AMD FidelityFX™ Variable Shading
AMD FidelityFX Variable Shading 将可变速率着色引入您的游戏。
在本文中,我们将通过阐述从基于顶点着色器的管线向网格着色器演变的动机来开启本系列。
为了欣赏网格着色器管线的灵活性和潜在的性能提升,回顾一下 GPU 如何使用顶点和索引缓冲区组合来处理传统绘图调用可能很有帮助。
对于传统的图形管线,网格通常被定义为一组顶点,每三个连续的顶点构成一个三角形。为了减少数据重复,可以使用可选的索引缓冲区来将三角形定义为一组三个索引,每个索引引用一个不同的顶点。为了比较网格着色器与顶点管线,我们将只关注后者带索引的顶点着色。
作为示例,我们将使用以下索引和顶点缓冲区,并跟踪前四个三角形通过 GPU 到光栅器的过程。

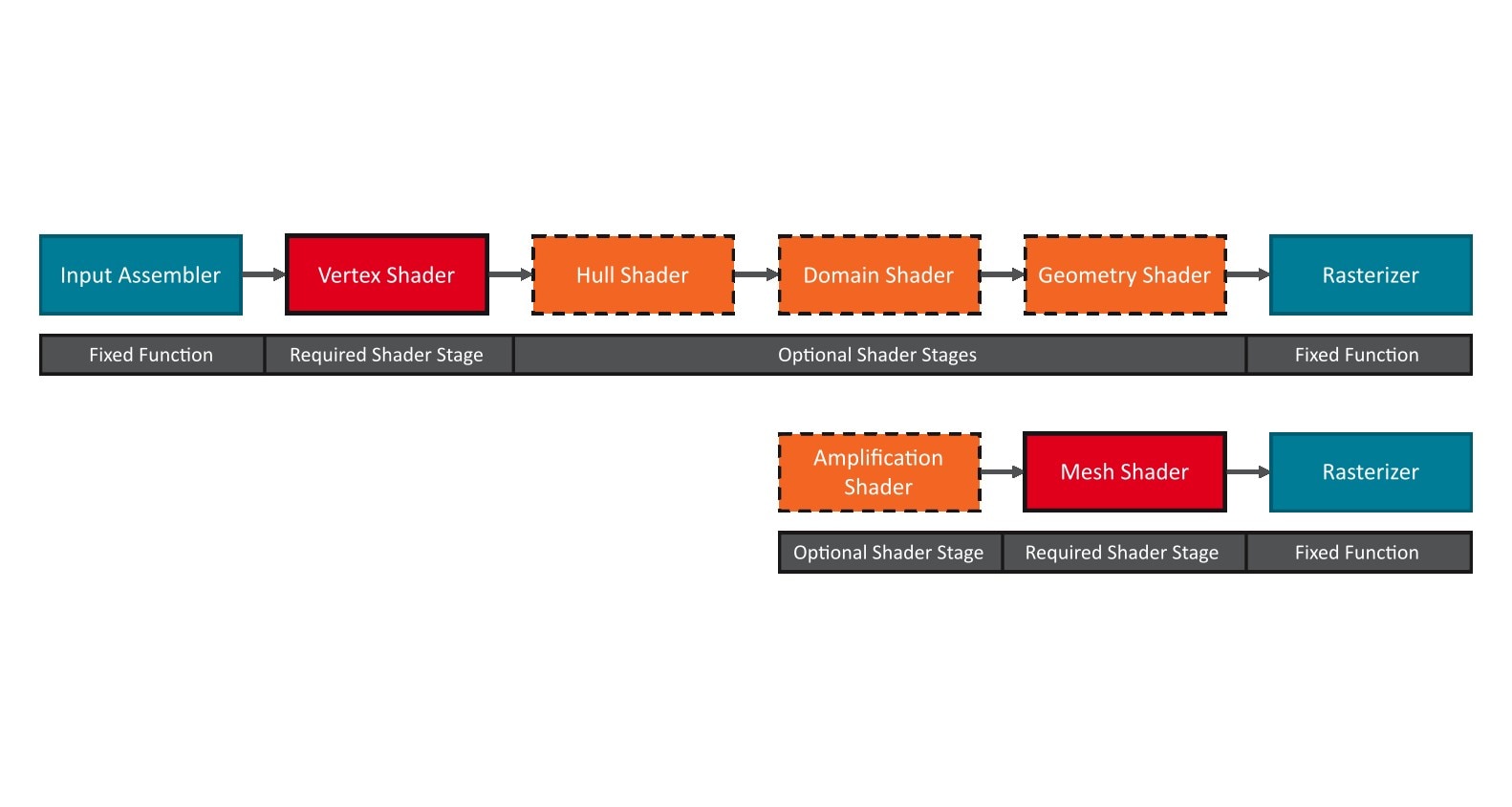
在这些图元能够被光栅化和着色之前,它们会经过 **输入装配器** 以及一个由多达四个不同着色器组成的、可编程的几何管线。
每个几何管线都需要一个顶点着色器。

为简单起见,在本篇博客中,我们将只探讨顶点着色器如何映射到我们的 RDNA™ 硬件。几何着色器和细分着色器阶段将在后续博客中介绍。
对于索引缓冲区引用的每个顶点,GPU 都需要运行一个顶点着色器实例来将顶点从顶点缓冲区中的输入布局转换到剪辑空间中的位置。由于输入网格使用了索引缓冲区,重用顶点的优势也应在此处适用,从而减少可能耗费资源的顶点着色操作的总数。输入装配器负责解析索引缓冲区并启动顶点的后续处理。
输入装配器实现顶点重用的一个明显方法是为顶点缓冲区中的每个顶点运行一个顶点着色器实例并存储转换后的顶点。然而,这种方法不可行,因为存储可能数百万个转换后的顶点可能会超出 GPU 的内存容量。此外,这种实现会延迟图元装配以及后续着色操作,直到所有顶点着色器实例执行完毕。
因此,我们需要一种能够并行着色顶点批次并将其组装成图元,而其他顶点仍在传输中或未处理的系统。
