AMD Schola
AMD Schola 是一个用于在 Unreal Engine 中开发强化学习 (RL) 代理并使用您喜欢的 Python 基础 RL 框架进行训练的库。
GPU 内核中的寄存器压力对您的 HPC 应用程序的整体性能有着巨大的影响。理解和控制寄存器使用情况可以使开发人员能够精心设计能够最大化利用硬件资源的 कोड。以下博客文章重点介绍了一个实用演示,展示了如何应用在此 OLCF 培训讲座(于 2022 年 8 月 23 日发表)中解释的建议。这是 培训档案,您也可以在此找到幻灯片。我们仅关注 AMD CDNA2™ 架构(MI200 系列 GPU),使用 ROCm 5.4。
通用寄存器是传统处理器中最快的内存类型。在大多数情况下,传统处理器和加速器中的 ALU(算术逻辑单元)是唯一可以访问寄存器的组件。不幸的是,寄存器是一种稀缺且昂贵的资源,编译器会尽最大努力来 *优化* 局部变量如何被分配到硬件寄存器以供 ALU 操作。
当使用“优化”一词时,我们应该始终明确优化的目标。事实上,由于其固有的性质,普通 CPU 和 GPU 等加速器有不同的执行程序和实现高性能的方式。一方面,传统 CPU 是面向延迟的,旨在尽可能多地执行单个串行线程的指令。另一方面,GPU 是面向吞吐量的,旨在尽可能多地利用独立线程之间的并行性。
在 AMD GPU 中,运行在同一计算单元 (CU) 上的大量并发波前 (wavefronts) 使 GPU 能够通过其他波前执行的操作来隐藏全局内存访问所花费的时间,因为全局内存访问时间比执行计算操作所需的时间要长。
“占用率”一词表示可以同时在同一 CU 上运行的波前最大数量。通常,较高的占用率有助于通过其他操作隐藏耗时的内存访问来实现更好的性能,但这并非总是如此。
在图 1 中,我们展示了 CDNA2 架构中 CU 的示意图。向量通用寄存器 (VGPRs) 用于存储在波前中不均匀的数据,即波前中每个工作项的数据不同。它们是 CU 中最通用的寄存器,由向量 ALU (VALU) 直接操作。VALU 负责执行 CU 中的大多数工作,包括浮点运算 (FLOPs)、内存加载、整数和逻辑运算等。
标量通用寄存器 (SGPRs) 是一组寄存器,用于存储在编译时已知在波前中均匀的数据。SGPRs 由标量 ALU (SALU) 操作,SALU 与 VALU 不同,只能用于有限的操作集,例如整数和逻辑运算。
本地数据共享 (LDS) 是一个快速的、在 CU 内部由软件管理的内存,可用于高效地在块中的所有工作项之间共享数据。
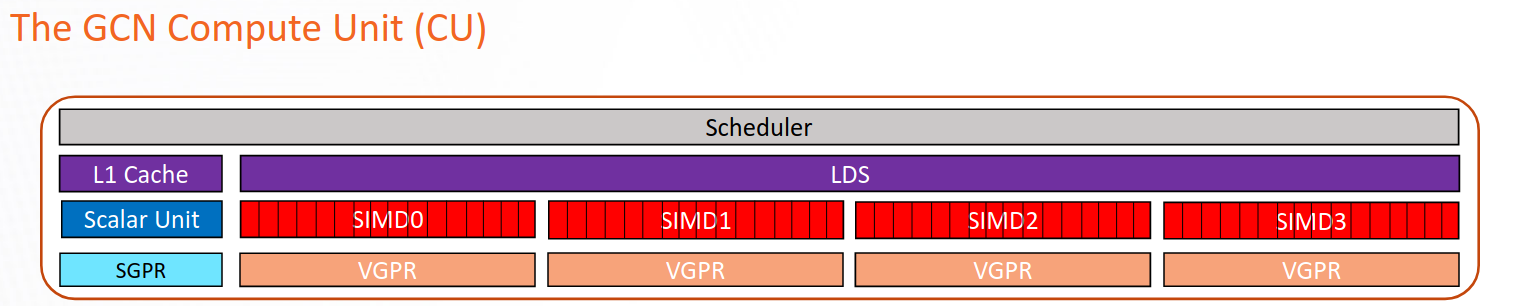
图 1:CDNA2 架构中 CU 的示意图
理想情况下,我们希望始终拥有尽可能高的占用率。实际上,占用率受到硬件设计选择和内核(HIP、OpenCL 等)在卡上运行时所决定的资源限制的制约。例如,AMD CDNA2 基于 GPU 的每个 CU 都有四组波前缓冲区,每个执行单元 (EU,在图 1 中也称为 SIMD 单元) 有一个波前缓冲区,每个 CU 有四个 EU。每个 EU 最多可以管理 **八个** 波前。这意味着 CDNA2 中占用率的物理限制是每个 CU 32 个波前。
