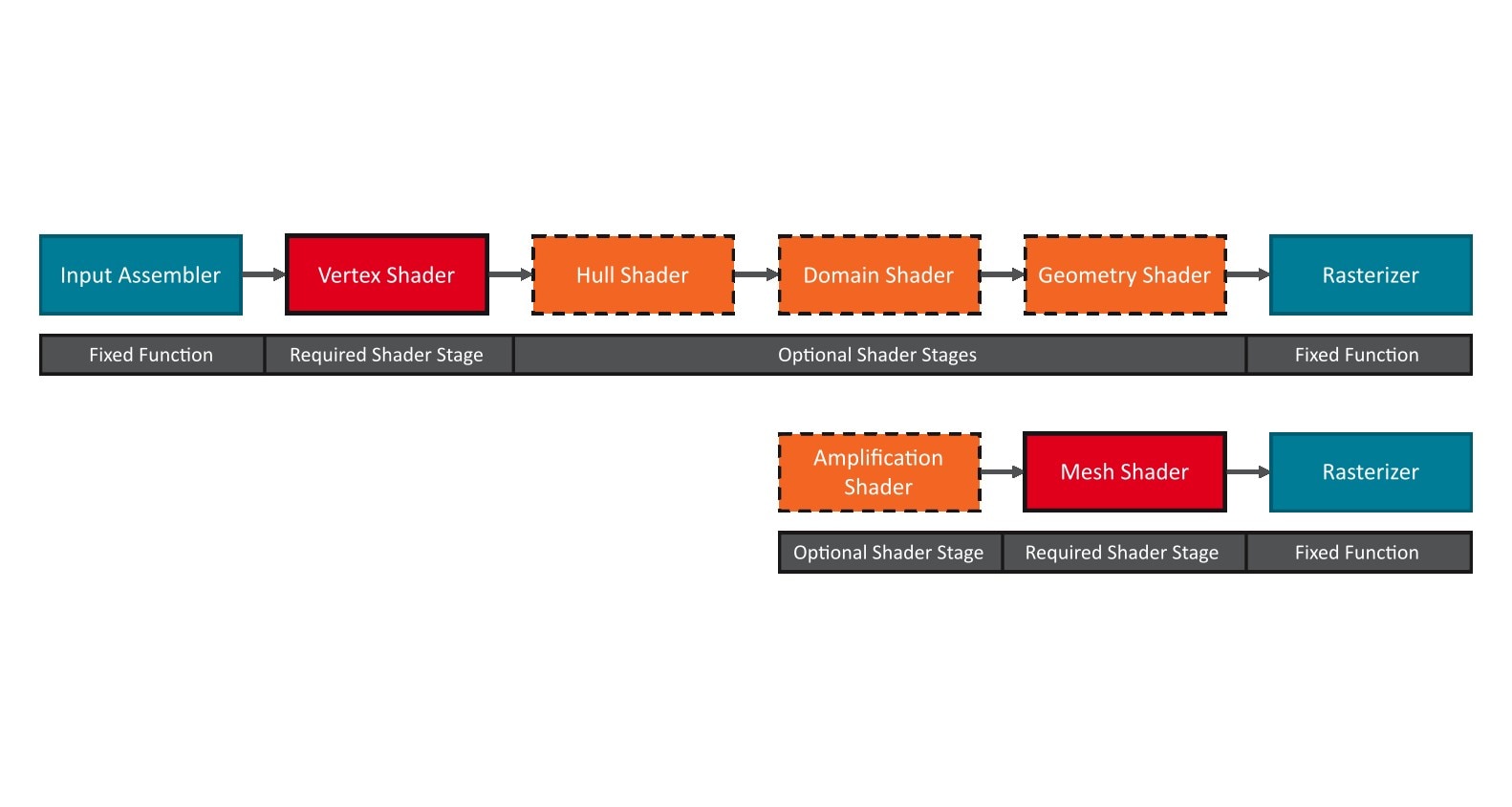
引言
您好!我们默认您已阅读《CPU 性能优化指南序言》,并对 CPU 性能优化的基本概念有所了解。本章作为系列的一部分,是对《CPU 性能优化指南 III》的延续,旨在帮助您更好地理解如何使用汇编优化代码,希望能为您的项目带来一些帮助。
关键词:汇编。
第一章 - 问题描述
项目开发中可能遇到的一个挑战是,高级语言编译器生成的指令是否最优。如果编译器生成的指令性能不佳,是否有其他方法可以生成更好的指令?
