AMD FidelityFX™ Variable Shading
AMD FidelityFX Variable Shading 将可变速率着色引入您的游戏。
在探索了网格着色器和下一代几何管线之后,我们将介绍编写网格着色器和放大着色器的一些最佳实践。在本篇博客的第二部分,我们还将探讨如何使用 AMD Radeon™ Developer 工具来分析和优化网格着色器。
以下最佳实践应被视为以最优方式使用网格着色管线的指南。根据您的应用程序和需求,其中一些建议可能不完全适用。我们将提供选择这些指南的理由,以便您能够决定这些理由是否也适用于您的应用程序,从而做出明智的决定。
在本节中,我们将讨论选择 meshlet 生成参数的一些考虑因素。一个 meshlet 由 个顶点和 个三角形组成。通常,meshlet 构建器会接收两个值的上限,即 和 。
不同的图形 API 和供应商对每个线程组允许输出的顶点和图元数量的上限值各不相同,介于 256 到 1024 之间。在 Direct3D12 中,每个 meshlet 的顶点和图元数量均被限制为 256。
经验法则:对于一个 2-流形(2-manifold-ish)的 meshlet,顶点与三角形的比例通常为 。这表明了在这两个值中,哪一个将成为大多数 meshlet 大小的限制因素。
顶点变换通常是 mesh shader 的主要计算负载。因此,为了提高每个线程组内的计算利用率,将 设置为线程组大小的倍数,并使 不成为限制因素,是很有意义的。
考虑到 mesh shader 索引只能引用同一 meshlet 中的顶点,meshlet 边缘的顶点必须被复制并处理多次。因此,meshlet 生成可以看作是类似顶点缓存优化,主要区别在于 meshlet 的顶点复制是由 meshlet 生成器预先决定的,而不是由图形卡硬件决定的,从而使开发人员完全控制顶点的处理方式。meshlet 构建器会尝试在 和 的限制下找到连贯的三角形集合,并使用与顶点缓存重用优化类似的准则:每个包含的顶点应被尽可能多的包含的三角形使用。总的来说,meshlet 越大,边界边长与总 meshlet 面积的比例就越大。
因此,我们建议生成 和 的 meshlet 大小,因为这在整体性能和顶点复制之间取得了良好的平衡。Christoph Kubisch1 推荐的 和 的配置,虽然复制了更多的顶点,但性能相似。
以第一个博客文章中的斯坦福兔子网格为例,该网格近 35,000 个顶点和近 70,000 个三角形,我们可以看到静态地将网格划分为 meshlets 可以实现比顶点缓存优化网格更低的顶点复制率。此外,这些较低的顶点重用率与供应商和硬件代无关。
| 网格 | 优化后的网格 | Meshlets2 | |
|---|---|---|---|
| 转换后的顶点 | 143.9k | 48.9k | 43.2k |
