许多科学应用程序运行在配备 AMD GPU 的计算平台和超级计算机上,包括世界上首个 E 级系统 Frontier。这些来自众多科学领域的应用程序,通过异构计算接口(HIP)抽象层移植到 AMD GPU 上运行。HIP 使这些高性能计算(HPC)设施能够迁移其遗留的 CUDA 代码,并在最新的 AMD GPU 上运行并利用其优势。移植这些科学应用程序的所需工作量从几个小时到几周不等,很大程度上取决于原始源代码的复杂性。图 1 展示了几个已移植应用程序的示例以及相应的移植工作量。
在本文中,我们将介绍 HIP 可移植性层、AMD ROCm™ 堆栈中可用于自动转换 CUDA 代码为 HIP 的工具,以及如何通过可移植的 HIP 构建系统在 AMD 和 NVIDIA GPU 上运行相同的代码。
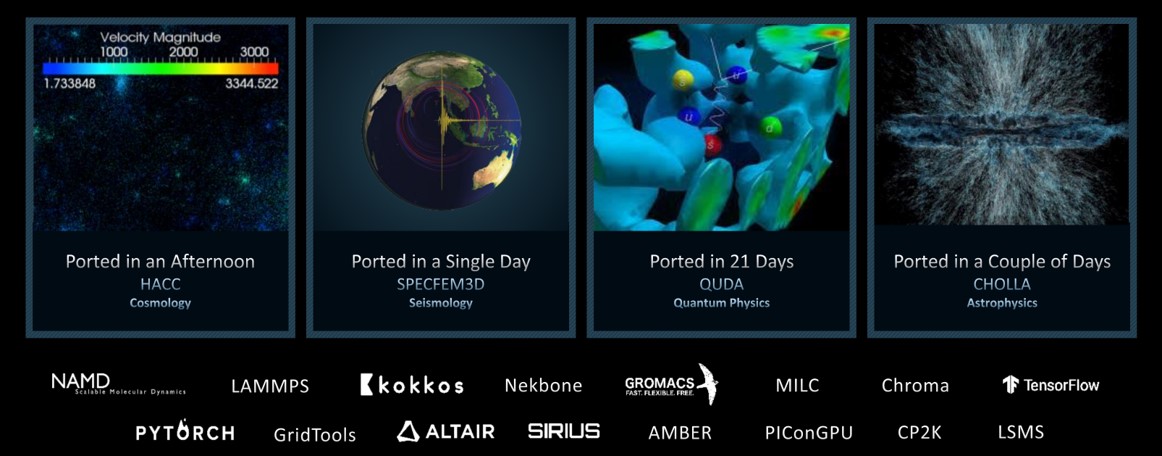
图 1:将科学应用程序移植以支持 AMD Instinct™ GPU 及 HIP
HIP API
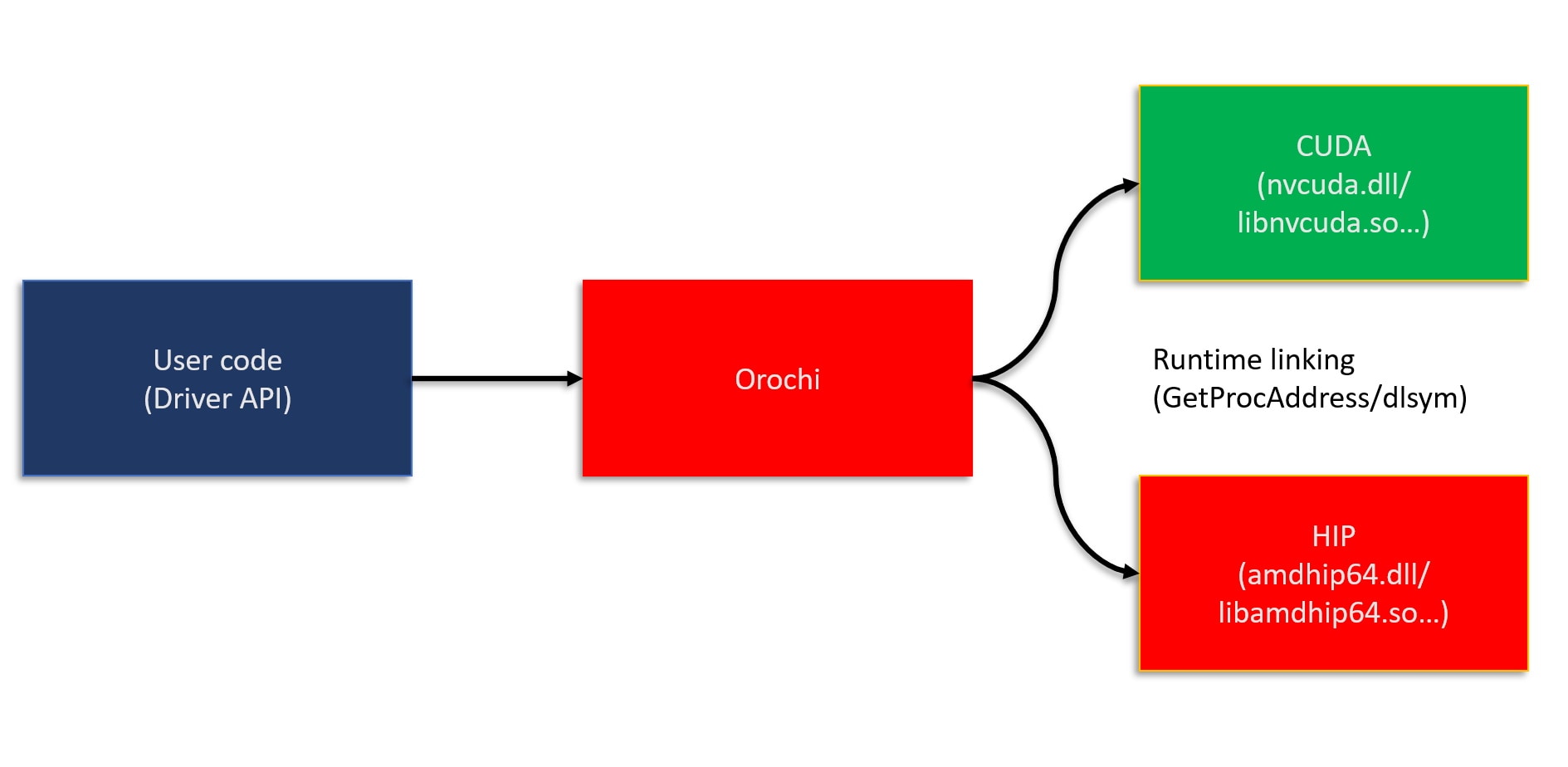