在 RDNA™ 显卡上,这是使用我们的下一代几何(NGG)技术实现的,我们将在下一节进行介绍。
为了说明 NGG 管线的各种组件及其协同工作方式,我们将跟随一个示例性的带索引的绘制调用穿越几何处理阶段。与之前一样,为简单起见,此绘制调用仅使用顶点着色器,而不使用几何或细分着色器。
为了绘制我们的示例网格,我们将以下绘制调用提交到图形命令列表。
graphicsCommandList->DrawIndexedInstanced(12 /* index count */, 1 /* instance count */, 0 /* start index location */, 0 /* base vertex location */, 0 /* base instance location */);一旦命令缓冲区被提交,并且绘制调用被 API 运行时和 GPU 驱动程序处理,绘制命令就会被发送到 GPU。该命令由以下组件接收和处理。

为了确定哪些顶点需要由顶点着色器处理,几何引擎会从索引缓冲区中选择一个图元子集。为了演示目的,几何引擎从上面的示例网格中选择了四个三角形。这个图元子集形成一个 **图元子组**:为了构建一个图元子组,几何引擎会扫描子集三角形的索引,并创建一个唯一的顶点索引列表。然后,几何引擎会根据该子组的唯一顶点列表,重新索引索引缓冲区中的顶点索引。从概念上讲,一个图元子组,即重新索引的顶点索引对和唯一顶点,构成了一个带有自己顶点和索引集的小网格——或称网格块(meshlet)。由于这些索引不直接引用原始输入顶点缓冲区中的顶点,而是引用唯一顶点列表中的顶点索引,我们将这些索引称为 **图元连接信息**。

图元组中的顶点将一起处理,一旦顶点处理完成,图元连接信息将用于将其组装成三角形,准备进行光栅化。在形成一个图元组并将其发送进行处理后,几何引擎会继续处理索引缓冲区中的下一个图元子集,直到所有图元都被渲染。
如上所示,图元连接索引只能引用同一图元子组内的顶点,因此着色顶点仅在图元子组内重用。
这一切对顶点调用和顶点重用意味着什么?