| 复制因子 | 4.13 | 1.40 | 1.24 |
| 可视化 不同的颜色代表不同的图元子组或 meshlet。 |  | 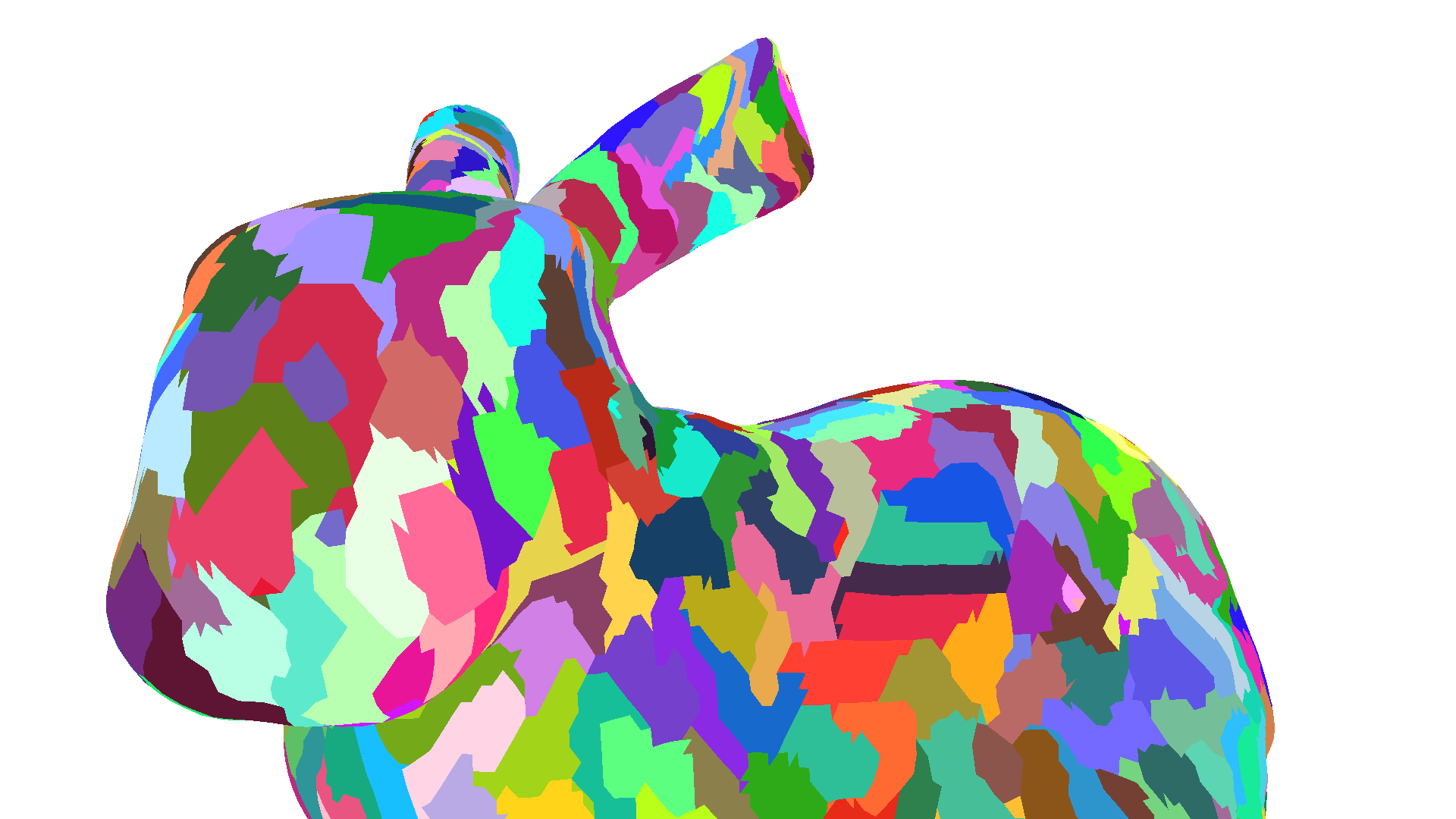 |  |
此外,一些 meshlet 生成器还会考虑 meshlet 生成的其他标准,例如剔除包围体的大小或顶点和拓扑的可压缩性。这两点将在以后的文章中进行解释。
在为 meshlet 生成建立了一些指导方针之后,我们现在将重点关注在 mesh shader 中处理这些 meshlet 的一些最佳实践。
如前所述,顶点变换可能是 mesh shader 的主要计算负载,因此我们建议将线程组大小设置为与 meshlet 中的最大顶点数相匹配。如果无法做到,请尽量将 meshlet 中的最大顶点数均匀分配给线程。对于 Direct3D12,线程组大小限制为 128 个线程,这与我们推荐的 的 meshlet 大小相符。为了利用 GPU 的并行架构,我们建议将线程组大小设置为 128,从而实现线程与顶点的一对一映射。如果顶点限制较低,例如 ,我们建议仅在 低于 128 时才调整线程组大小,因为在大多数情况下,拥有一个专门用于导出额外图元的线程会更快。我们的实验表明,如果 mesh shader 的占用率受到像素着色器或其他并行调度程序的严重限制,将线程组大小减少到例如 64 可以带来少量的性能提升。
mesh shader 的输出在 mesh shader 的函数签名中定义为数组。
void MeshShader(..., out vertices VertexAttribute verts[128], out indices uint3 triangles[256])这些数组的大小从 GPU 的角度来看,代表了顶点和图元输出的最坏情况。因此,几何引擎使用这些限制来在启动 mesh shader 线程组之前,在 shader 导出中预留输出空间。
因此,这些限制应尽可能设置得低,即在预计算 meshlet 的情况下,设置为 和 。
上面显示的 vertices 和 indices 数组在线程组之间共享,任何线程都可以写入数组的任何元素。mesh shader 必须将写入这些数组的数据传输到 shader 导出中,以便图元装配器进行装配和栅格化。在 RDNA™ 显卡上,exp 指令用于将单个图元或顶点导出到 shader 导出。shader 导出中图元和顶点的顺序由线程组中线程的顺序决定,即线程组中的第 个线程将写入第 个顶点或图元。
对于顶点来说,这意味着第 个线程必须导出第 个顶点,否则三角形将错误地组合。对于图元连接信息,Microsoft DirectX® 12 Mesh Shader 规范对栅格化顺序施加了以下约束:
任何单个 mesh shader 线程组生成的三角形始终按照该线程组指定的图元输出顺序被栅格化器处理。