异构计算接口(HIP)是一个 C++ 运行时 API 和内核语言,它使开发人员能够设计可在 AMD 和 NVIDIA GPU 上运行的平台无关的 GPU 程序。HIP 接口和语法与 CUDA 非常相似,这有助于 GPU 程序员采用它,并能快速转换 CUDA API 调用。大多数此类调用可以通过简单地将 cuda 替换为 hip 来就地转换,因为 HIP 支持 CUDA 运行时功能的一个强大子集。此外,如图 2 所示,HIP 代码通过维护一个单一的代码库,即可在 AMD 和 NVIDIA 平台上运行,从而简化了维护工作。

图 2:HIP 到设备流程图,说明了平台无关的抽象层。
图 3 展示了可用于加速 GPU 代码的各种编程范例和工具,以及系统堆栈中的相应抽象级别。HIP 比其他 GPU 编程抽象层更接近硬件,因此能够以最小的开销加速代码。这一特性使得 HIP 代码在 NVIDIA 加速器上的运行性能与原始 CUDA 代码相似。此外,AMD 和 NVIDIA 都共享主机-设备架构,其中 CPU 是主机,GPU 是设备。主机支持 C++、C、Fortran 和 Python。C++ 是最常用且支持最好的语言,入口点是 main() 函数。主机运行 HIP API 和 HIP 函数调用,这些调用会映射到 CUDA 或 HIP。内核在设备上运行,该设备支持类 C 语法。最后,HIP API 提供了许多用于设备和内存管理以及错误处理的有用函数。HIP 是开源的,您可以对其做出贡献。
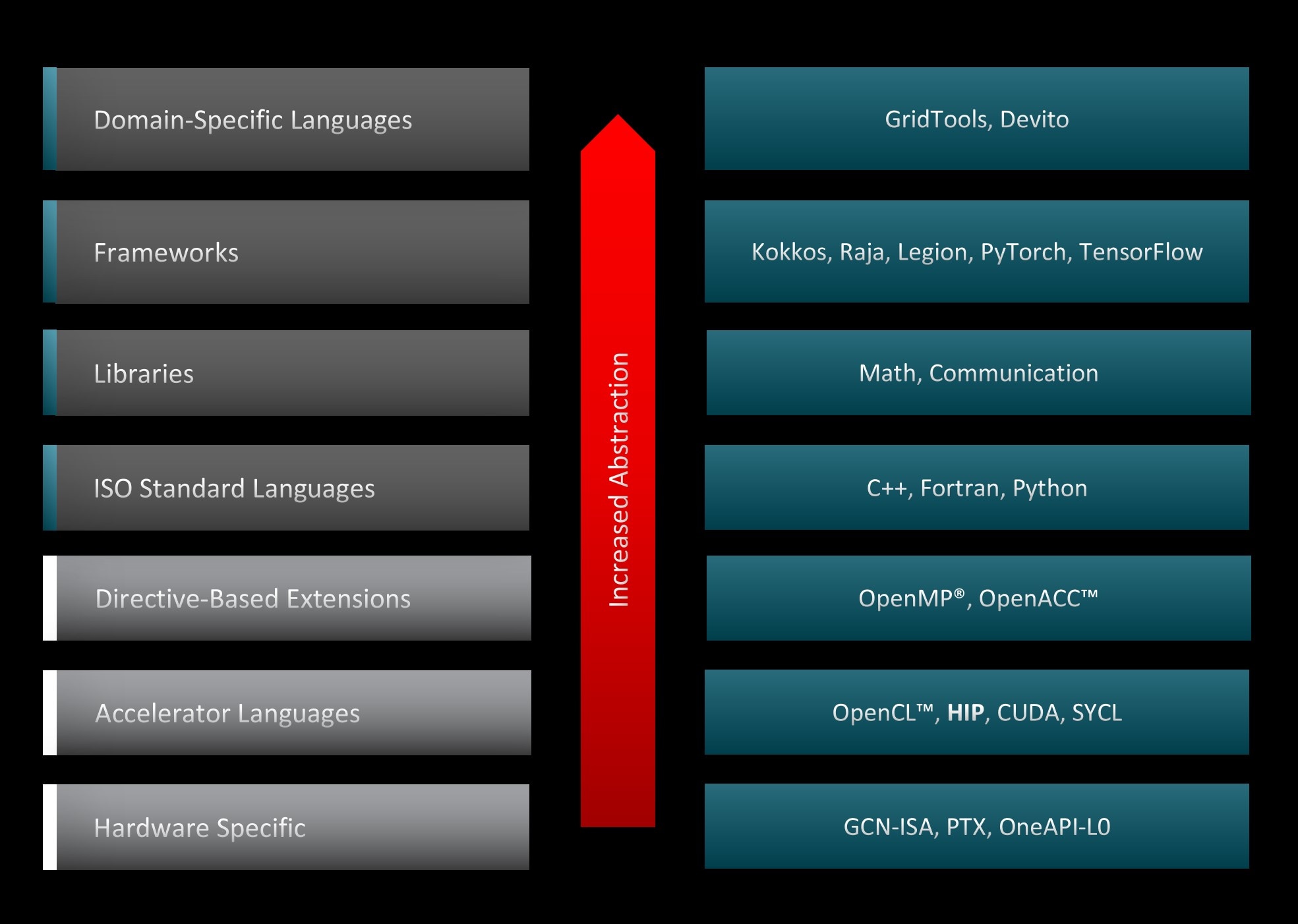
图 3:GPU 编程抽象级别。
将 CUDA 应用程序转换为 HIP
手动将大型复杂的现有 CUDA 代码项目转换为 HIP 是一个容易出错且耗时的过程。鉴于 HIP 和 CUDA 之间的语法相似性,可以构建自动转换工具来将 CUDA 代码转换为可移植的 HIP C++。AMD ROCm™ 堆栈提供了转换实用程序和脚本,可显著加快此过程。这些实用程序可以单独使用,也可以作为迭代过程的一部分来移植更大、更复杂的 CUDA 应用程序,从而减少手动工作量和 CUDA 应用程序在 AMD 系统上部署的时间。
使用哪些工具?