1.1. 指令选择
首先,大多数现代 CPU 都包含几种指令集,例如 x86、x64、SSE 和 AVX 指令集。在这里,我们选择最常见的 x64 指令集。目标是仅使用 x64 指令集编写汇编代码,看看它是否能比编译器生成的指令运行得更快。
1.2. 编译器
接下来是编译器。由于 Microsoft® Windows® 10 的普及和易用性,我们选择 Microsoft® Visual Studio® 2022 作为开发环境,版本为 17.9.2。编译器版本为 19.39.33521。编译器类型为 *x64 RelWithDebInfo*。操作系统版本为 10.0.19045.4046。我们使用的汇编编译器是 Visual Studio 的 MASM。
1.3. CPU
最后,需要识别 CPU,因为架构在不断更新。每条指令的延迟因 CPU 而异。这里使用的 CPU 是 AMD Ryzen™ 9 7900X3D。
第二章 分析与优化
由于之前已经进行了性能测试,这次我们将直接进入分析阶段,重点关注编译器生成的汇编代码。
2.1. 偏移 TB040
首先来看编译器生成的偏移 TB040 的汇编代码。对于这样一个简单的函数,编译器表现出色,几乎所有代码都在寄存器上运行,确保了最低的指令延迟和最高的吞吐量。然而,汇编代码仍然存在一些冗余。这主要体现在计算 g 时,在 while 循环中生成了过多的寄存器赋值操作。
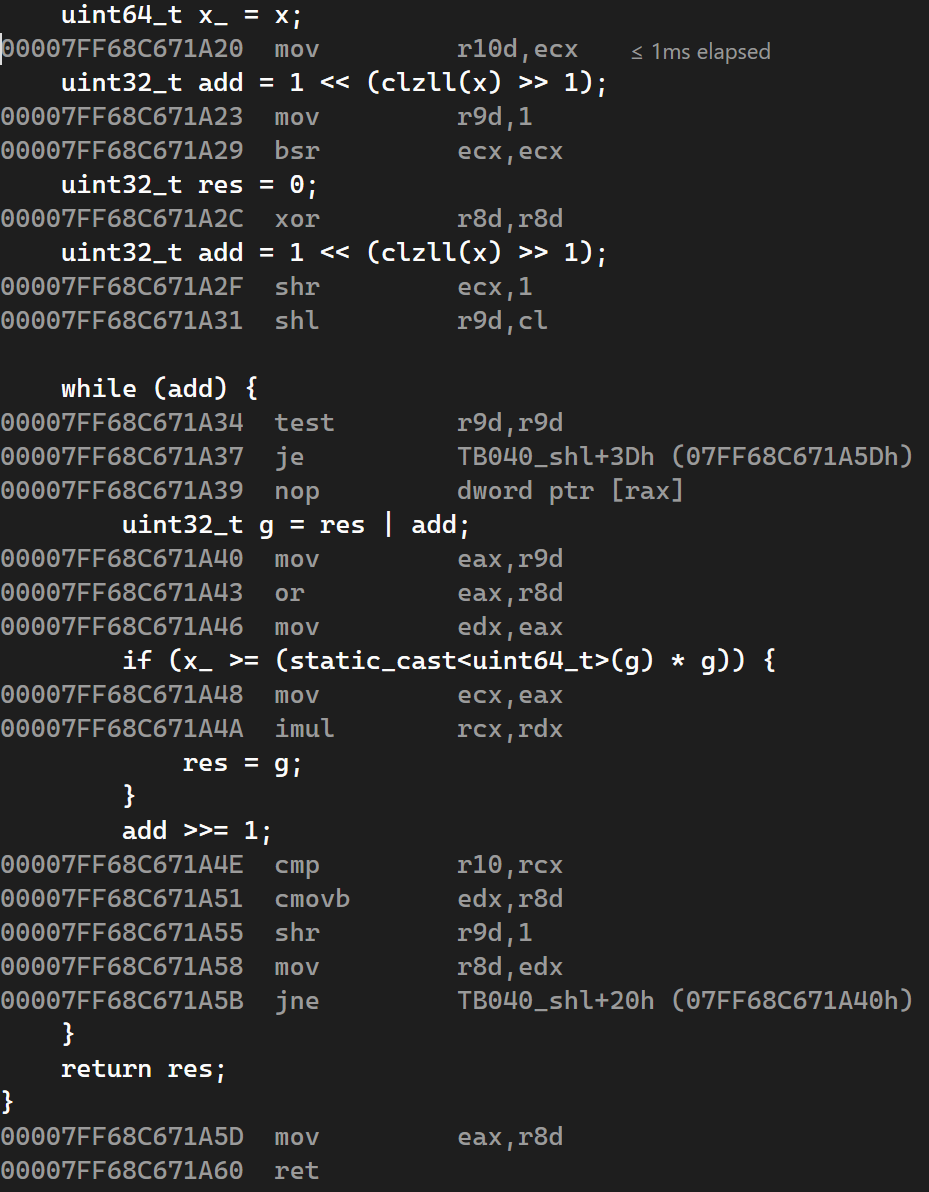
图 1:偏移 TB040 汇编代码
2.2. 编译器与汇编
对于如此简单的 C++ 代码,编译器的性能已经足够理想。要让编译器生成更好的汇编代码非常困难。原因在于编译器本身需要考虑兼容性,生成的汇编代码需要在所有代码逻辑中都保证良好的性能。如果某个方案在某些逻辑中表现不佳,编译器会选择一个平均性能更好的替代方案。在这种情况下,如果您想为了获得最佳性能而放弃一些兼容性,手动编写汇编是最佳选择。
手动编写汇编需要满足以下要求:
- 首先,您需要熟悉 CPU 的各种寄存器和内存操作。
- 其次,您需要了解编译器和汇编之间的函数调用规范、参数传递和栈平衡。
- 最后,您需要了解汇编指令在不同 CPU 上的性能表现。由于这里使用的是 Visual Studio 和 MASM x64 汇编编译器,您需要阅读以下文档来满足上述要求。
- x64 架构 描述了 x64 CPU 架构中的寄存器及其含义。简而言之,函数可以安全修改的寄存器是 `rax`、`rcx`、`rdx` 和 `r8` - `r11`。
