引言
本系列博客将带领读者分析实际项目中遇到的问题,从而帮助他们更好地理解程序的CPU性能优化。我们希望本系列对您的项目有所帮助。
第一章 - 问题描述
在我参与的一个项目中,我遇到了一项非常简单的任务:如何更快地得到三个变量中的最大值?这类简单的数值运算在图形学和科学计算中都很常见。例如,在C++中,有三种方法可以完成这项任务。哪种更快?
#define max(a,b) (((a) > (b)) ? (a) : (b))const T& std::max( const T& a, const T& b )T std::max( std::initializer_list<T> ilist )
答案未知,取决于数据和CPU。因此,首先需要约束测试场景。
1.1 数据类型
编译器会为不同的数据类型生成不同的汇编指令。例如,整数和浮点数的指令差异很大。由于任务源于图形编程,数据类型为32位float类型。
1.2 编译器
编译器开发者在优化编译生成的代码时非常用心。不同厂商的编译器生成结果可能不同,因此有必要识别所使用的编译器。鉴于Windows 10的流行度和易用性,我选择Visual Studio 2022作为此示例的开发环境,版本号为“17.8.6”。编译器版本号为“19.38.33135”。编译类型为“x64 RelWithDebInfo”。操作系统版本号为“10.0.19045.3930”。
1.3 CPU和性能分析器
最后但同样重要的是,我们需要识别CPU,因为架构在不断更新,不同的CPU在执行相同的汇编指令时可能表现不同。并且由于硬件依赖性很强,CPU决定了可用的性能分析器。我使用的CPU是AMD 7900X3D,因此我使用的性能分析器是AMD μProf,版本号为“4.1.396”。
第二章 - 基准测试
一旦约束完成,我们就可以开始构建基准测试,它需要满足以下条件:
- 将其约束为微基准测试,使用最少的代码以最大程度地减少干扰并简化测试。
- 准备足够的数据以确保准确的性能汇总。
- 数据应该是随机的但一致的,以模拟真实场景。
2.1 数据准备
C++ 11的随机数生成可以满足我们的需求。1000万个32位浮点数足以确保获得准确的性能数据。别忘了固定随机种子以确保生成相同的数据序列。
using T = float;
std::default_random_engine eng(200);std::uniform_real_distribution<T> distr;
std::vector<T> buf(10000000);for (auto& i : buf) { i = distr(eng);}2.2 测试函数
函数测试相对简单。我们需要做的是遍历整个随机数组,然后使用不同的方法一次性获取3个数字中的最大值。然后我们对该过程进行计时。添加noinline是一个可行的选项,可以防止编译器展开函数,并方便调试。
template <typename T, int P>__declspec(noinline) T test(const std::vector<T>& vec) { T result = 0;
auto start = std::chrono::steady_clock::now(); for (auto i = std::cbegin(vec) + 2, end = vec.cend(); i != end; i = std::next(i)) { if (P == 1) { result = max(*(i - 2), max(*(i - 1), *i)); } else if (P == 2) { result = (std::max)(*(i - 2), (std::max)(*(i - 1), *i)); } else { result = (std::max)({ *(i - 2), *(i - 1), *i }); } } const auto end = std::chrono::steady_clock::now(); std::cout << "Slow calculations took " << std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() << " microseconds" << std::endl;
return result;}2.3 性能数据
我们的下一步是性能测试。请记住,要运行测试几次,然后平均数据。很明显,std::max(a, b)最快,而max宏最慢,std::max(ilist)则介于两者之间。

第三章 - 性能分析
接下来是分析问题的阶段,关键在于汇编代码和性能分析器中的PMC计数器。
3.1 汇编分析
首先,让我们看一下std::max(a, b)的汇编代码。基本没问题。所有分支操作都通过“cmov”系列指令完成,可以有效避免分支预测失败。

接下来,让我们检查max宏的汇编代码。我们可以看到编译器生成了几条条件跳转指令。由于输入数据的随机性,CPU的分支预测模块可能无法正确预测分支,从而导致分支预测失败。
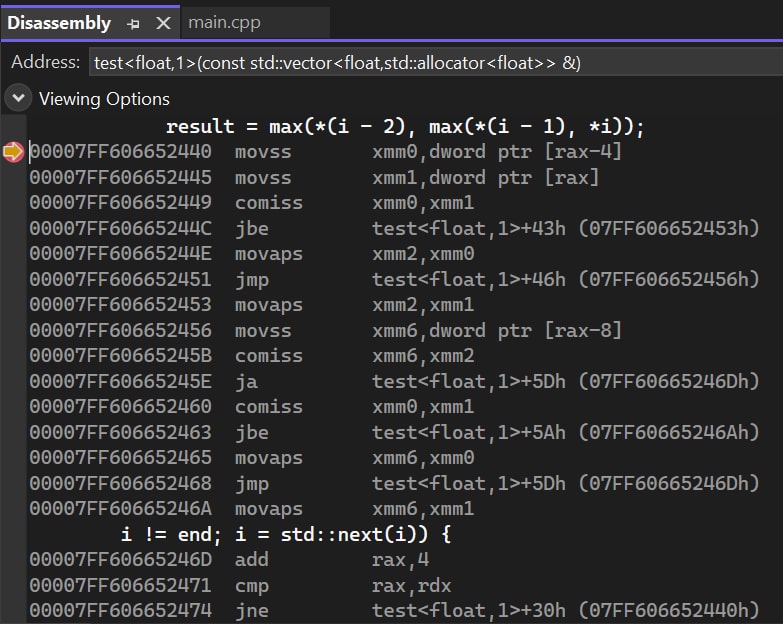
最后是std::max(ilist)的汇编代码。可以发现一些额外的数据复制操作和一个内部循环。更多的操作意味着速度可能更慢。但是,代码本身没问题。

