引言
我们默认您已经阅读了《CPU 性能优化指南》的序言,并对 CPU 性能优化的基本概念有了大致的了解。本系列文章的第三部分将再次介绍一个在实际项目中遇到的问题,以使您更深入地理解良好的算法如何影响 CPU,并希望能为您自己的项目带来一些帮助。关键词:CPU 时钟;指令数;算法。
第一章 - 问题描述
项目开发中可能遇到的一个挑战是如何在指令数有限的情况下完成特定功能(例如,在浮点硬件功能受限的单片机上使用整数指令模拟浮点运算)。或者我们只是想减少指令数,以期减少执行时间,从而获得更高的吞吐量。
1.1. 指令选择
首先,CPU 中每条指令的延迟是不同的。我们这次选择最常见的整数指令,目标是仅使用整数指令来获得最接近整数的平方根。
1.2. 编译器
然后是编译器。由于 Microsoft® Windows® 10 的普及和易用性,我们选择 Microsoft® Visual Studio® 2022 作为开发环境,使用的版本是 17.9.2。编译器版本是 19.39.33521。编译器类型是x64 RelWithDebInfo。操作系统版本是 10.0.19045.4046。
1.3. CPU 和性能分析器
最后,需要识别 CPU,因为架构在不断更新。每条指令的延迟因 CPU 而异。而且由于其对硬件的高度依赖性,CPU 决定了可以使用哪个性能分析器。这里使用的 CPU 是 AMD 7900X3D,因此这里使用的性能分析器是 AMD μProf,版本为 4.2.845。
第 2 章 - 基准测试
现在我们已经准备就绪,是时候构建基准测试了。基准测试需要满足以下条件:
- 微基准测试。尽可能精简测试代码。
- 确保数据具有足够大的量级,以保证准确的性能数据。
- 有效验证以确保算法的正确性。
2.1. 数据准备
由于这次的目标相对简单,我们的数据集是 `uint32_t` 可以覆盖的所有无符号整数范围,其数量足以保证性能数据的准确性。
算法需要得到验证。每个整数都会与 `std::sqrt` 的结果进行比较,以确保算法的正确性。
2.2. 测试函数
测试函数是这篇博客的重点。当涉及到仅使用整数指令获得最接近整数的平方根的挑战时,我见过的最简单、最快的設計是 Microchip 的 TB040。它利用了整数的位运算,使得算法的计算量趋于线性。以下是一个简单的实现。关于它具体是如何工作的,您可以参考它本身。
1. uint32_t TB040(uint32_t x) {2. uint64_t x_ = x;3. uint32_t res = 0;4. uint32_t add = 0x80000000;5.6. while (add) {7. uint32_t g = res | add;8. if (x_ >= (static_cast<uint64_t>(g) * g)) {9. res = g;10. }11. add >>= 1;12. }13. return res;14. }TB040 已经相当不错了,尤其是在硬件受限的单片机上。但它仍有改进的空间。当算法本身已经足够好的时候,减少它的工作量是一个很好的优化方向。在具有良好位运算支持的硬件上,TB040 中的加法变量可能不需要初始化为固定值,而是可以根据 x 的最高有效位的位位置来设置。由于平方根的性质,加法的初始位可以设置为 x 的最高有效位索引的一半,以减少计算量。
