
AMD FidelityFX™ Variable Shading
AMD FidelityFX Variable Shading 将可变速率着色引入您的游戏。
我们继续进行 Mesh Shader 用例研究,重点关注 Meshlet 压缩。
详细来说,我们希望展示如何减少 Meshlet 几何的内存占用,从而减小索引缓冲区和顶点属性的内存占用。解压则发生在每一帧的 Mesh Shader 中。
该项目可以追溯到 2010 年,当时 Quirin,本文作者之一,为他的 博士论文 并行地在 GPU 上解压通用三角形带 (GTS)(另见相关的 论文 和 演讲)。该算法与 Epic Games 在 2021 年随 Nanite 引入的 GTS 解压算法相似。然而,在 2010 年,如今的计算着色器尚不存在。计算管线是独立的 API,因此图形和计算之间的切换非常昂贵,并且会减慢整体渲染时间。
Mesh Shader 的引入使得图形和计算的集成更加紧密。因此,Quirin 和他在 Coburg 应用技术大学 的一些学生于 2020 年开始从事与 Mesh Shader 解压相关的各种项目。当来自慕尼黑的 AMD 人员加入后,一个项目获得了极大的进展,也促成了这个 Mesh Shader 博客文章系列的创建。在我们最新的论文 《走向实用的 Meshlet 压缩》 中,我们展示了如何将这些压缩技术与 Mesh Shader 相结合,从而提高渲染性能并降低内存消耗。在这篇博客文章中,我们想更深入地探讨该论文中的一些技术细节,论文的链接为 此处。

通过摄影测量等扫描技术创建的网格在实时应用中越来越普遍。为了处理大量的几何数据,Unreal Engine 引入了 Nanite。Nanite 表明,如今可以流式传输海量几何数据,甚至可以达到三角形小于像素的程度。为了处理如此大量的数据,Nanite 的一个关键要素是几何压缩。虽然通常解压算法是线性的,但在图形卡上运行良好,解压必须并行化。在我们撰写本文时,Nanite 的开发者对 GPU 解压性能并不满意,因此他们只在从 CPU 流式传输后运行一次,而不是像最初设想的那样每帧执行一次(参见 2021 年 Nanite 演示文稿)。
接下来,我们将展示一种与 Nanite 编码非常相似的方法,该方法经过优化,可以直接在 Mesh Shader 中使用。随后,我们将讨论基于放大着色器的 Meshlet 剔除,因为它也符合渲染预定义几何体的主题。
在实时图形中,网格通常由三角形组成。每个三角形包含三个指向顶点属性的索引。索引缓冲区
表示三角形网格的连接性。通常,GPU 将 解释为三角形列表,其中 中的索引三元组构成三角形
或者在具体的例子中

然而,每个三角形有三个索引,它们的存储要求相对较高。
一种内存占用较少的方式来解释 是三角形带,其中一个三角形复用了前一个三角形的边
请注意,我们颠倒了每第二个三角形的顶点顺序,以保持其缠绕顺序不变。现在,条带中的每个三角形只需要一个新索引,第一个三角形除外。因此,使用条带可实现 3:1 的压缩率。
三角形条带描述了网格三角形的路径。前面的例子是一个“交替”三角形条带,其中条带在复用前一个三角形的右边缘和左边缘之间交替。由于这种方式不够灵活,我们可以为每个三角形引入另一个位标志,用于编码复用的哪个边缘,我们称之为“L/R 标志”。这被称为“通用”三角形条带或“GTS”,也是我们用于网格片的结构。我们之前的例子可以编码为 GTS,如下所示。

请注意,我们还对网格片的顶点进行了排序,使其在条带中按递增顺序出现。这样,第一个索引 是强制性的,我们不需要存储它们。
要完全表示一个网格,或者在这种情况下表示一个网格片,通常需要多个条带。为了将多个条带描述为一个条带,我们需要一种编码“条带重启”的方法。这可以通过为每个三角形添加另一个重启位来完成,或者通过有意地在条带中添加“退化三角形”来完成。
退化三角形有两个或更多个相同的顶点索引,因此其面积为零。由于它们不会改变渲染图像的结果,GPU 的光栅化器可以忽略它们。例如,交替条带的索引缓冲区
重复的顶点 产生了四个退化三角形
正如您所见,我们成功地在一个三角形 结束了一个条带,并以三角形 开始了新的条带。使用退化三角形而不是位标志的好处是,在解压缩阶段不需要额外的逻辑。光栅化器将忽略所有退化三角形。
在 GTS 中编码网格片时,当需要重启时,三角形的数量会增加。因此,在极少数情况下,三角形的数量可能会超过 256 个的限制。在这种情况下,我们选择将网格片拆分为两个。
在网格片中找到仅需要少量重启的良好条带是一个非平凡的问题。为了在运行时间和质量之间取得良好的权衡,我们建议使用增强的隧道算法。在我们题为“Towards Practical Meshlet Decompression”的论文中,我们描述了一种最优算法,但计算它需要一些时间。
正如前一节所述,每个三角形的 L/R 标志表示复用了前一个三角形的哪个边缘。由于所有三角形都是并行解压缩的,一个线程无法访问解压缩的前一个三角形。相反,每个单独的线程必须从条带的更早位置找到正确的索引。请参阅下图作为参考:条带在顶点周围以扇形方式旋转得越长,所需的索引就越靠前。

为了确切知道我们必须回溯到条带的哪个位置,我们从 1 开始计数,直到标志发生变化,需要回溯多少步 L/R 位掩码。在我们的例子中,三角形 7 需要三角形 4 的索引,即 0。为了以线性时间进行此搜索,我们可以在 hlsl 中使用 firstbithigh(或 firstbitlow)位操作,或在 glsl 中使用 findMSB(或 findLSB)。请注意,位掩码必须相应地进行移位和反转。