因此,第 个线程还必须导出第 个图元,以遵守此约束。
如果第 个线程未生成第 个顶点或图元,即另一个线程已写入 verts[i] 或 triangles[i],则必须通过组共享内存(group shared memory)在线程之间交换顶点和/或图元信息。这会增加 mesh shader 的延迟和资源需求。如果 mesh shader 从第 个线程写入 verts[i] 和 triangles[i],那么这些值可以直接导出到 shader 导出,而无需通过组共享内存。
由于 Direct3D12 中的最大线程组大小限制为 128,而最大顶点数和图元数可达 256,因此在某些情况下线程必须写入多个顶点或图元。在 RDNA™ 2 架构的显卡上,线程限制为单个顶点和图元导出。因此,线程组会扩展额外的隐藏线程来导出剩余的顶点和图元。通过组共享内存与这些线程交换数据。
RDNA™ 3 架构的显卡可以为 exp 指令指定一个波前(wave-wide)偏移量,因此能够从第 个线程导出第 个和第 个顶点或图元。在这种情况下,偏移量 通常是 128。
总之,我们建议在线程组中,从第 个线程开始,写入第 个顶点和第 个图元。如果顶点或图元数量超过线程组大小,例如在上述推荐的 和 配置中,我们建议使用面向线程组的步长来写入顶点和图元,例如,第 个线程写入 triangles[i] 和 triangles[i + 128]。
下面的代码展示了一个示例网格着色器,它导出最多 128 个顶点和最多 256 个图元。
[numthreads(128, 1, 1)][outputtopology("triangle")]void MeshShader(in uint groupId : SV_GroupID, in uint threadId : SV_GroupThreadID, out vertices VertexAttribute verts[128], out indices uint3 triangles[256], out primitives PrimitiveAttribute prims[256]){ Meshlet meshlet = meshlets[groupId];
SetMeshOutputCounts(meshlet.vertexCount, meshlet.primitiveCount);
for (uint i = 0; i < 2; ++i) { const uint primitiveId = threadId + i * 128;
if (primitiveId < meshlet.primitiveCount) { triangles[primitiveId] = LoadPrimitive(meshlet, primitiveId); prims[primitiveId] = LoadPrimitiveAttributes(meshlet, primitiveId); } }