为了最大化顶点重用,我们理想情况下希望所有引用同一个顶点的图元都在同一个图元子组中。换句话说,我们希望每个顶点只出现在一个图元子组中。否则,GPU 将多次调用同一个顶点的顶点着色器,从而执行冗余计算并降低整体性能。由于图元子组受到最大顶点数或最大图元数的限制,因此理想的顶点重用(即每个顶点只处理一次)通常是不可能的。
相反,所谓的顶点缓存优化旨在将顶点重复降至可接受的水平。尽管图元子组是独立计算和光栅化的,与存储已转换顶点以供后续三角形重用的传统顶点缓存不同,但“顶点缓存”一词仍然常用于描述图元子组的行为。像 zeux 的 meshoptimizer 这样的库试图逼近 GPU 的顶点缓存行为并相应地重新排序索引缓冲区。共享相同顶点的图元会被聚集在一起,从而增加了在顶点缓存中找到该顶点的机会,或者将所有这些图元捆绑在同一个图元子组中。这种预处理可以并且应该静态地应用于任何三角形网格。
例如,斯坦福兔子模型是一个拥有近 7 万个三角形和近 3.5 万个顶点的照片扫描网格。由于其照片扫描的性质,顶点以类似网格的方式组织,三角形组织成该网格中的垂直线。这些线条导致子组中的顶点最多被重用两次,从而导致顶点被多次着色。使用 zeux 的 meshoptimizer 和 `meshopt_optimizeVertexCache` 函数可以大大减少重复的顶点着色,从而提高性能。
| 网格 | 优化后的网格 | |
|---|---|---|
| 顶点 | 34.8k | 34.8k |
| 顶点着色器调用次数 | 143.9k | 48.9k |
| 重复因子 | 4.13 | 1.40 |
| 可视化 不同的颜色代表不同的图元子组。 |  | 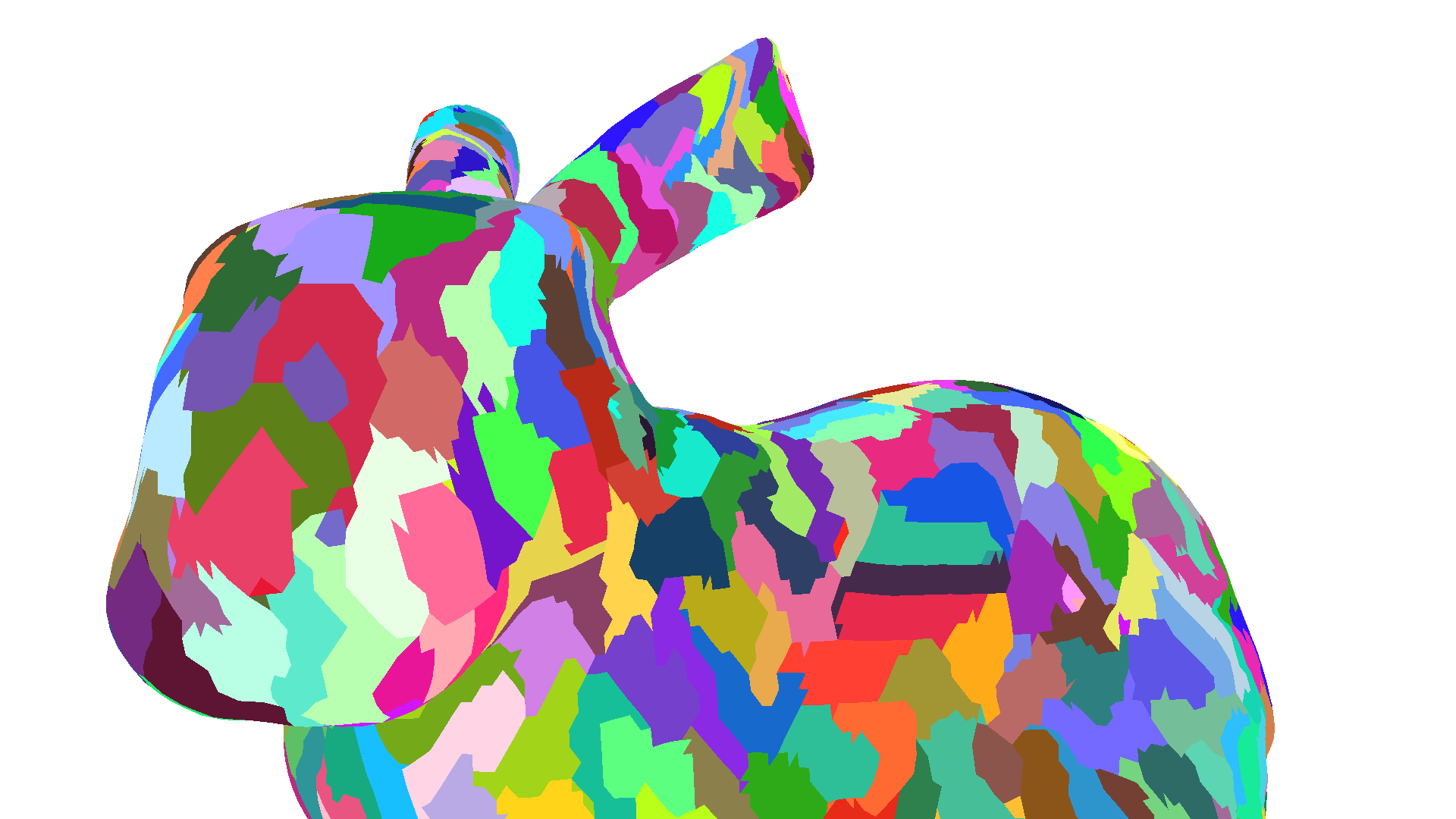 |
到目前为止,我们已经介绍了几何引擎如何从输入的顶点和索引缓冲区生成图元子组,但还没有介绍图元子组是如何被处理和光栅化的。与典型的顶点、几何和可编程细分着色器阶段不同,NGG 将每个阶段的不同功能组合到两个不同的着色器中。
顾名思义,图元着色器用于处理图元子组。每个图元着色器线程被分配给图元组中的一个顶点索引和一个图元。图元着色器线程接收其分配图元的图元连接信息,并从相应的顶点缓冲区加载其分配顶点的顶点信息。然后,它执行顶点着色。最后,图元着色器发出 `exp` 指令,将接收到的图元连接信息和转换后的顶点导出到着色器导出中,为图元装配和光栅化做好准备。由于图元着色器还可以修改图元连接信息,因此它们也可用于实现细分域和几何着色器。

图元装配器加载一个图元的图元连接数据以及三个引用的顶点,组装三角形,并在将图元发送到光栅器之前执行剔除和视图变换操作,从而结束我们在 NGG 管线中的旅程。