这可以在 hlsl 中实现,如下所示
uint LoadTriangleFanOffset(in int triangleIndex, in bool triangleFlag){ uint lastFlags; int fanOffset = 1; do { // Load last 32 L/R-flags lastFlags = LoadLast32TriangleFlags(triangleIndex); // Flip L/R-flags, such that // 0 = same L/R flag // 1 = different L/R flags, i.e. end of triangle fan lastFlags = triangleFlag ? ~lastFlags : lastFlags; // 31 - firstbithigh counts leading 0 bits, i.e. length of triangle fan fanOffset += 31 - firstbithigh(lastFlags); // Move to next 32 L/R flags triangleIndex -= 32; } // Continue util // - lastFlags contains different L/R flag (end of triangle fan) // - start of triangle strip was reached (triangleIndex < 0) while ((lastFlags == 0) && (triangleIndex >= 0));
return fanOffset;}我们必须在这里使用一个循环,因为扇形配置可能比 32 个三角形长。在大多数情况下,此循环只会运行一次。在最坏的情况下,整个条带实际上是一个扇形,因此循环将运行 次(,因为这是网格着色器可以输出的最大三角形数量,而 ,因为我们将每个三角形的一个位存储在一个 32 位字中)。在循环内部,我们加载 L/R 位,使得最高有效位是当前三角形的标志,次高有效位是前一个三角形的形式,依此类推。
// 256/32 = 8 dwords for flags and 256 / 4 = 64 dwords for 8 bit indicesgroupshared uint IndexBufferCache[8 + 64];
uint LoadLast32TriangleFlags(in int triangleIndex){ // Index of DWORD which contains L/R flag for triangleIndex int dwordIndex = triangleIndex / 32; // Bit index of L/R flag in DWORD int bitIndex = triangleIndex % 32;
// Shift triangle L/R flags such that lastFlags only contains flag prior to triangleIndex uint lastFlags = IndexBufferCache[dwordIndex] << (31 - bitIndex);
if (dwordIndex != 0 && bitIndex != 31) { // Fill remaining bits with previous L/R flag DWORD lastFlags |= IndexBufferCache[dwordIndex - 1] >> (bitIndex + 1); }
return lastFlags;}正如您在此处看到的,我们正在执行本系列前面帖子中推荐的操作:利用组共享内存。具体来说,而不是每个线程都有整个压缩条带的副本,或者多次从全局内存加载该数据,我们一次性加载数据并将其缓存到组共享内存中。这提高了运行时间性能。
最后,整个三角形的加载如下
uint3 LoadTriangle(in int triangleIndex){ // Triangle strip L/R flag for current triangle const bool triangleFlag = LoadTriangleFlag(triangleIndex);
// Offset in triangle fan const uint triangleFanOffset = LoadTriangleFanOffset(triangleIndex, triangleFlag);
// New vertex index uint i = LoadTriangleIndex(triangleIndex); // Previous vertex index uint p = LoadTriangleIndex(triangleIndex - 1); // Triangle fan offset vertex index uint o = LoadTriangleIndex(triangleIndex - triangleFanOffset);