最终选择何种工具或策略来转换遗留的 CUDA 代码到 HIP 取决于多种因素,包括代码的复杂性以及开发者的设计选择。为了阐明这一点,我们鼓励开发者使用以下问卷作为模板,以收集有关其项目的更多信息
-
代码结构的复杂程度?
-
是否使用面向对象编程?
-
是否依赖模板类?
-
对其他库和包的依赖?
-
是否有特定于设备的 कोड?
-
-
设计考虑因素?
- 是否应为 CUDA 和 HIP 维护单独的后端?
-
代码库是否处于活跃开发中?
-
更新频率如何?
-
开发工作是否专注于特定功能?
-
完成需求和目标评估后,开发者可以选择以下策略之一来将 CUDA 代码转换为 HIP。
统一的包装器/头文件
在不希望维护单独的 CUDA 和 HIP 代码存储库,并且应用程序没有任何设备特定代码的情况下,可以创建一个带有宏定义的头文件,该文件为 HIP API 调用创建别名,并将其链接到现有的 CUDA API。请参考以下片段作为示例
...#define cudaFree hipFree#define cudaFreeArray hipFreeArray#define cudaFreeHost hipHostFree#define cudaMalloc hipMalloc#define cudaMallocArray hipMallocArray#define cudaMallocHost hipHostMalloc#define cudaMallocManaged hipMallocManaged#define cudaMemcpy hipMemcpy...这是一个您可以用作移植项目起点的头文件。
或者,也可以使用宏定义来构建一个统一的包装器,如下面的代码片段所示。根据代码编译的目标架构,包装器框架会在后台调用相应的 CUDA 或 HIP API。
...#ifdef _CUDA_ENABLED using deviceStream_t = cudaStream_t;#elif _HIP_ENABLED using deviceStream_t = hipStream_t;#endif...</code>| 优点 | 缺点 |
|---|---|
| 易于维护 | 链接所有 CUDA API 可能需要多次迭代 |
| 高度可移植 | CUDA 中的现有优化可能不适用于 HIP |
| 轻松添加新功能 | 当 CUDA API 没有 HIP 等效项时需要手动干预 |
通用技巧
-
在 NVIDIA GPU 上开始移植通常是最简单的方法,因为您可以逐步将代码块移植到 HIP,同时将其余部分保留在 CUDA 中。请记住,在 NVIDIA GPU 上,HIP 只是 CUDA 的一个薄层,因此在 nvcc 平台上,这两种代码类型可以互操作。此外,HIP 移植可以与原始 CUDA 代码在功能和性能上进行比较。
-
一旦 CUDA 代码被移植到 HIP 并在 NVIDIA GPU 上运行,就可以使用 HIP 编译器在 AMD GPU 上编译 HIP 代码。
Hipify 工具
AMD 的 ROCm™ 软件堆栈包含一些工具,可以帮助将 CUDA API 转换为 HIP API。以下两种工具可以找到
-
hipify-clang:一个预处理器,它在 HIP/Clang 编译器工具链中运行,在编译过程的初步阶段进行代码转换。
-
hipify-perl:一个基于 Perl 的脚本,它依赖于正则表达式进行转换。
hipify 工具可以扫描代码以识别任何不支持的 CUDA 函数。支持的 CUDA API 列表可在 ROCm 的 HIPIFY 文档网站上找到。
Hipify-clang
hipify-clang 是一个预处理器,它使用 Clang 编译器来解析 CUDA 代码并执行语义转换。它将 CUDA 源转换为抽象语法树,然后由转换匹配器遍历。应用所有匹配器后,会生成输出的 HIP 源。
| 优点 | 缺点 |
|---|---|
基于 Clang 的翻译器,因此即使是复杂的构造也能成功解析 | 输入的 CUDA 代码应该是正确的,不正确的代码将无法转换为 HIP |
支持 Clang 选项,如 | 在这种情况下,CUDA 应该已安装,并且如果存在多个安装,应通过 |
无缝支持新的 CUDA 版本,因为这是 Clang 的责任 | 所有包含和定义都应提供,以成功转换代码 |
hipify-clang 的一般用法如下
hipify-clang [options] <source0> [... <sourceN>]其中,可通过使用以下命令识别可用选项