- x64 架构 还描述了 x64 架构的函数调用规范、参数传递和栈平衡。简单来说,`rcx`、`rdx`、`r8` 和 `r9` 寄存器以及栈可以作为函数的参数传递,而 `rax` 可以作为整数值返回。
- 每个 CPU 供应商都提供了其 CPU 型号支持的指令集及其指令延迟。例如,对于 AMD 平台,您可以访问 https://www.amd.com/ 搜索并下载《软件优化指南》。以《AMD Zen4 微架构软件优化指南》为例,该文档包含了 *Zen4* 架构 CPU 的所有指令及相关性能参数。
2.3. 汇编 TB040
既然所有条件都已满足,下一步就是编写汇编代码。总体目标是简化 while 循环内的汇编指令,使用更少的寄存器完成相同的工作。同时,别忘了将函数和跳转入口地址对齐到 16 字节,以确保 CPU 能够快速访问地址。
1. _TEXT$21 segment para 'CODE'2.3. align 164. public TB040_shl_asm5. TB040_shl_asm proc frame6.7. ; r9d: add, r8d: res, r10d: x8.9. mov r10d,ecx10. mov r9d,111. bsr ecx,ecx12. xor r8d,r8d13. shr ecx,114. shl r9d,cl15. test r9d,r9d16. je TB040_shl_end17.18. align 1619. TB040_shl_loop:20. mov ecx,r9d21. or ecx,r8d22. mov eax,ecx23. imul rax,rcx24. cmp r10,rax25. cmovae r8d,ecx26. shr r9d,127. mov eax,r8d28. jne TB040_shl_loop29.30. align 1631. TB040_shl_end:32. ret33.34. .endprolog35.36. TB040_shl_asm endp37.38. _TEXT$21 ends39.40. end第三章 基准测试
代码完成后,我们就可以开始构建符合以下标准的基准测试了:
- 微基准测试。尽可能精简测试代码。
- 确保数据具有足够大的量级,以保证准确的性能数据。
- 有效验证,以确保算法的正确性。
3.1. 数据准备