// Left triangle // i ----- p // \ t / \ // \ / \ // \ / t-1 \ // o ----- * // // Right triangle // p ----- i // / \ t / // / \ / // / t-1 \ / // *------ o
return triangleFlag ? // Right triangle uint3(p, o, i) : // Left triangle uint3(o, p, i);}您现在可能已经注意到,我们的条带中的许多索引只是前一个索引的增量。为了利用这种冗余,我们可以通过我们称之为“复用打包”的概念来扩展我们的编解码器。我们不存储实际索引,而只存储一个索引是否是递增的(1)还是复用的索引(0)。我们称之为“inc-flag 缓冲区”。一个附加的索引缓冲区,称为“复用缓冲区”,仅存储所有复用索引。如果一个线程用 1 作为递增标志来解包第 个三角形,则结果索引只是所有前驱 inc-flags 的总和。否则,如果 inc-flag 是 0,则在位置 访问复用缓冲区。

为了对 inc-flags 进行累加扫描,我们可以再次利用一个名为 countbits 或 bitcount 的位指令。
由于这只会给出 32 位字中所有标志的总和,因此我们再次利用组共享内存来预先计算和缓存每个 32 位字开头的累加和的结果。
groupshared uint IncrementPrefixCache[7];
uint LoadTriangleIncrementPrefix(in int triangleIndex){ // Index of DWORD which contains L/R flag for triangleIndex const uint dwordIndex = triangleIndex / 32; // Bit index of L/R flag in DWORD const uint bitIndex = triangleIndex % 32;
// Count active bits (i.e. increments) in all prior triangles const uint prefix = countbits( IndexBufferCache[TRIANGLE_INCREMENT_FLAG_OFFSET + dwordIndex] << (31 - bitIndex));
if (dwordIndex >= 1) { // IncrementPrefixCache stores prefix sum of all prior DWORDs return 2 + prefix + IncrementPrefixCache[dwordIndex - 1]; } else { return 2 + prefix; }}然后,索引的加载方式如下
uint LoadTriangleIndex(in int triangleIndex){ if (triangleIndex <= 0) { return max(triangleIndex + 2, 0); } else { const bool increment = LoadTriangleIncrementFlag(triangleIndex); const uint prefix = LoadTriangleIncrementPrefix(triangleIndex);
if (increment) { return prefix; } else { const uint index = triangleIndex + 1 - prefix;
const uint dwordIndex = index / 4; const uint byteIndex = index % 4;
const uint value = IndexBufferCache[TRIANGLE_INDEX_OFFSET + dwordIndex];
// Extract 8 bit vertex index return (value >> (byteIndex * 8)) & 0xFF; } }}至此,索引缓冲区压缩完成。在下一节中,我们将讨论属性压缩。
顶点属性压缩是基于顶点着色器的管道中广泛采用的技术。除了简单的量化,还有专门的技术可以利用特定属性类型的独特可压缩性。例如,一个三分量法向量本质上代表了球体上的一个点。一种编码此类法向量的流行方法是通过八面体映射,如这项研究和Quirin 的论文(如果您想深入研究)中所述。此外,研究表明,网格绑定常用的四种混合权重通常被限制在一个小四面体内。
虽然顶点着色器通常单独解压缩每个顶点,但在网格片中使用属性压缩具有显著优势:能够集体压缩和解压缩一组相似的顶点。这是可能的,因为同一网格片内的属性倾向于相似。
为了说明这个概念,我们以顶点位置为例:网格中所有顶点的位置都包含在其轴对齐边界框(AABB)内。通常,网格片的 AABB 体积小于全局 AABB。这允许我们对网格片较小的局部 AABB 内的位置进行量化,然后应用一个偏移量来确定网格全局位置。这个偏移量就是网格片元数据信息的一部分。
此方法有效地利用了组内的位置相干性。然而,它引入了一个问题:重复的顶点被量化到每个所属网格片的が不同的网格上,导致反量化值不同。结果,渲染的网格出现裂缝!