hipify-clang --help考虑一个简单的 vectorAdd 示例,原始 CUDA 代码接收两个向量 A 和 B,执行逐元素加法并将结果存储在新的向量 C 中。
C[i] = A[i] + B[i], where i=0,1,.....,N-1要将 CUDA 代码转换为 HIP,可以使用 hipify-clang 如下
hipify-clang --cuda-path=/your-path/to/cuda -I /your-path/to/cuda/include -o /your-path/to/desired-output-dir/vectorAdd_hip.cpp vectorAdd.cu转换后的 HIP 代码 vectorAdd_hip.cpp 如下所示
#include <hip/hip_runtime.h>#include <stdio.h>
// Macro for checking errors in CUDA API calls#define cudaErrorCheck(call) \do{ \ hipError_t cuErr = call; \ if(hipSuccess != cuErr){ \ printf("CUDA Error - %s:%d: '%s'\n", __FILE__, __LINE__, hipGetErrorString(cuErr));\ exit(0); \ } \}while(0)
// Size of array#define N 1048576
// Kernel__global__ void add_vectors_cuda(double *a, double *b, double *c){ int id = blockDim.x * blockIdx.x + threadIdx.x; if(id < N) c[id] = a[id] + b[id];}
// Main programint main(){ // Number of bytes to allocate for N doubles size_t bytes = N*sizeof(double);
// Allocate memory for arrays A, B, and C on host double *A = (double*)malloc(bytes); double *B = (double*)malloc(bytes); double *C = (double*)malloc(bytes);
// Allocate memory for arrays d_A, d_B, and d_C on device double *d_A, *d_B, *d_C; cudaErrorCheck( hipMalloc(&d_A, bytes) ); cudaErrorCheck( hipMalloc(&d_B, bytes) ); cudaErrorCheck( hipMalloc(&d_C, bytes) ); ...快速查看转换后的代码会发现
-
HIP 运行时头文件已自动引入到顶部。
-
CUDA 类型和 API,如
cudaError_t、cudaMalloc等,已被替换为 HIP 对应的 API。 -
用户定义、函数名和变量保持不变。
-
从 ROCm 5.3 开始,默认的 HIP 内核启动语法与 CUDA 中的相同。通过向 hipify-clang 指定
—hip-kernel-execution-syntax选项,可以继续支持并使用旧的hipLaunchKernelGGL语法。
Hipify-perl
hipify-perl 脚本使用一系列简单的字符串替换直接修改 CUDA 源代码。
| 优点 | 缺点 |
|---|---|
| 易用性 | 目前无法转换以下结构:宏展开、命名空间、某些模板、主机/设备函数调用、复杂参数列表解析 |
| 它不检查输入的源 CUDA 代码的正确性 | 可能需要多次迭代以及手动干预 |
| 它不依赖于第三方工具,包括 CUDA | 没有编译器支持来检查包含和定义是否存在 |
hipify-perl 的一般用法如下
hipify-perl [OPTIONS] INPUT_FILE其中,可通过使用以下命令识别可用选项
hipify-perl --help使用相同的 vectorAdd 示例,我们可以使用 hipify-perl 将 CUDA 代码转换为 HIP,如下所示