总而言之,我们已经看到了 RDNA™ GPU 如何处理带索引的绘制调用,以及下一代几何管线如何处理顶点重用。然而,带索引的顶点管线仍然存在挑战和限制。顶点管线不提供对顶点着色器调用和顶点重用的直接控制。通过顶点缓存优化获得的有限控制通常难以实现。顶点缓存优化器旨在支持多种硬件供应商和硬件代,因此无法在所有 GPU 上实现同等出色的性能。最后,索引缓冲区必须符合 GPU 可以理解的固定格式,这限制了实现基于索引的解压缩技术的灵活性。
在下一章中,我们将探讨网格着色器如何解决上述挑战和限制,网格着色器还引入了哪些进一步的可能性,以及网格着色器如何融入 NGG 管线。
网格着色器于 2019 年被引入 Microsoft DirectX® 12,并于 2022 年作为 `VK_EXT_mesh_shader` 扩展引入到 Vulkan 中。网格着色器引入了一种新的、类似于计算着色器的几何管线,使开发人员能够直接将顶点和图元的批次发送到光栅器。这些批次通常被称为 **网格块 (meshlets)**,由少量顶点和一组引用这些顶点的三角形列表组成。概念上,这些网格块与我们之前探讨的图元子组非常相似,因为它们也可以用于表示大型网格的一小部分,但由于这些网格块完全由用户定义,因此它们也可以用于渲染程序化几何体,如地形或细分曲面。后者将在本篇博客系列的后续文章中更详细地介绍。在本期的第一部分中,我们将重点关注使用网格着色器渲染三角形网格。
网格着色器引入了两个新的 API 着色器阶段:
这两个新的着色器阶段取代了传统的顶点、曲面、域和几何着色器管线,并且不能与其中任何一个阶段结合使用。

网格着色器和放大着色器都采用了与计算着色器非常相似的编程模型,因此更符合现代图形卡的统一计算硬件架构。网格着色器不是像计算着色器那样,拥有一个线程对应一个顶点、采样点或图元且没有与其他线程的可见性或通信,而是组织成线程组。每个线程组指定并写入可变数量的顶点和图元,而没有要求将图元或顶点绑定到特定线程。任何线程都可以写入任何顶点或图元,但应牢记一些我们将在下一篇博客文章中讨论的一般最佳实践。
由于线程组的计算式组织方式,启动网格着色器也与传统的绘制调用不同。`DispatchMesh` 命令(Vulkan 中为 `vkCmdDrawMeshTasksEXT`)不指定要处理的顶点或索引数量,而是指定要启动的网格着色器线程组数量,就像在计算着色器中一样,在三维网格中进行指定。
graphicsCommandList->DispatchMesh(threadGroupCountX, threadGroupCountY, threadGroupCountZ);这种直接启动线程组也意味着网格着色器会跳过输入装配器阶段。这使得开发人员可以完全控制从网格着色器导出的图元,并消除了对输入数据的任何限制。与计算着色器一样,网格着色器可以读取甚至写入任何资源。对要光栅化的图元的直接控制还使得能够剔除单个图元,或(与放大着色器结合时)整个网格块。