为了解决这个问题,我们可以定义一个全局量化网格,并由局部量化采用。为了计算这个全局量化网格,我们首先需要找到沿单个轴的最大网格片边界框。在此示例中,我们仅量化顶点位置的 轴分量,但同样的逻辑可以应用于任何一组浮点值。
// Our mesh already contains the geometry as meshlets.// Each meshlet contains its own set of vertices that are not shared with any other meshlet.const auto& mesh = ...;
// Target precision for storing quantized values.// All meshlet will require at most 16 bits to store the quantized information.const auto targetBits = 16;
// Here we show quantization of the x-axis// The same process has to be applied to all other axes, including other floating-point attributes,// such as normals or texture coordinatesconst float globalMin = mesh.GetAABB().min.x;const float globalDelta = mesh.GetAABB().max.x - globalMin;
// First we find the largest meshlet along the x-axisfloat largestMeshletDelta = 0.f;
for (const auto& meshlet : mesh.GetMeshlets()) { const float meshletDelta = meshlet.GetAABB().max.x - meshlet.GetAABB().min.x;
largestMeshletDelta = std::max(largestMeshletDelta, meshletDelta);}有了边界框,或者更准确地说,是最大网格片的外包围盒,我们可以计算网格片局部网格上两个量化值之间的间隔,从而也计算出网格全局量化网格。
// Next we compute the local quantization spacing between two quantized values// when quantizing the largest meshlet to targetBits.const float meshletQuantizationStep = largestMeshletDelta / ((1 << targetBits) - 1);// This spacing will then be used to compute the number of quantized values in the global quantization grid.const std::uint32_t globalQuantizationStates = globalDelta / meshletQuantizationStep;