$ hipify-perl -o=your-path/to/desired-output-dir/vectorAdd_hip.cpp vectorAdd.cu warning: vectorAdd.cu:#4 : #define cudaErrorCheck(call) \ warning: vectorAdd.cu:#36 : cudaErrorCheck( hipMalloc(&d_A, bytes) ); warning: vectorAdd.cu:#37 : cudaErrorCheck( hipMalloc(&d_B, bytes) ); warning: vectorAdd.cu:#38 : cudaErrorCheck( hipMalloc(&d_C, bytes) ); warning: vectorAdd.cu:#49 : cudaErrorCheck( hipMemcpy(d_A, A, bytes, hipMemcpyHostToDevice) ); warning: vectorAdd.cu:#50 : cudaErrorCheck( hipMemcpy(d_B, B, bytes, hipMemcpyHostToDevice) ); warning: vectorAdd.cu:#71 : cudaErrorCheck( hipMemcpy(C, d_C, bytes, hipMemcpyDeviceToHost) ); warning: vectorAdd.cu:#90 : cudaErrorCheck( hipFree(d_A) ); warning: vectorAdd.cu:#91 : cudaErrorCheck( hipFree(d_B) ); warning: vectorAdd.cu:#92 : cudaErrorCheck( hipFree(d_C) );与 hipify-clang 不同,运行 hipify-perl 脚本会产生大量警告。由于 hipify-perl 使用字符串匹配和替换来翻译支持的 CUDA API 到相应的 HIP API,因此它无法找到用户定义的 cudaErrorCheck() 函数的替换项,并为找到该函数调用的每一行发出警告。快速查看指定输出目录中存储的转换代码会发现
-
hipify-perl 生成的转换代码与 hipify-clang 转换的代码相同。
-
用户定义的函数、宏和变量未更改。
-
从 ROCm v5.3 开始,默认的 HIP 内核启动语法与 CUDA 中的相同。通过向 hipify-perl 指定
—hip-kernel-execution-syntax选项,可以继续支持并使用旧的hipLaunchKernelGGL语法。
使用 Hipify 工具的通用技巧
-
hipify-perl 更易于使用,并且不依赖于 CUDA 等第三方库。
-
使用 hipify-perl 翻译代码可能需要多次迭代。第一次传递后,使用
hipcc构建代码。纠正任何编译器错误或警告,然后再次编译。继续这个循环,直到获得可用的 HIP 代码。 -
其他预打包的实用程序也可以用来帮助收集有关 CUDA 到 HIP 代码转换的信息。例如,您可以使用
-
hipexamine-perl.sh 工具扫描源目录,以确定哪些文件包含 CUDA 代码以及其中有多少代码可以自动 hipify。
-
hipconvertinplace-perl.sh 脚本对指定目录中的所有代码文件执行就地转换。
-
-
“就地”转换并不总是正确的选择,特别是如果您希望同时拥有 CUDA 和 HIP 代码。
-
hipify-perl 和 hipify-clang 翻译代码中看到的相似性可能适用于简单的示例,如这里考虑的示例。但是,hipify-perl 有已知的局限性,其使用应谨慎。
可移植的 HIP 构建系统
HIP 最强大的功能之一是,如果原始代码使用了 HIP 支持的 CUDA API,那么移植后的 HIP 代码就可以在 AMD 和 NVIDIA GPU 上运行。目前,许多面向这两个平台的应用程序都有单独的存储库以及分别为 HIP 和 CUDA 构建的系统。借助 ROCm™,我们可以拥有一个可移植的 HIP 构建系统,从而避免为同一个项目维护两个独立的代码库。
