引言
在阅读了《CPU性能优化指南 - 前言》和《第一部分》之后,我相信您已经对CPU性能优化的基本概念有了一定的了解。本系列文章的第二部分将介绍一个在实际项目中遇到的问题,以帮助读者更深入地理解CPU性能优化,希望本系列文章能对您的项目有所帮助。
第一章 - 问题描述
我们在项目开发中经常遇到的一个非常实际的问题是:如何发现和解决缓存失效?内存操作在程序中分布广泛。缓存和内存的读写速度相差几十甚至上百倍,因此,尽可能确保程序从缓存中获取数据而不是内存,可以极大地提高性能。
1.1. 数据结构
首先,不同的数据结构会导致完全不同的缓存行为,因此我们需要确定数据结构。在这里,我们选择“结构体数组”(struct of arrays)和“结构体指针数组”(array of pointers to struct)。
1.2. 编译器
然后是编译器。鉴于Windows 10的普及度和易用性,我们选择Visual Studio 2022作为开发环境,版本为17.8.6。编译器版本为19.38.33135。编译器类型为x64 RelWithDebInfo。操作系统版本为10.0.19045.3930。
1.3. CPU 和性能分析器
最后,需要确定CPU,因为CPU架构不断更新,不同CPU的缓存容量和策略也完全不同。硬件依赖性很强,CPU决定了可以使用哪种性能分析器。本例中使用的CPU是AMD 7900X3D,因此我使用的性能分析器是AMD μProf,版本号为4.2.845。
第二章 - 基准测试
现在我们已经准备就绪,是时候构建基准测试了。基准测试需要满足以下条件:
- 微基准测试 - 尽可能精简测试代码。
- 确保数据具有足够大的量级,以保证准确的性能数据。
- 数据是随机的,但尽量保持一致,以模拟真实情况。
2.1. 数据准备