内核所需的寄存器数量是最常见的占用率限制因素之一。另一个常见限制因素是 LDS。下表总结了 CDNA2 基于 GPU 的最大占用率水平,该水平与内核使用的 VGPR 数量有关。
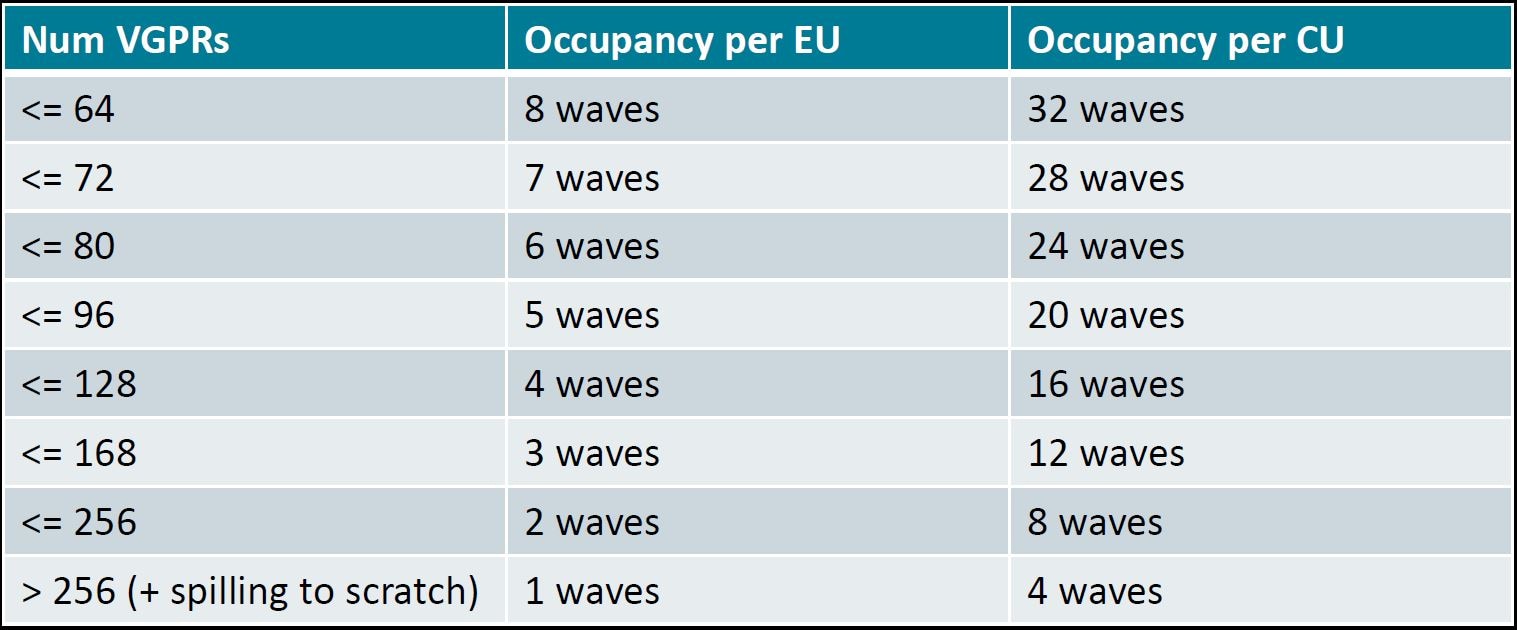
表 1:MI200 中与 VGPR 使用相关的占用率
寄存器分配是将 GPU 内核的局部变量和表达式结果分配给硬件可用寄存器的过程。它由编译器在编译时执行,并受到指令调度等其他阶段的影响。找到这个问题的最优解是 NP-Hard 的,必须采用启发式技术来在合理的时间内找到接近最优的解决方案。
编译器尝试应用启发式技术来最大化占用率,方法是减少对寄存器的需求(遵循表 1)。当请求的寄存器数量过高时,性能会受到“寄存器压力”的惩罚,导致占用率低和暂存内存使用。
有时,编译器可能会认为即使对寄存器的需求高于表 1 中报告的限制,达到更好的占用率水平也是有益的,例如,应用程序需要 134 个寄存器,但编译器只分配了 128 个,其余的存储在暂存内存中。这种更高的占用率可以通过将一些变量保存在 暂存内存 中来实现:暂存内存是本地内存的一部分,对线程是私有的,由全局内存支持,并且比寄存器内存慢得多。这种技术称为“寄存器溢出”。
虽然观察到变量被分配到暂存内存可能预示着高寄存器压力,但应在更广泛的性能背景下考虑。事实上,通过节省少量寄存器来实现更高的占用率,可能比不使用任何暂存内存的低占用率带来显著的性能提升。
当寄存器压力(对寄存器的需求)远高于可用硬件寄存器的数量时,性能将因低占用率(最坏情况下每 CU 1 个波前)和访问需要“溢出”到暂存内存的寄存器变量的高成本而受到影响。
如前所述,编译器应用启发式技术来最小化某些 GPU 内核所需的寄存器数量,从而最大化占用率。这些启发式技术有时未能接近最优解,此时需要程序员重构代码以减少寄存器压力并提高性能。
在本节中,我们将介绍如何识别寄存器压力问题以及如何缓解它。
首先,GPU 内核使用的寄存器数量可以通过两种方式检测:1)使用 ` -Rpass-analyze=kernel-resource-usage` 标志编译包含内核的文件,这将在编译时在屏幕上显示文件中每个内核的资源使用情况;其中一些信息包括 SGPRs、VGPRs、ScratchSize、VGPR/SGPR spills、Occupancy 和 LDS usage。2)使用 ` —save-temps` 编译,并在 `hip-amdgcn-amd-amdhsa-gfx90a.s` 文件中查找 `.vgpr_spill_count`。`-Rpass-analyze=kernel-resource-usage` 标志报告的所有信息也在此文件中。
一旦评估/确认了寄存器压力状况,就可以对代码应用一些技术来减少寄存器压力。