事情似乎明朗了。唯一需要进一步分析的问题是max宏。我们需要弄清楚减速是由于分支预测失败还是其他原因。
3.2 PMC分析
下一步是使用性能分析器分析PMC,并将选项设置为Assess Performance (Extended)。运行后,切换到ANALYZE页面,然后切换到Branch视图以查看与分支相关的数据。分支指令的数量是RETIRED_BR_INST,分支误预测的数量是RETIRED_BR_INST_MISP。PTI后缀表示数据的每个单元都按千条指令计算。这些名称在不同版本的性能分析器中可能有所不同。一切都以PPR中描述的PMC为基础。
很明显,“test”函数每千条指令有321.26条分支指令和34.48条分支误预测指令,分支误预测率为10.73%。这个总体误预测率已经很高了,而单条指令的误预测率可能还会更高。
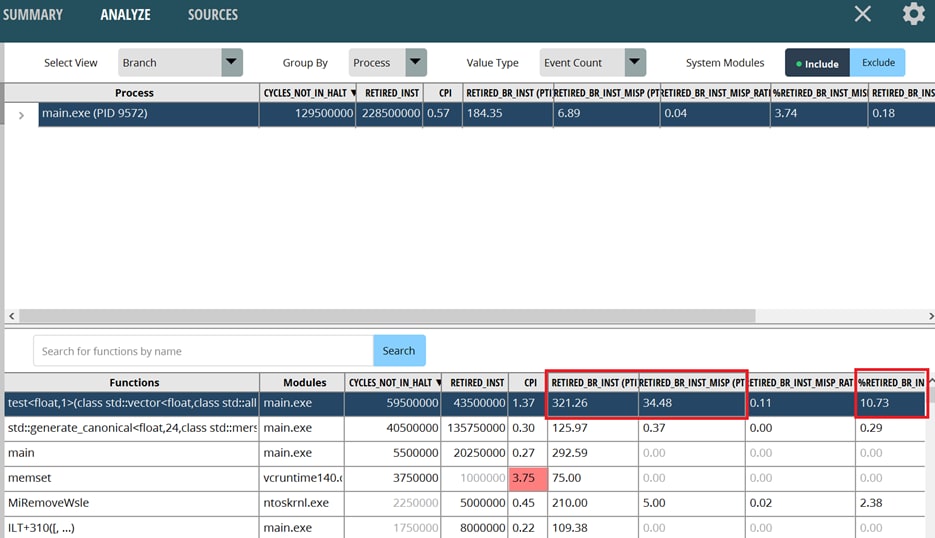
双击“test”函数打开SOURCES页面,您可以发现分支预测失败主要发生在max宏中的跳转指令附近。由于函数内的循环也使用分支指令,并且分支预测失败的概率较低,因此宏的总体分支误预测率(11.2%)会更高。单条指令的最高误预测率为33%,这将显著降低吞吐量。但值得庆幸的是,在随机输入的情况下,总体分支预测命中率仍可达到近90%。这证明了现代CPU分支预测模块的有效性。

3.3 结论
问题显然不在于宏,而在于三元运算符。如果您直接将宏替换为三元运算符,结果仍然相似。Visual Studio 2022在编译多级三元运算符时可能会生成条件跳转指令,从而增加分支预测失败的可能性。
由于CPU的多级流水线设计,分支预测失败会导致流水线被刷新和重新加载,从而损失数百个时钟周期,增加条件指令的延迟。因此,有必要尽可能避免分支预测失败。对于普通的算术程序,编译器可以生成“cmov”系列指令来避免这个问题。
当然,这并不是终点。由于不同CPU上分支预测模块的架构不同,分支预测命中率可能会有很大差异。流水线的长度也可能不同,导致CPU的时钟损失不同,这需要进行现场测试。
不同的输入组合会导致不同的结果吗?例如:将输入类型更改为int整数;取两个数字中的最大值而不是三个;使用有序输入数据;使用if else运算符,等等。您可以将此类排列组合作为课后练习进行分析。
根据我的测试,在随机输入的情况下,当取两个整数的最大值时,三元运算符的速度与std::max(a, b)相似。
第四章 - 结语
本博客以分支预测为例,展示了如何分析汇编和PMC,并最终解决任务。但请记住,分支预测是一个非常复杂且困难的主题。在本博客中使用此示例的主要原因之一是它足够简洁,并且源于实际项目。我们在其他项目中很可能会遇到更复杂的分支预测问题,这需要更深入的分析和更复杂的解决方案。
现在,一个完整的性能分析优化过程已经完成。您可以看到编译器背后的一些细微差别。具有相同逻辑的代码可能生成完全不同的指令,而这些不同指令的性能可能差异很大。软件优化的任务是找到最佳解决方案。
祝您工作顺利!