这次我们使用的是结构体数组。两个数组唯一的区别在于它们存储的内容。一个存储结构体实例,另一个存储指向结构体的指针。5000万个数据点足够大,可以确保性能数据的准确性。随机性由std::unique_ptr的内存分配器保证。每个指针都有一个唯一的随机内存地址。内存地址不一定一致,但缓存预取失败后CPU的读取速度大致相同,这可以确保部分一致性。
2.2. 测试函数
测试函数相对简单。我们遍历两个std::vector并操作其内部数据。最后,我们计算经过的时间。考虑添加noinline声明,以防止编译器展开函数,方便调试。
__declspec(noinline) float test_array(unsigned long long size) { float result = 0; std::vector<Point> points(size);
auto start = std::chrono::steady_clock::now(); for (const auto& i : points) { result = i.x + i.y + i.z + i.w; } const auto end = std::chrono::steady_clock::now(); std::cout << "Slow calculations took " << std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() << " microseconds" << std::endl;
return result;}template <int prefetch>__declspec(noinline) float test_pointer(unsigned long long size) { float result = 0; std::vector<std::unique_ptr<Point>> points;
for (decltype(size) i = 0; i < size; ++i) { points.emplace_back(std::make_unique<Point>()); }
auto start = std::chrono::steady_clock::now(); for (auto i = points.cbegin(); i < points.cend(); ++i) { if (prefetch) { _mm_prefetch((char*)((*std::next(i, 32)).get()), _MM_HINT_NTA); _mm_prefetch((char*)((*std::next(i, 48)).get()), _MM_HINT_NTA); _mm_prefetch((char*)((*std::next(i, 64)).get()), _MM_HINT_NTA); } result = (*i)->x + (*i)->y + (*i)->z + (*i)->w; } const auto end = std::chrono::steady_clock::now(); std::cout << "Slow calculations took " << std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() << " microseconds" << std::endl;
return result;}2.3. 性能数据
接下来是性能测试。您需要多运行几次并平均数据,以防止抖动。正如您清楚地看到的,结构体数组更快,指向结构体的指针数组更慢,而带软件缓存预取的指向结构体的指针数组则介于两者之间。
第三章 - 性能分析