本次的目标与《第 III 部分》一致。因此,数据集仍然是 `uint32_t` 可以覆盖的所有无符号整数范围,这个数据量级足以保证性能数据的准确性。
同时,需要验证算法。每个整数都将与 `std::sqrt` 的结果进行比较,以确保算法本身的正确性。
3.2. 测试函数
参考样本是《第 III 部分》中提到的偏移 TB040。测试函数是仅使用汇编指令编写的偏移 TB040。新函数称为汇编 TB040。
3.3. 性能数据
最后,需要运行性能测试几次,对数据进行平均,以防止数据跳变。可以看到,汇编 TB040 比偏移 TB040 略快约 5%,对于如此简单的纯寄存器操作代码来说,这是一个非常不错的结果。
 表 1
表 1
尽管数字看起来不错,但考虑到编写汇编代码的难度和较低的兼容性,在开发项目中,您仍然需要权衡性能提升与实际资源成本。
细心的读者可能会发现,while 循环的开头有一个跳转指令,用于判断 add 是否为 0,但该指令不会被触发。原因是实现逻辑存在缺陷。更准确的逻辑是 do-while,它比 while 稍快一些。这种细微的错误也更容易从汇编的角度被发现。然而,do-while 比基于 while 优化的汇编要慢。如果您感兴趣,也可以尝试使用汇编指令优化 do-while 逻辑。
第四章 结语
本文以偏移 TB040 为例,介绍了通过编写汇编代码优化程序的可能性。这样读者就能明白,即使高级语言编译器已经非常发达,保留汇编编译器仍然是必要的。如果您对此感兴趣,可以参考 glibc 或 Visual C++ 的源代码。像 memcpy 和 memset 这样的底层函数,它们是使用汇编指令在不同 CPU 指令集上单独实现的,以确保最佳性能。
现在读者应该清楚,汇编指令的优化可以分为两个方向:
- 修改高级语言逻辑,以确保编译器生成更好的汇编代码。
- 直接使用汇编编写程序。
您可以根据实际需求选择自己的解决方案。注意,直接使用汇编仍有两种选择方向:
- 使用汇编编译器编写静态汇编代码。
- 根据运行时环境动态生成汇编代码,也称为即时编译 (JIT) 技术。
汇编编译器在大多数情况下已足够,但 JIT 在当今的基础软件中也随处可见,例如虚拟机或模拟器。甚至一些深度学习框架的运算符也是通过 JIT 实现的。JIT 有潜力在所有硬件上实现最佳性能,但生成 JIT 代码需要时间,这需要平衡汇编代码生成时间和实际运行时间。
读完本文,读者应该能够理解不同框架和系统为实现性能所做的各种努力。我衷心希望您的程序能够达到最佳性能。最后,祝您工作顺利。