if (threadId < meshlet.vertexCount) { verts[threadId] = LoadVertex(meshlet, threadId); }}如上所述,几何引擎必须在启动网格着色器线程组之前,为着色器导出预留输出空间。着色器导出的空间是有限的,因此可能会将网格着色器的整体占用率限制为 GPU 范围内的最大网格着色器线程组数量。着色器导出内存大小的设计是为了让常规的网格着色器能够达到光栅器的三角形吞吐量。对于简单的网格着色器,这意味着大约 25% 的占用率足以达到三角形吞吐量上限。

更复杂的网格着色器可能会看到稍高的占用率,但也倾向于受限于着色器导出的可用内存。因此,我们建议仅在网格着色器中执行必要的计算,并提前预处理其他数据,例如图元的顶点重用信息。
网格着色器的类计算编程模型也使得使用组共享内存进行线程或波次之间的通信成为可能。但是,由于组共享内存是有限的,并且分配大量组共享内存会降低整体(网格)着色器的占用率,因此我们建议不要使用组共享内存来临时存储网格着色器线程组的所有顶点或图元。
网格着色器通常在 wave64 模式下编译,即每波次 64 个线程,这意味着对于 128 个线程的线程组大小,只需要两个波次。使用某些指令,例如 WavePrefixSum,可能会导致着色器在 wave32 模式下编译,从而需要两倍的波次来执行相同的线程组。这也会导致网格着色器的占用率看似更高,而实际上并没有并行运行更多的线程组。
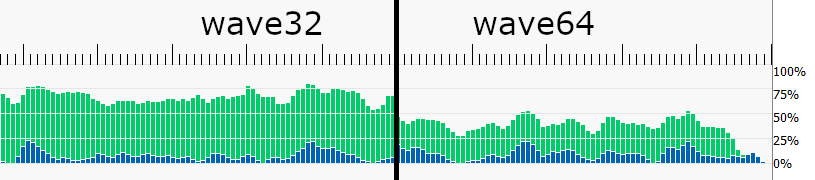
网格着色器的占用率也可能暂时受到像素着色器线程组的限制,例如,当一个或多个网格单元覆盖足够的屏幕区域,从而用像素着色器操作填满 GPU 时。在这种情况下,像素着色器优先于网格着色器,以缓解光栅器的输出压力。 网格着色器占用率(绿色)受像素着色器工作负载(蓝色)限制。
网格着色器占用率(绿色)受像素着色器工作负载(蓝色)限制。
除了每个顶点的属性数据外,网格着色器还可以指定每个图元的属性。在像素着色器中,这些属性可以像任何其他每个顶点的属性一样读取,主要区别在于这些属性不会在图元上进行插值。
struct PrimitiveAttribute { float4 primitiveColor : COLOR0;}
[numthreads(128, 1, 1)][outputtopology("triangle")]void MeshShader(... out primitives PrimitiveAttribute prims[256]){ prims[primitiveId] = LoadPrimitiveAttributes(meshlet, primitiveId);}将某些属性作为图元属性传递可以减少顶点重复,并且/或者通过减少网格着色器写入的属性内存的总大小来帮助减少内存流量。