// Effective bit precision of quantized values.// If largestMeshletDelta is smaller than globalDelta, then this precision will be greater than targetBits.const float effectiveBits = std::log2(globalQuantizationStates);
// Global factors for en/decoding quantized valuesconst float quantizationFactor = (globalQuantizationStates - 1) / globalDelta;// Explicit computation of dequantization factor is more precise than 1 / quantizationFactorconst float dequantizationFactor = globalDelta / (globalQuantizationStates - 1);根据网格边界框与最大网格片边界框的比例,网格全局量化网格的有效精度可以大于最初的 16 位目标。例如,预告片图像中的*岩石*网格的 轴的有效精度为 位。
接下来,我们可以使用我们之前计算的 quantizationFactor 来编码所有顶点位置。为了确保无裂缝的反量化,我们采用了以下技巧:我们首先计算网格全局量化网格上的网格片偏移量。然后,我们可以将顶点位置量化到网格全局量化网格。接下来,我们减去这个量化的网格片偏移量,以确保我们的量化值不超过 位值范围。此网格全局与网格片局部量化网格之间的转换可以轻松反转,而不会引入任何浮点误差。
// Encode all x-axis positions for all meshletsfor (const auto& meshlet : mesh.GetMeshlets()) { // The quantized meshlet offset maps mesh-global quantized values onto // meshlet-local quantization grid const std::uint32_t quantizedMeshletOffset = static_cast<std::uint32_t>( (meshlet.GetAABB().min.x - globalMin) * quantizationFactor + 0.5f);
for (const auto& vertex : meshlet.GetVertices()) { // Encode x-axis value, repeat for all other values const float value = vertex.x;