在可移植的 HIP 构建系统中,可以选择 amd 或 nvidia 平台来运行。通过设置 HIP_PLATFORM 环境变量,我们可以 选择 hipcc 目标路径。如果 HIP_PLATFORM=amd,那么 hipcc 将调用 clang 编译器和 ROCclr 运行时来为 AMD GPU 编译代码。如果 HIP_PLATFORM=nvidia,那么 hipcc 将调用 CUDA 编译器驱动程序 nvcc 来为 NVIDIA GPU 编译代码。平台选择也决定了包含哪些头文件以及链接使用哪些库。
本节将介绍如何使用两个广为人知的构建系统 Make 和 CMake 实现可移植性。
可移植的 Make 构建系统
在下面的 Makefile 示例中,我们可以通过简单地将 HIP_PLATFORM 设置为所需的默认设备 amd 或 nvidia 来选择为 AMD 或 NVIDIA GPU 进行构建。将 -x 标志设置为 cu 或 hip 将指示构建系统编译到所需的设备,而与文件扩展名无关。但是,应该注意的是,最终,这两种编译器都映射到 LLVM。
EXECUTABLE = vectoradd
all: $(EXECUTABLE) test.PHONY: test
SOURCE = vectorAdd_hip.cppCXXFLAGS = -g -O2 -fPICHIPCC_FLAGS = -O2 -gHIP_PLATFORM ?= amdHIP_PATH ?= $(shell hipconfig --path)
ifeq ($(HIP_PLATFORM), nvidia) HIPCC_FLAGS += -x cu -I${HIP_PATH}/include/ LDFLAGS = -lcudadevrt -lcudart_static -lrtendif
ifeq ($(HIP_PLATFORM), amd) HIPCC_FLAGS += -x hip LDFLAGS = -L${ROCM_PATH}/hip/lib -lamdhip64endif
$(EXECUTABLE): hipcc $(HIPCC_FLAGS) $(LDFLAGS) -o $(EXECUTABLE) $(SOURCE)test: ./$(EXECUTABLE)clean: rm -f $(EXECUTABLE)对于将在 AMD 平台上运行的代码,我们需要安装 ROCm™,并将 CXX 变量设置为推荐的 clang++,例如 export CXX=${ROCM_PATH}/llvm/bin/clang++,然后使用 make 进行构建,并运行与上一节相同的 vectorAdd 应用程序。
make./vectoradd对于将在 NVIDIA 平台上运行的代码,我们需要安装 CUDA 和 ROCm™(后者提供 HIP 可移植性层),并将 HIP_PLATFORM=nvidia 设置为覆盖默认值,转而为 NVIDIA GPU 进行编译。
HIP_PLATFORM=nvidiamake./vectoradd可移植的 CMake 构建系统
与之前的 Make 示例类似,这里的思路是拥有一个允许用户在 HIP 和 CUDA 这两种 GPU 运行时之间切换的构建系统。下面的代码展示了如何在 CMakeLists.txt 中实现切换。
...if (NOT CMAKE_GPU_RUNTIME) set(GPU_RUNTIME "HIP" CACHE STRING "Switches between HIP and CUDA")else (NOT CMAKE_GPU_RUNTIME) set(GPU_RUNTIME "${CMAKE_GPU_RUNTIME}" CACHE STRING "Switches between HIP and CUDA")endif (NOT CMAKE_GPU_RUNTIME)接下来,要在 AMD 和 NVIDIA 系统上构建 HIP 代码,必须在 CMake 中启用 HIP 语言支持,并将 hipcc 设置为编译器,同时设置相应的编译设备标志。
enable_language(HIP)
if (${GPU_RUNTIME} MATCHES "HIP") set (VECTORADD_CXX_FLAGS "-fPIC")elseif (${GPU_RUNTIME} MATCHES "CUDA") set (VECTORADD_CXX_FLAGS "-I $ENV{ROCM_PATH}/include")else () message (FATAL_ERROR "GPU runtime not supported!")endif ()