15. inline unsigned long clzll(uint32_t v) {16. unsigned long lz = 0;17. _BitScanReverse(&lz, v);18. return lz;19. }20.21. uint32_t add = 1 << (clzll(x) >> 1);这里我们使用 bsr 指令来获取最高有效位。像 C++20 中的 lzcnt 和 std::bit_width() 等指令具有类似的功能,但我们将其留给读者自行探索。
2.3. 性能数据
性能测试需要运行几次并平均数据,以防止数据波动。很明显,优化的 TB040 比原始 TB040 运行得更快。数据符合预期,因为偏移量将计算量至少减少了一半,这使得算法能够实现更高的吞吐量。

表 1
第 3 章 - 性能分析
下一阶段是对性能进行分析,重点关注性能分析器中的 PMC。
3.1. 分析 PMC
使用性能分析器分析 PMC,选项集为“评估性能(扩展)”。运行后,切换到“ANALYZE”页面,然后切换到“IPC”视图来检查指令和 PMC。正在运行的 CPU 时钟是“CYCLES_NOT_IN_HALT”,指令数是“RETIRED_INST”。将“RETIRED_INST”除以“CYCLES_NOT_IN_HALT”得到 IPC,即每单位时间运行的指令数。IPC 越高越好。反向计算得到 CPI,即单条指令消耗的 CPU 时钟。CPI 越低越好。这些名称在不同版本的性能分析器中可能会有所不同。它取决于 PPR 中相应的硬件 PMC。
3.2. TB040
让我们从原始 TB040 的数据开始。IPC 表现良好,问题很少。让我们记住 CPU 时钟和指令数。

图 1:原始 TB040
3.3. 偏移的 TB040
让我们看一下偏移的 TB040 的数据。IPC 表现更好,CPU 时钟比原始 TB040 少一半,指令数也少一半。显然,如果我们想优化一个已经足够令人满意的算法,一个可行的方法是最小化指令数和 CPU 时钟。
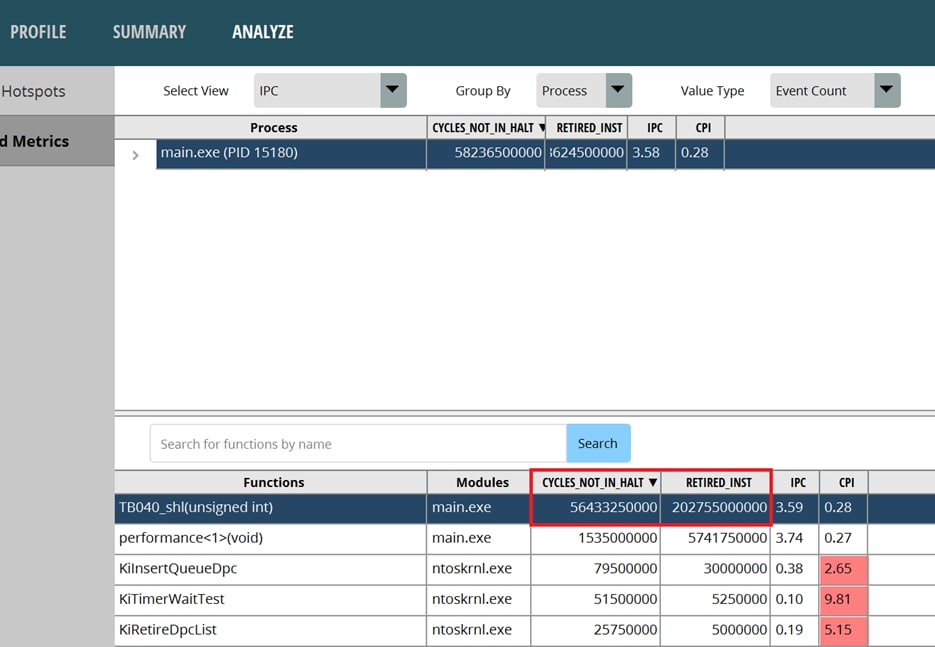
图 2:偏移的 TB404
第 4 章 - 结论
以 TB040 为例,这篇博客介绍了如何分析 PMC 并提供了一种优化指令数的方法。然而,优化指令数是一个复杂的话题。这篇博客中提出的例子只是更常见的一种。
当然,TB040 还有其他实现。但底层机制大多是相似的。您可以参考 GeeksforGeeks 或 foobaz 中提到的 JensGrabner 的实现来进行自己的性能分析。您还可以尝试扩展 TB040 以支持 uint64_t,看看还有哪些痛点。
现在,我们已经完成了分析 CPU 指令数的整个过程。可以发现,由于计算量的不同,CPU 指令数和时钟周期的差异巨大。确保您的程序能够以尽可能少的 CPU 指令和时钟周期来完成其功能,这也是软件优化工作的一部分。
最后,祝您工作顺利。