// First quantize value on global grid const std::uint32_t globalQuantizedValue = static_cast<std::uint32_t>( (value - globalMin) * quantizationFactor + 0.5f); // Then move quantized value to local grid to keep within [0, (1 << targetBits) - 1] range const std::uint32_t localQuantizedValue = globalQuantizedValue - quantizedMeshletOffset;
// Store local quantized value ... }
// Store quantizedMeshletOffset per axis for each meshlet ...}
// Store dequantizationFactor & globalMin per axis for dequantization...为了在网格着色器中反量化值,我们需要传递 dequantizationFactor、globalMin 以及(每个网格片)quantizedMeshletOffset。使用这些值,顶点位置可以按如下方式反量化
const float value = (quantizedMeshletOffset + localQuantizedValue) * dequantizationFactor + globalMin;在本节中,我们在放大器着色器中执行网格片剔除,以优化我们的渲染器。
当我们向管道添加放大器着色器时,DispatchMesh 会从启动网格着色器线程组变为启动放大器着色器线程组。在下面的代码示例中,我们加载与当前网格片相关的剔除信息,并计算网格片是否可见。请注意,我们如何使用 WavePrefixCountBits 为线程组中的可见网格片分配新索引。之后,WaveActiveCountBits 返回组中可见网格片的总数,这对于调用 DispatchMesh 是必需的。在我们的自定义载荷中,我们指定要在网格着色器中使用的实例和网格片 ID。
struct Payload { uint2 meshletData[32];};
groupshared Payload payload;
[NumThreads(32, 1, 1)]void AmplificationShader(uint2 dtid : SV_DispatchThreadID){ // Amplification is dispatched with DispatchMesh((meshletCount + 31) / 32, instanceCount, 1); const uint meshletId = dtid.x; const uint instance = dtid.y;
bool visible = false;
if (instance < RootConst.instanceCount) { visible = IsMeshletVisible(Meshlets[meshletId], instance); }
if (visible) { const uint index = WavePrefixCountBits(visible); payload.meshletData[index] = uint2(meshletId, instance); }