一些例子包括平面着色(flat-shading),其中法线属性是按图元指定的,而不是按顶点指定的,或者像 Ptex 这样的纹理映射系统,它为每个图元指定不同的纹理坐标。将这些属性作为图元属性写入,可以使像素着色器在不重复顶点的情况下仍然读取正确的属性值。
SV_CullPrimitive。图元装配器可以加载多个三角形进行装配,并以最小的开销丢弃任何被剔除的图元。然而,这些被剔除的图元仍然会计算在网格着色器的总图元数量中。SetMeshOutputCounts。此调用将为存储顶点和图元属性(除顶点位置外)预留输出内存。尽早请求内存有助于隐藏几何引擎中内存分配所需的延迟。放大着色器(Amplification shaders),顾名思义,可以在 GPU 上直接用于放大网格着色器绘制调用的工作负载。然而,这个系统带有一些注意事项,需要牢记一些性能考量。
如第一篇博客文章所述,网格着色器具有类计算的编程模型,但仍需要通过几何引擎启动,以便为着色器导出中的索引和顶点位置预留输出空间。除了这个要求之外,我们还希望放大的工作能够在整个 GPU 上执行,从而利用现代 GPU 上巨大的并行性。
为了通过几何引擎实现网格着色器的负载均衡启动,DispatchMesh 内建函数调用会反馈给命令处理器,并以与 CPU 发出的 DispatchMesh 命令非常相似的方式进行处理。为了遵守指定的栅格化顺序,命令处理器必须严格按照处理这些命令的顺序进行。命令需要按照放大着色器线程组启动的顺序执行。
整个过程的代价是增加了渲染过程的延迟。为了弥补这种延迟,需要足够高的放大率,即单个放大着色器线程组启动的网格着色器线程组的平均数量。
在放大着色器执行每网格单元剔除操作(即检查预定网格单元集的每个元素的可见性)的场景中,我们建议每个放大着色器线程组处理至少 32 或 64 个元素(例如,网格单元)。通过相应地选择放大着色器线程组的大小,可以使用 RDNA™ 图形卡上的 WavePrefixCountBits 和 WaveActiveCountBits 波次内建函数来实现剔除。
bool visible = false;const int meshletId = threadId;if (meshletId < meshletCount){ visible = IsMeshletVisible(Meshlets[meshletId]);}
if (visible){ const uint idx = WavePrefixCountBits(visible); payload.meshletIds[idx] = meshletId;}
