栅化顺序,我们建议不要设置此标志。省略此标志可以为入口节点调度启用某些优化。
在某些特定于供应商的 Mesh 节点实现中,计算上下文(用于常规节点)和图形上下文(用于 Mesh 节点)之间的切换可能会非常昂贵。为了最大程度地减少此类转换的数量,运行时可能会选择减少来自 Mesh 节点的背压,一次性排队更多的 Mesh 节点记录。为了准确计算这些队列所需的内存,运行时需要有关 Work Graph 的附加信息,通过新引入的 SetMaximumInputRecords 函数和 [NodeMaxInputRecordsPerGraphEntryRecord(...)] 属性。
注意:AMD GPU 不需要这些运行时提示。理想情况下,这些提示长期来说将不再需要,并在预览阶段结束后移除。尽管如此,如果您打算在其他供应商的 GPU 上运行 Mesh 节点,我们仍然建议您在此处设置准确的限制,并在技巧、技巧与最佳实践部分中概述一些确定这些值的建议。
在这里,我们将只关注 SetMaximumInputRecords 函数,因为这对于使用 Mesh 节点的 Work Graph 是必需的。可选的 [NodeMaxInputRecordsPerGraphEntryRecord(...)] 将在技巧、技巧与最佳实践部分中介绍。SetMaximumInputRecords 可通过 ID3D12WorkGraphProperties1 接口获得,该接口取代了先前用于查询后端内存大小的 ID3D12WorkGraphProperties 接口。
CComPtr<ID3D12WorkGraphProperties1> workGraphProperties;stateObject->QueryInterface(IID_PPV_ARGS(&workGraphProperties));SetMaximumInputRecords 设置了节点输入的最多数量的限制,即在使用 D3D12_DISPATCH_MODE_MULTI_NODE_CPU_INPUT 作为图表调度模式时将调用多少(不同的)节点,以及将传递到图表的最大记录数量(所有节点总计)。必须在调用 workGraphProperties->GetWorkGraphMemoryRequirements(...) 之前调用此函数。在 HelloMeshNodes 示例中,我们只有一个入口节点,只有一个记录。
const auto workGraphIndex = workGraphProperties->GetWorkGraphIndex(ProgramName);workGraphProperties->SetMaximumInputRecords(workGraphIndex, /* MaxRecords */ 1, /* MaxNodeInputs */ 1);由于此函数仅影响后端内存,而不影响实际编译的图,因此我们可以在运行时更新这些限制,例如,如果需要更多输入记录。更改这些限制将需要查询后端内存大小并重新分配后端内存。后端内存的更改还需要使用 D3D12_SET_WORK_GRAPH_FLAG_INITIALIZE 标志重新初始化后端内存。
我们已跳过工作图状态对象的实际创建、后端内存的分配以及 D3D12_SET_WORK_GRAPH_DESC 描述的准备,因为这些步骤(除了新添加的 SetMaximumInputRecords 函数之外)保持不变,但有关详细信息,请参阅 此处。
但在调用 commandList->SetProgram(...) 之前,我们需要先设置根签名并可能绑定我们的工作图可能使用的任何资源。由于我们在工作图中使用网格节点,因此在创建状态对象时,我们必须设置 D3D12_STATE_OBJECT_FLAG_WORK_GRAPHS_USE_GRAPHICS_STATE_FOR_GLOBAL_ROOT_SIGNATURE 标志。
configSubobject->SetFlags(D3D12_STATE_OBJECT_FLAG_WORK_GRAPHS_USE_GRAPHICS_STATE_FOR_GLOBAL_ROOT_SIGNATURE);这意味着我们现在需要为工作图使用图形根签名。对于后续的资源绑定,我们也需要使用 commandList->SetGraphicsRoot...(...) 函数,而不是用于没有网格节点的工作图的 commandList->SetComputeRoot...(...) 函数。
commandList->SetGraphicsRootSignature(globalRootSignature);由于我们现在也直接从工作图进行渲染,因此我们还需要设置网格节点要写入的渲染目标。此渲染目标对所有网格节点都相同,但在某些用例中,您可能可以使用 渲染目标数组 将不同网格节点的输出分离到不同的纹理中。
commandList->OMSetRenderTargets(1, &rtvHandle, false, &dsvHandle);除此之外,分派工作图本身也保持不变。在 HelloMeshNodes 示例 的情况下,我们只有一个入口节点,我们仅用一个空记录调用一次。
// Dispatch work graphD3D12_DISPATCH_GRAPH_DESC dispatchGraphDesc = {};dispatchGraphDesc.Mode = D3D12_DISPATCH_MODE_NODE_CPU_INPUT;dispatchGraphDesc.NodeCPUInput = { };dispatchGraphDesc.NodeCPUInput.EntrypointIndex = 0;// Launch graph with one recorddispatchGraphDesc.NodeCPUInput.NumRecords = 1;// Record does not contain any datadispatchGraphDesc.NodeCPUInput.RecordStrideInBytes = 0;dispatchGraphDesc.NodeCPUInput.pRecords = nullptr;
commandList->SetProgram(&setProgramDesc);commandList->DispatchGraph(&dispatchGraphDesc);现在我们已经介绍了如何将网格节点添加到现有工作图以及如何调用此类工作图,我们可以更仔细地研究 HelloMeshNodes 的工作原理以及它如何使用网格节点绘制科赫雪花分形。
科赫雪花分形,或科赫曲线,是一种分形曲线,它递归地分割和变换等边三角形的边。在 HelloMeshNodes 示例中,我们不仅计算和绘制了科赫曲线(即分形的外部线),还用三角形填充了曲线所包围的区域。

因此,科赫雪花工作图总共包含四个节点:两个计算节点和两个网格节点。您可以访问 GitHub 上的链接以查看完整的源代码。
EntryNode:此节点从 CPU 调用,并初始化科赫雪花,如右侧所示,只有一个三角形。此三角形由一个指向 TriangleMeshNode 的输出以及三个指向 SnowflakeNode 的输出组成,每个输出对应三角形的一条边。SnowflakeNode:通过将线段分成四个新的线段来递归处理线段。使用 TriangleMeshNode 填充这些新线段所包围的科赫雪花区域。如果达到递归限制,则使用 LineMeshNode 在屏幕上绘制线段。下面表格显示了 SnowflakeNode 的不同输出。| 雪花输入 | 雪花递归输出 | 雪花尾部输出 |
|---|---|---|
 |  |  |
LineMeshNode:在输入记录中接收开始和结束位置,并在它们之间绘制一条线。由于科赫分形中的线不呈直角相交,因此网格着色器将线的端点绘制为等边三角形。此网格节点总共导出六个顶点和四个三角形。TriangleMeshNode:在输入记录中接收三个顶点位置,并用它们绘制一个三角形。完整的图结构可以在下图看到。尽管此处未显示,但两个网格节点的两个图形管线使用相同的像素着色器,该着色器用颜色填充渲染的三角形,颜色在网格着色器中设置,并通过每图元属性传递。

由于网格节点不保证任何绘制顺序,我们使用深度缓冲区来始终将外部分形线绘制在内部三角形的前面。