绕过输入装配器需要将顶点重用计算卸载到预处理阶段。这可以避免每一帧或每一次绘制调用反复重新计算重用信息。相反,它可以在多个绘制调用和帧之间共享。移除输入装配器也意味着它不会成为管线瓶颈。这使得网格着色器能够直接适应不同的 GPU 配置。此外,淘汰细分和几何着色器的旧式几何放大编程模型意味着网格着色器中的几何放大可以更好地映射到计算硬件,并减轻了固定功能硬件的使用。
最后,网格着色器在线程组中的组织允许线程通过 wave intrinsics 和组共享内存进行通信,以协同计算一个或多个顶点或图元。
总之,网格着色器的计算式编程模型使开发人员能够克服传统顶点管线的关键限制,同时还为三角剔除或实时几何解压缩等高级渲染技术提供了更大的灵活性。作为实际网格着色器应用的案例研究,我们将在后续的博客文章中探讨几何解压缩。
在介绍放大着色器之前,我们先简要看看网格着色器如何适应 NGG 管线。
正如在第一部分中所讨论的,NGG 管线由两个着色器阶段组成:曲面着色器和图元着色器。图元着色器用于处理图元组,能够通过着色器导出将顶点属性以及图元连接信息(即图元)导出到图元装配器。很容易看出,这种功能可以直接用于将网格着色器映射到 NGG 管线。
`DispatchMesh` 命令直接指定了一个要启动的三维网格着色器线程组网格,而这又直接映射到图元组。因此,在启动网格着色器线程组之前,不需要进行顶点去重或重用扫描。我们之前已经讨论过,网格着色器的启动与计算着色器的分派非常相似。然而,网格着色器线程组仍然通过几何引擎启动。在这种情况下,几何引擎仍然负责跟踪和管理着色器导出中的分配,以及管理图元装配器的状态(图元模式、剔除等)。最重要的是,由于在启动网格着色器之前不知道顶点和图元数量,几何引擎会接收实际的顶点和图元计数,并将其转发给图元装配器。

当使用网格着色器时,几何引擎的职责与传统顶点着色的职责大相径庭,因此几何引擎实现了一个特殊的快速启动模式,该模式会绕过任何顶点重用检查和图元子组形成阶段。
放大着色器是一个可选的着色器阶段,在网格着色器之前运行,并且可以控制后续网格着色器线程组的启动。每个放大着色器线程组可以启动可变数量的网格着色器线程组,即——顾名思义——放大 GPU 上执行的总体工作负载。然而,这种放大与使用细分着色器实现的放大是不同的。放大着色器不是通过固定功能硬件在控制图元内部放大图元数量,而是以更粗略的级别运行,仅指定要启动的网格着色器线程组的数量。即便如此,也可以使用放大着色器来模拟固定功能细分放大的效果。