下一阶段是分析问题,重点关注性能分析器中的PMC计数器。
3.1. 分析 PMC
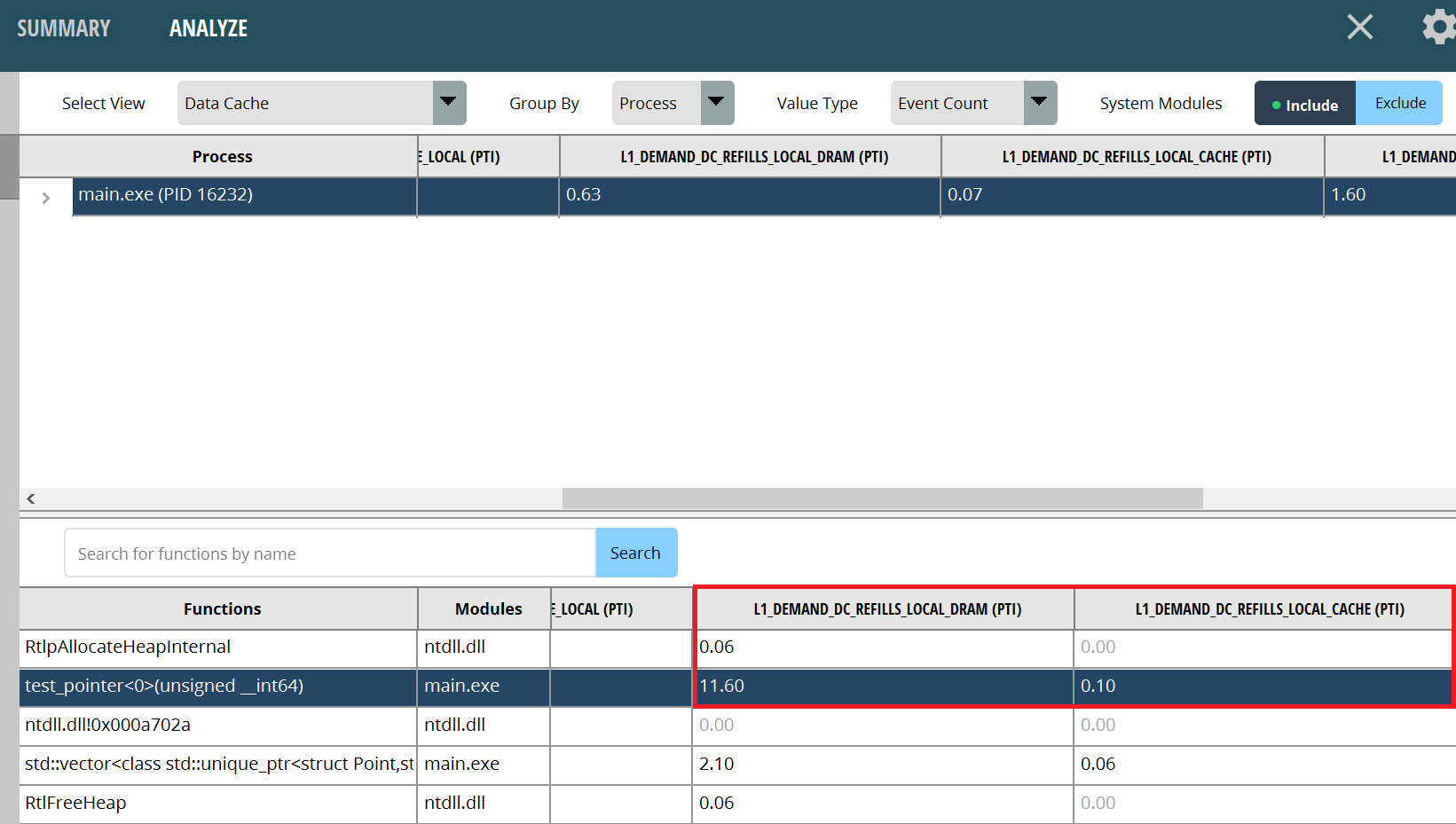
使用性能分析器分析PMC,选项集选择“Assess Performance (Extended)”。运行后,切换到“ANALYZE”页面,然后切换到“Data Cache”视图,查看与分支相关的PMC。L1缓存未命中的数量是每千条指令的L1_DEMAND_DC_REFILLS_LOCAL_DRAM、L1_DEMAND_DC_REFILLS_LOCAL_CACHE和L1_DEMAND_DC_REFILLS_LOCAL_L2。PTI后缀表示数据已按每千条指令进行了归一化。当然,这些名称在不同版本的性能分析器中可能会有所不同。它取决于PPR中相应的硬件PMC。首先,我们分析test_pointer<0>函数。显然,每千条指令有11.60次由L1缓存未命中引起的内存读取,以及0.1次由L1缓存未命中引起的较低级缓存读取,以及0.1次由L1缓存未命中引起的L3缓存读取。内存读取次数应尽可能少。
图1:指针数组缓存失效
双击test_pointer<0>函数会打开“SOURCES”页面。可以看到,缓存预取失败主要发生在指针操作附近。
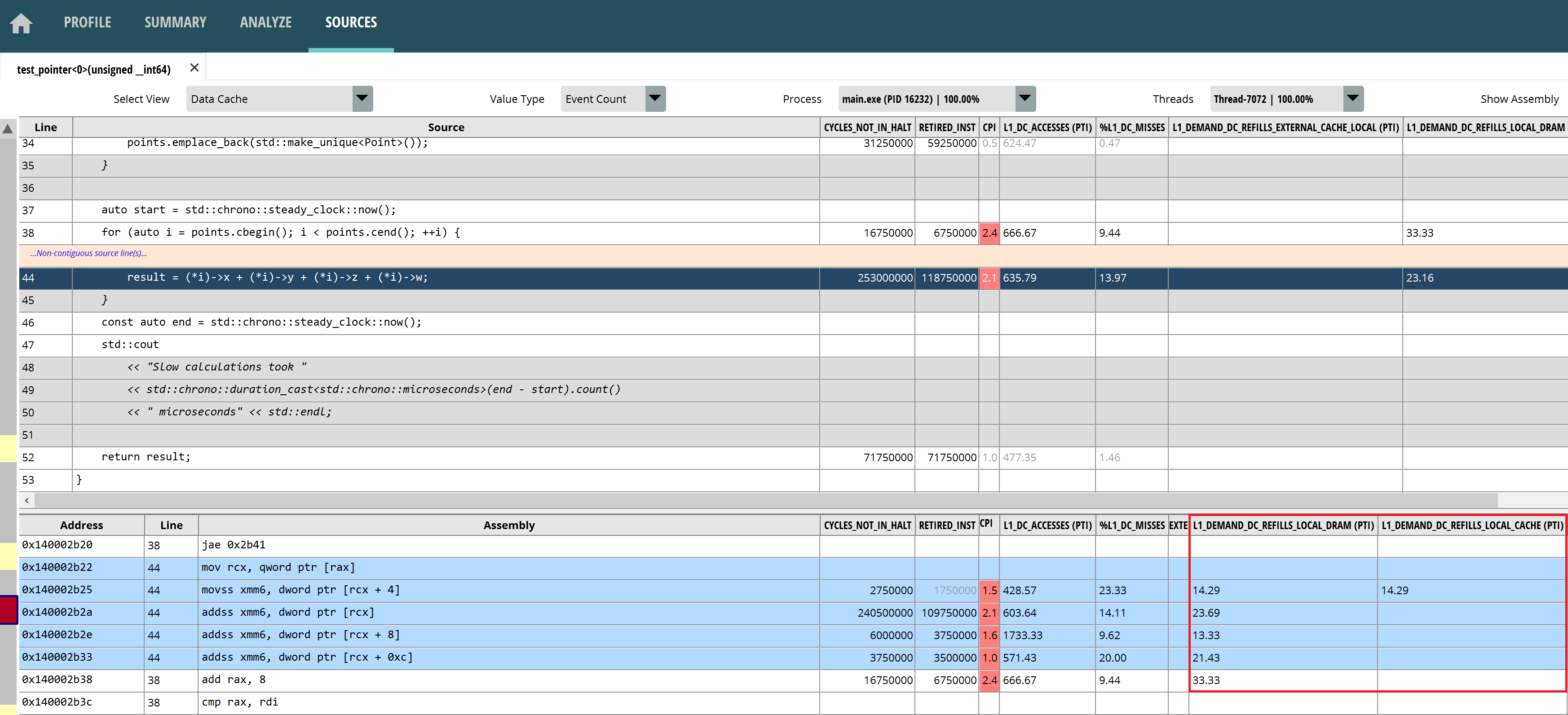 图2:指针数组缓存失效的汇编
图2:指针数组缓存失效的汇编
3.2. 硬件缓存预取
接下来,我们看一下test_array函数。很明显,缓存未命中次数较少,这保证了指令访问的延迟较低。这主要是因为连续的数据读取会触发CPU的硬件缓存预取,从而确保高缓存命中率。触发硬件缓存预取的此类数据结构访问模式取决于具体的CPU型号。请参考CPU编程手册了解这些细节。然而,在大多数情况下,CPU在处理连续数据的较小范围时表现良好。“AMD Ryzen™ Processor软件优化 GDC 2023”,第23-26页,是一个很好的参考。