const uint meshletCount = WaveActiveCountBits(visible); DispatchMesh(meshletCount, 1, 1, payload);}视锥体剔除通过为每个网格片创建一个边界体积来工作——一个完全包围网格片几何体的简单形状。然后,网格片的边界体积会与定义相机视锥体的六个平面进行测试。如果边界体积与视锥体不相交,则认为该网格片位于相机视图之外,并被剔除,这意味着它不会被发送到网格着色器。
类似于逐三角形的硬件加速背面剔除,可以检查网格片的所有三角形是否背离了相机。为此,需要一个能够包含网格片内所有面法向量的边界体积。对于此体积,一个实际的选择是锥体,由中心法向量和开口角度定义。该锥体表示网格片面可以朝向的方向范围。虽然在大多数情况下近似此锥体效果良好,但找到最优锥体与找到*最小点集圆*是同一个问题。
在本节中,我们讨论了我们的压缩技术的成果。我们的基线网格着色管道,未经压缩,使用 8 位索引和原始顶点属性。
我们首先比较顶点管道的索引和顶点缓冲区的大小与不同网格着色管道组合的大小。网格着色管道的数据大小包括带有网格片边界处重复顶点的顶点缓冲区,以及局部索引缓冲区和用于存储网格片元数据的偏移量缓冲区。
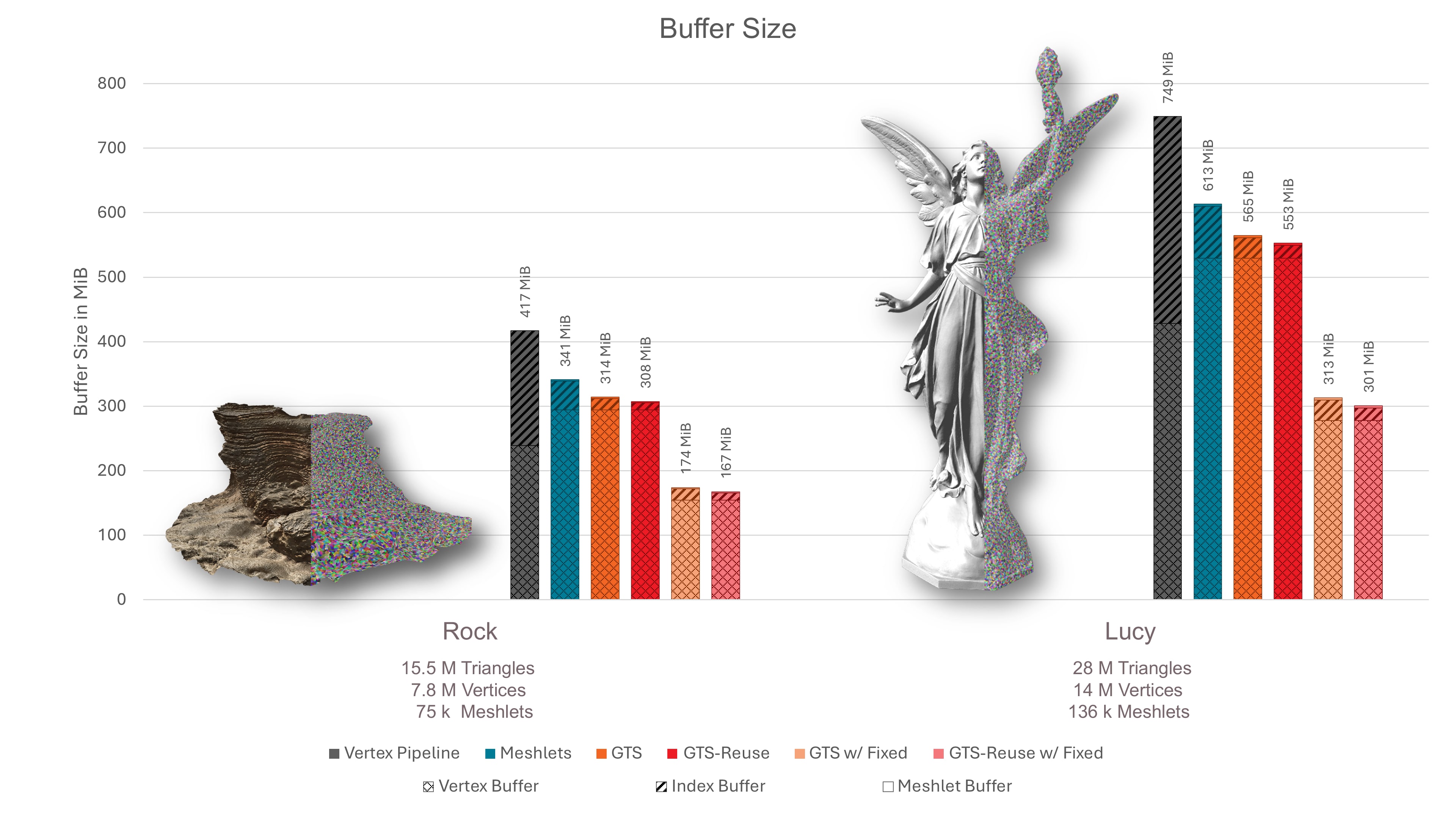
正如您所见,使用基线网格着色器已经实现了与顶点管道相比的压缩,因为从 32 位减少到 8 位索引所带来的好处超过了所需的属性复制。通过将三角形进一步打包到通用三角形条带中,索引与基线网格片的压缩比为,或与顶点管道相比为。因此,压缩后,索引缓冲区相对于量化顶点缓冲区的大小来说可以忽略不计。请注意,我们使用了非常保守的顶点属性量化。在不影响视觉质量的情况下,仍然可以实现更高的顶点属性压缩比。
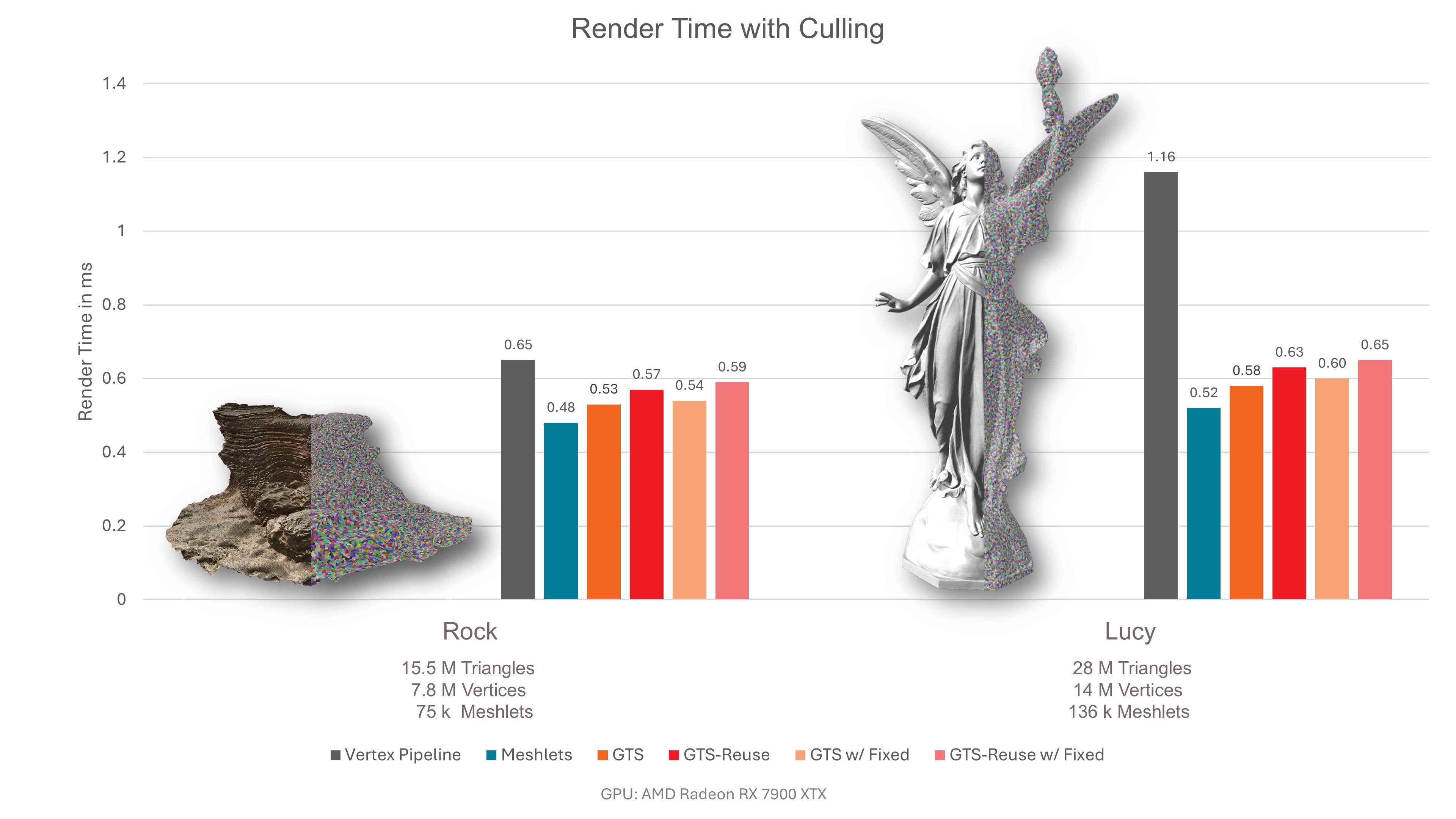
下图显示了我们的绝对渲染性能测量。为了强调几何阶段的性能影响,我们的 Direct3D12 实现使用 Phong 着色器渲染到 500x500 像素的帧缓冲区。请注意,通过增加更复杂的着色,几何阶段对总渲染时间的影响会降低。正如预期的那样,渲染时间随网格大小线性增长。可以看出,我们的基线网格着色器管道的性能优于顶点管道。

当向基线添加解压缩时,性能通常会下降。对于“毛球”网格,情况不一定如此,因为该网格受像素过绘制的限制。
下图是相同的测量结果,但启用了锥体剔除。由于平均而言,每第二个网格片都背离相机,因此性能最多可提高一倍。然而,这不适用于我们的岩石网格,因为几乎所有网格片都朝向相机。
我们希望这个案例研究能为您提供一些关于如何利用基于网格着色器的几何管道来减少应用程序内存占用的灵感。同时,网格着色器在速度方面也能优于顶点管道。这是双赢:速度提高,内存减少。
我们非常荣幸在 GCPR VMV 2024 上因我们的论文 “Towards Practical Meshlet Compression” 而荣获最佳论文奖。
第三方网站链接仅为方便用户提供,除非另有明确说明,AMD不对任何此类链接网站的内容负责,且不暗示任何认可。GD-98
Microsoft 是 Microsoft Corporation 在美国和/或其他国家/地区的注册商标。本出版物中使用的其他产品名称仅用于标识目的,并可能为其各自所有者的商标。
DirectX 是 Microsoft Corporation 在美国和/或其他国家/地区的注册商标。



