const uint meshletCount = WaveActiveCountBits(visible);DispatchMesh(meshletCount, 1, 1, payload);增加单个放大着色器线程组处理的元素数量可以减少发送回命令处理器的命令数量,从而减少延迟。
对于其他应用,例如动态细节级别选择或几何放大(例如,细分曲面),也适用类似的原理。单个放大着色器线程组通常应该启动至少 32 个网格着色器线程组,以最佳地隐藏增加的延迟。
放大着色器线程组还可以输出高达 16k 字节的有效负载。由该放大着色器线程组启动的所有网格着色器线程组都可以访问此 16k 有效负载。此有效负载需要存储在内存中,以便网格着色器读取它,因此需要由放大着色器写入内存。因此,更大的有效负载在内存使用和内存读写操作方面可能成本很高。我们建议将放大着色器有效负载的大小保持在最低限度,并且仅传输无法由网格着色器直接加载、计算或推断的数据。
典型的放大着色器有效负载包含一个参数数组,其中每个元素由一个或多个后续启动的网格着色器线程组处理。如果有效负载的每个元素只由一个线程写入,编译器可以优化对有效负载的写入,并将该元素直接写入内存。
在最后一部分,我们将展示如何使用 Radeon™ Developer Tool Suite,特别是 Radeon™ GPU Profiler (RGP),来分析和优化网格着色器。
从 1.15 版本开始,Radeon™ GPU Profiler 增加了对网格着色器事件的支持。DispatchMesh 命令现在显示在事件时间视图中,并且也显示在最昂贵的事件之下。
在波次占用率时间线上,网格着色器显示为几何着色器(GS),同时还有缓存计数器和下面的事件。
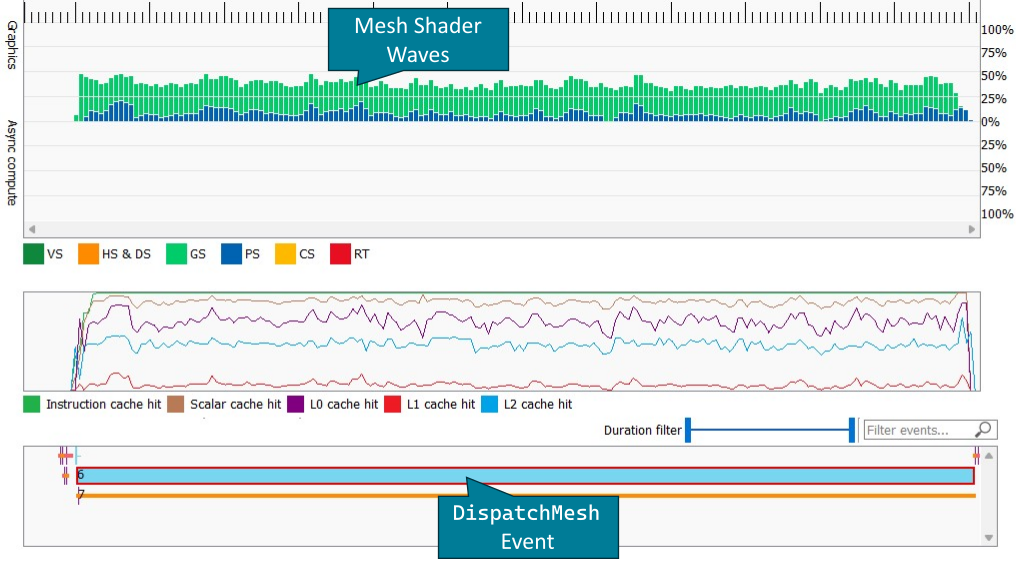
下面,可以在 VS 和 GS 着色器阶段看到网格着色器管线状态。在这里,您可以看到为 DispatchMesh 命令启动的波次和线程总数,以及波次模式。如上一节的网格着色器占用率优化中所述,这可能会对显示的波次占用率产生重大影响,而不会改变并发网格着色器线程组的数量。

如果在捕获跟踪时启用了指令跟踪,并且启动了足够数量的网格着色器波次,则可以在 VS 或 GS 管线阶段下看到网格着色器指令计时。
最值得注意的是,指令计时还包括用于将图元或顶点信息发送到着色器导出的导出指令。

exp prim 存储单个图元的图元连接信息,exp pos0 存储单个顶点位置。在 RDNA™ 3 图形卡上,顶点属性(如法线或纹理坐标)存储在内存中。在 RDNA™ 2 图形卡上,顶点属性使用 exp param{n} 指令写入。
高导出指令延迟,尤其是在第一个 exp 指令上,可以被视为网格着色器受光栅器吞吐量限制的指标。仅在着色器发送了 MSG_GS_ALLOC_REQ 消息后才能进行导出,该消息发送由 SetMeshOutputCounts 指定的网格着色器线程组的顶点和图元数量。