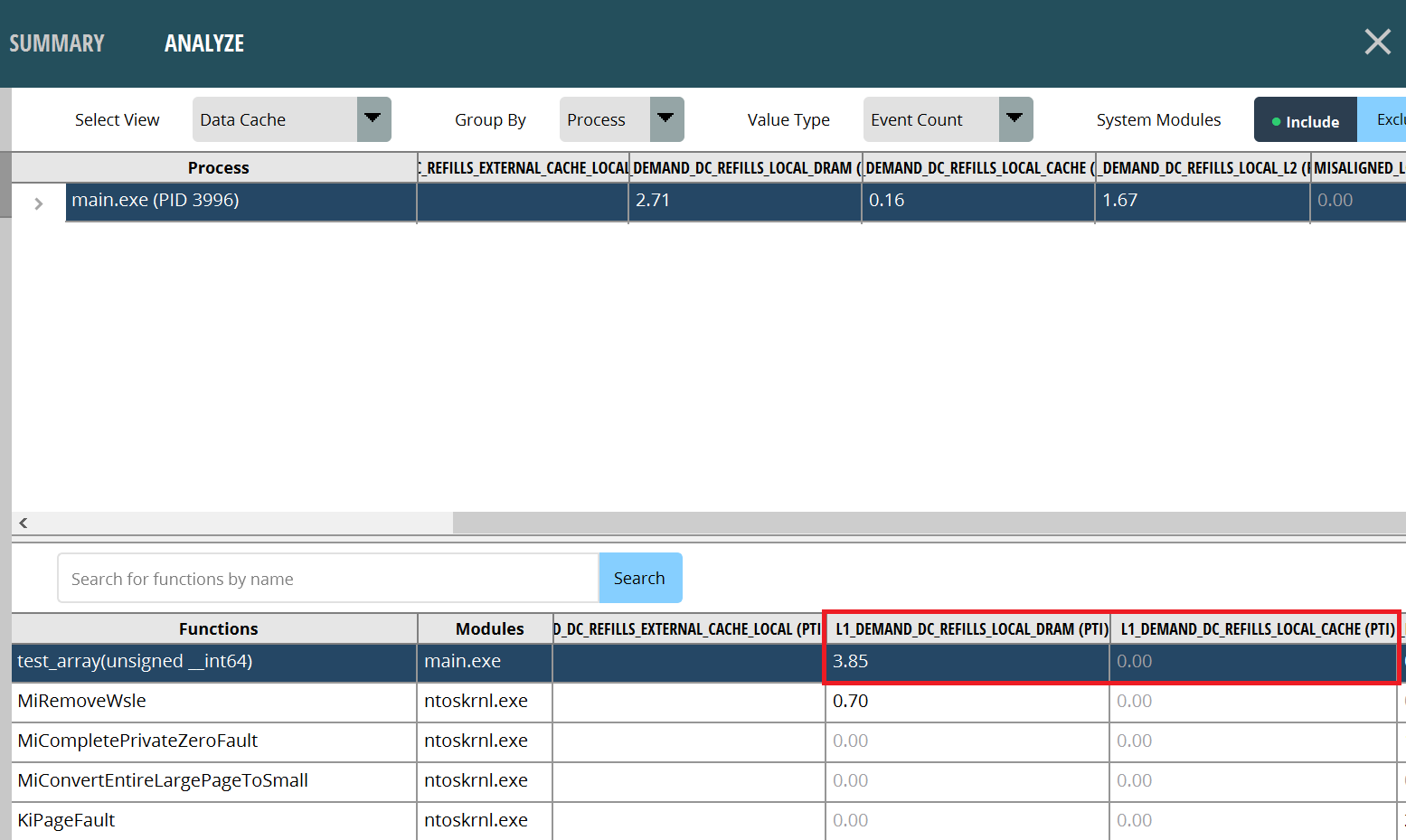 图3:连续数组缓存命中
图3:连续数组缓存命中
3.3. 软件缓存预取
现在让我们看看test_pointer<1>函数。我们可以看到,使用_mm_prefetch进行软件缓存预取可以减少缓存未命中次数,从而保证指令访问的延迟较低。然而,由于以下几个原因,延迟仍然不如硬件缓存预取:
_mm_prefetch本身也会消耗CPU时钟,不能过度使用。- 需要软件预取的地址很难确定。过多的硬编码地址是不合适的。
- 无效的软件预取可能会导致性能下降,因为我们试图预取的内存已经存在于缓存中。具体指标是
INEFFECTIVE_SW_PF。可以看出,在示例中,每千条指令有128.67次无效的软件缓存预取,这在实际项目中需要避免。
总而言之,当硬件预取不可用时,软件预取是一种权衡。它可以减少一些延迟,但很难达到最优。与硬件预取类似,软件预取策略也因CPU型号而异。“AMD Ryzen™ Processor软件优化 GDC 2023”,第22页,可以作为有用的参考。
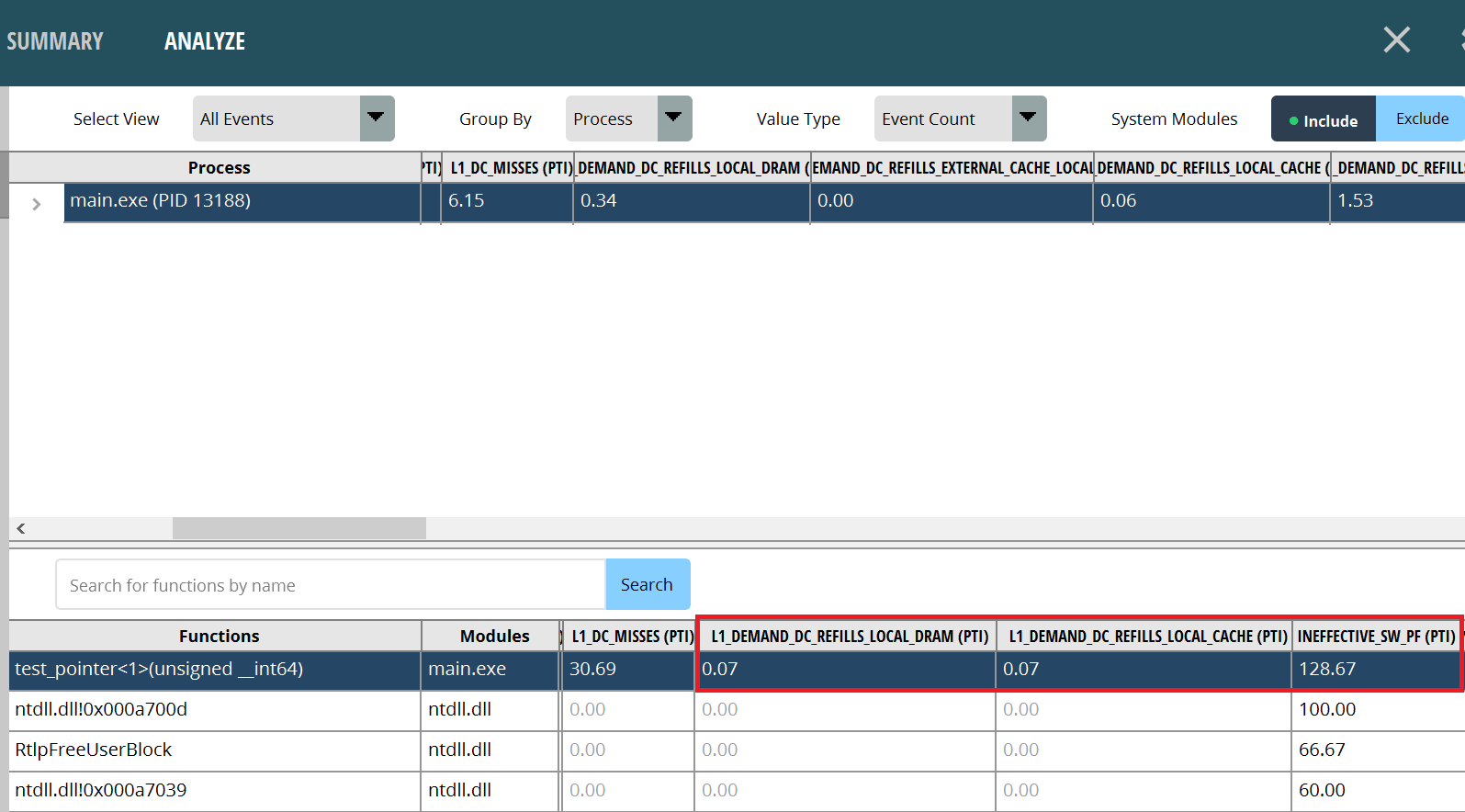 图4:指针数组缓存预取
图4:指针数组缓存预取
第四章 - 结论
这篇博文以缓存失效为例,简单展示了如何分析PMC并提供了一种解决方法。然而,需要注意的是,缓存问题极其复杂。本文提出的示例只是其中一种较为常见的。我们可能会在未来涵盖缓存对齐和多核乒乓缓存等问题。至此,一个完整的缓存失效分析过程已经完成。您可以看到不同内存操作背后巨大的性能差距。确保程序能够最大限度地利用CPU缓存以减少延迟,也是软件优化的一个重要任务。
最后,祝大家工作顺利。