为了启动网格着色器,放大着色器可以调用 `DispatchMesh` 着色器内置函数,并指定一个要启动的网格着色器线程组的三维网格。此内置函数在 CPU 上的行为方式与 `DispatchMesh` 命令相同。而 CPU 可以在 `DispatchMesh` 调用之间写入或修改着色器的根签名,但放大着色器却不能。取而代之的是,放大着色器可以将一个用户定义的载荷从放大着色器传递给所有后续启动的网格着色器。
DispatchMesh(threadGroupCountX, threadGroupCountY, threadGroupCountZ, payload);从 CPU 启动放大着色器的方式与启动网格着色器相同:如果图形管线状态指定了放大着色器,则 `DispatchMesh` 命令中指定的三维网格直接指向要启动的放大着色器网格。无法选择启动网格着色器还是放大着色器,这需要独立的图形管线状态。

这种在 GPU 上直接进行工作放大的方式可能与最近引入的 GPU Work Graphs 类似,但放大着色器有一些关键的区别和限制。
即使存在这些限制,放大着色器也通过允许在 GPU 上完全进行动态工作放大或缩减,扩展了网格着色器管线的灵活性。放大着色器的应用示例包括:
在实例剔除和动态 LOD 的情况下,每个放大着色器线程组中的线程想要启动的网格着色器线程组数量会因线程组而异。这可能会稍微复杂化将网格着色器线程组分配给载荷中的特定元素。
我们将在后续的博客文章中更详细地介绍网格的网格块剔除和细分几何体的动态细节级别。
总结我们到目前为止的探讨:我们已经了解了 RDNA™ GPU 如何处理带索引的几何体,以及常规几何体如何在图元子组(或网格块)中渲染,以及随之而来的挑战,例如顶点缓存优化。我们已经看到了网格着色器如何通过赋予开发人员对几何处理管线的完全控制来克服这些挑战,从而消除了运行时顶点重用检查的需要,同时提供了更灵活的几何处理。我们研究了网格着色器如何映射到下一代几何管线,以及网格着色器快速启动路径如何工作。我们还介绍了放大着色器,并触及了它们实现动态 GPU 渲染管线的能力。
在本系列博客文章的下一部分中,我们将讨论一些编写网格着色器的最佳实践,并涵盖网格着色器的性能分析和优化。在后续的博客文章中,我们将展示使用网格着色器的案例研究,并探讨其各种功能。特别是,我们将关注几何解压缩和程序化几何体。
第三方网站链接仅为方便用户提供,除非另有明确说明,AMD不对任何此类链接网站的内容负责,且不暗示任何认可。GD-98
Microsoft 是 Microsoft Corporation 在美国和/或其他国家/地区的注册商标。本出版物中使用的其他产品名称仅用于标识目的,并可能为其各自所有者的商标。
DirectX 是 Microsoft Corporation 在美国和/或其他国家/地区的注册商标。