set(CMAKE_CXX_COMPILER hipcc)
set (CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${VECTORADD_CXX_FLAGS}")set (CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} ${VECTORADD_CXX_FLAGS}")set (CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} ${VECTORADD_CXX_FLAGS} -ggdb")最后,创建一个可执行文件,并且目标必须在 AMD 和 NVIDIA 系统上与相应的运行时链接。
set (SOURCE vectorAdd_hip.cpp)
add_executable(vectoradd ${SOURCE})if (${GPU_RUNTIME} MATCHES "HIP") target_link_libraries (vectoradd "-L$ENV{ROCM_PATH}/lib" amdhip64)elseif (${GPU_RUNTIME} MATCHES "CUDA") target_link_libraries (vectoradd cudadevrt cudart_static rt)endif ()假设已安装 ROCm™ 和 CMake,可以使用 cmake 将代码配置为在 AMD GPU 上运行,并通过运行以下命令构建和启动可执行文件
mkdir build && cd buildcmake ..make./vectoradd对于旨在在 NVIDIA GPU 上运行的代码,除了 CMake 之外,还必须安装 CUDA 和 ROCm™ 堆栈。与 Make 示例类似,必须设置 HIP_PLATFORM,并且必须使用 CUDA GPU 运行时而不是默认运行时来配置代码。
mkdir build && cd buildexport HIP_PLATFORM=nvidiacmake -DCMAKE_GPU_RUNTIME=CUDA ..make./vectoradd如果在 NVIDIA 系统上未正确设置 HIP_PLATFORM,CMake 和 Make 仍会配置和构建代码,但可能会出现运行时错误,例如此错误
./vectoraddCUDA Error - vectorAdd_hip.cpp:38: 'invalid device ordinal'在 AMD 和 NVIDIA GPU 上,CMake 都会自动检测并为底层架构构建 GPU 目标。但是,在必须为不同架构构建目标的情况下,用户可以明确指定 CMAKE_HIP_ARCHITECTURES 或 CMAKE_CUDA_ARCHITECTURES。有关更多详细信息,请参阅 CMake 文档。
其他移植注意事项
在移植过程中,重要的是要检查内联 PTX 汇编代码、CUDA 内建函数、硬编码依赖项、不受支持的函数、任何限制 NVIDIA 硬件上寄存器文件大小的代码,以及 hipify 工具无法转换的任何其他结构。由于 hipify 工具不运行应用程序,因此需要手动更改任何硬编码的结构,例如将 warp 大小设置为 32。因此,建议避免硬编码 warp 大小,而是依赖 WarpSize 设备定义、#define WARPSIZE size 或 props.warpSize 从运行时获取正确的值。hipify 工具也不会转换构建脚本。设置适当的标志和路径来构建新转换的 HIP 代码必须手动完成。
在 HIP 培训系列存储库 中可以找到将 CUDA 代码转换为 HIP 的其他代码示例以及配套的可移植构建系统。
结论
我们展示了开发人员可以利用的各种 ROCm™ 工具,将他们的代码从 CUDA 转换为 HIP。这些工具极大地加快了转换过程并使其更容易。我们还通过展示使用 Make 和 CMake 的可移植构建系统的示例,说明了 HIP 最强大的功能之一,即它能够同时在 AMD 和 NVIDIA GPU 上运行。
与许多其他 GPU 编程范例不同,HIP API 是一个位于硬件层附近的轻量级接口,它使得 HIP 代码能够与 NVIDIA GPU 上的对应代码具有相同的性能。
下次
请继续关注我们在此系列中发布的更多文章,其中将涵盖更高级的主题。如果您有任何问题或意见,可以通过 GitHub Discussions 与我们联系。