尽早调用网格着色器中的 SetMeshOutputCounts 有助于隐藏发送此命令的延迟。
放大着色器作为计算着色器在异步计算队列上执行,因此在 RGP 中显示为计算着色器。放大着色器发出的网格着色器调度显示为单独的事件。由于这些事件通常只包含少量线程组,因此网格着色器的指令计时可能不可用,或者由于样本数量少而略有不准确。
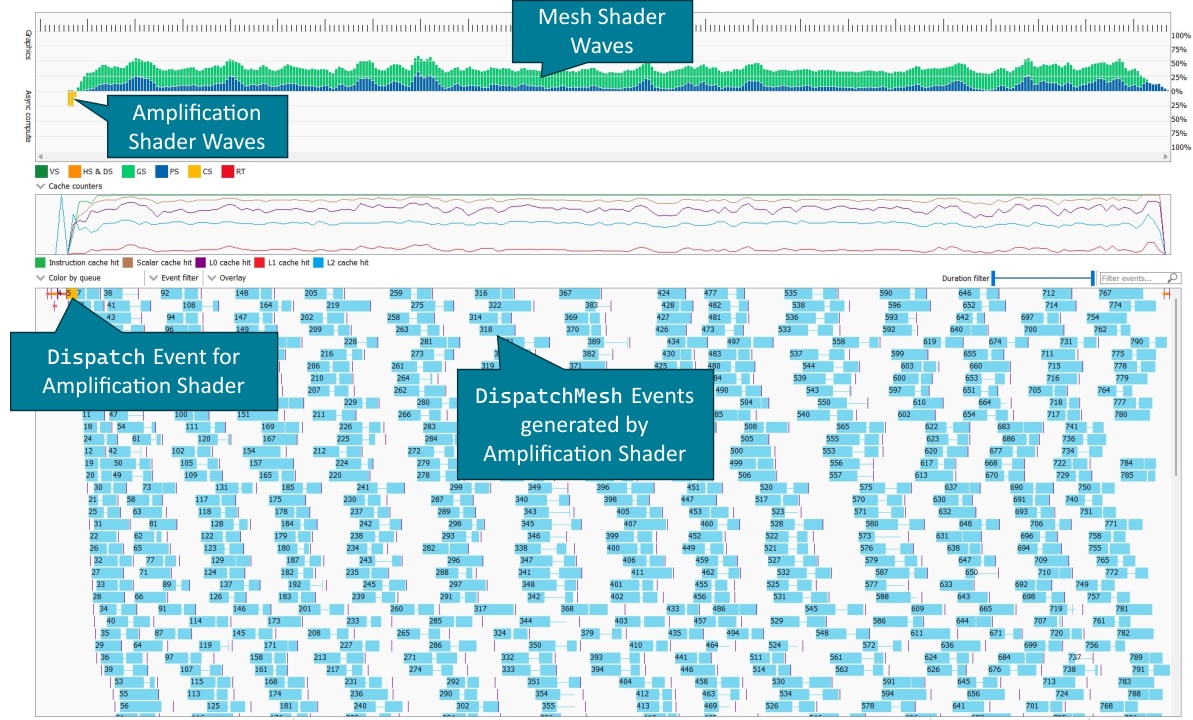
放大着色器发出的每个网格着色器调度的网格着色器线程组数量反映在 PrimS 波次的总体数量中。此信息可在详细信息窗格中找到,在 Wavefront occupancy 视图或 VS/GS 管线状态中。
| 详细信息窗格 | 管线状态 |
|---|---|
 |  |
放大着色器通过内存环形缓冲区将调度命令和有效负载发送回命令处理器。为了确保放大着色器指定的栅格化顺序,此环形缓冲区中的条目按照线程组启动的顺序分配给放大着色器线程组。如果一个调度包含的放大着色器线程组多于环形缓冲区中的条目,则当环形缓冲区中的条目可用时,命令处理器会为剩余的线程组发出辅助放大着色器调度。这些辅助调度在 RGP 中显示为 Dispatch(0, 0, 0) 事件。
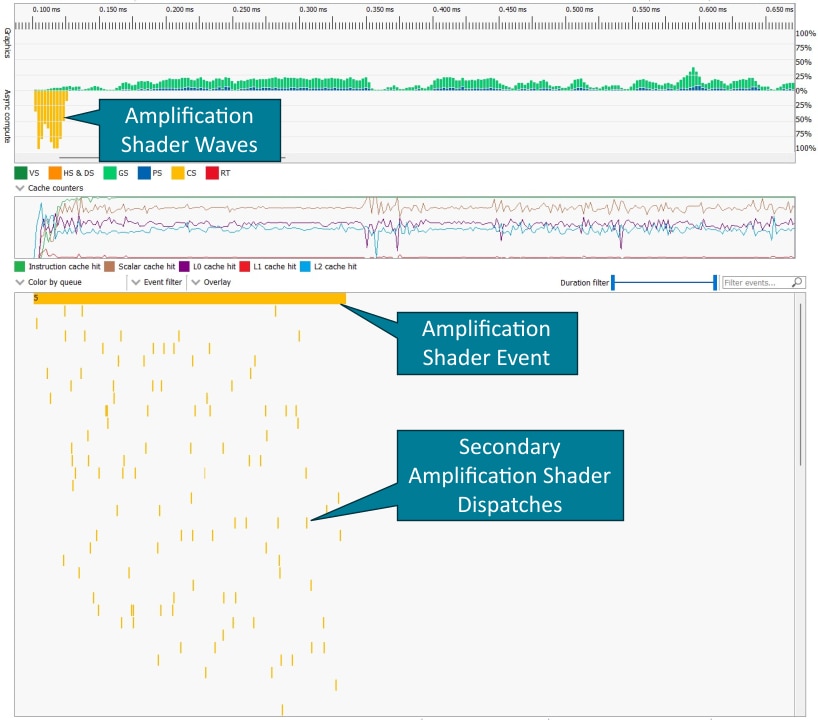
初始放大着色器调度(事件 5)涵盖了所有放大着色器调度的整个持续时间。
命令处理器必须按顺序处理环形缓冲区中的条目。如果连续多个放大着色器线程组没有启动任何网格着色器线程组,则显卡可能会耗尽网格着色器工作,这可以在下面的网格着色器事件之间的间隙中看到。

在这种情况下,我们建议增加单个放大着色器线程组处理的网格单元数量。
在这篇博客文章中,我们描述了放大着色器和网格着色器开发的最佳实践以及如何对它们进行性能分析。对于网格着色器,我们提供了关于网格单元的顶点和三角形数量、网格着色器的线程组大小以及如何最好地将顶点和图元传递给光栅器的指导。此外,我们展示了网格着色器在计算上可行的内容,并提供了额外的优化指南。对于放大着色器,我们提供了关于线程组大小以及如何有效地将数据传递给由放大着色器启动的网格着色器的建议。
最后,我们演示了如何使用 Radeon™ GPU Profiler 对放大着色器和网格着色器进行性能分析。
第三方网站链接仅为方便用户提供,除非另有明确说明,AMD不对任何此类链接网站的内容负责,且不暗示任何认可。GD-98
Microsoft 是 Microsoft Corporation 在美国和/或其他国家/地区的注册商标。本出版物中使用的其他产品名称仅用于标识目的,并可能为其各自所有者的商标。
DirectX 是 Microsoft Corporation 在美国和/或其他国家/地区的注册商标。
使用作为 zeux 的 meshoptimizer 的一部分提供的网格单元生成器。 ↩