在我们接下来的讨论中,我们将重点关注以下代码
__global__ void kernel (double *phi, double *laplacian_phi, double *grad_phi_x, double *grad_phi_y, double *grad_phi_z, double *f0, double *f1, double *f2, double *f3, double *f4, double *f5, double *f6, double *g0, double *g1, double *g2, double *g3, double *g4, double *g5, double *g6, double* g7, double *g8, double *g9, double *g10, double *g11, double *g12, double *g13, double *g14, double *g15, double *g16, double *g17, double *g18, int nx, int ny, int nz, int ldx, int ldy, int current, int next, double k, double alpha, double phi2, double gamma, double itauphi, double itauphi1, double ieta, double itaurho, double grav, double eg1, double eg2, double eg0, double egc0, double egc1, double egc2){ int i = (threadIdx.x + blockIdx.x * blockDim.x); int j = (threadIdx.y + blockIdx.y * blockDim.y); int z = (threadIdx.z + blockIdx.z * blockDim.z);
int m, current_pos;
double mu_phi, current_phi, current_phi_2; double rho; double fx, fy, fz; double uf, ux, uy, uz, v; double af, ag, cf; double eg1ag, eg2ag, eg1rho, eg2rho; double tmp1, tmp2;
if(i <= nx && j <= ny && z <= nz) { m = i + ldx * (j + ldy * z); current_pos = m + current;
current_phi = phi[m]; current_phi_2 = pow(current_phi,2.0);
rho = g0[m] + g1[current_pos] + g2[current_pos] + g3[current_pos] + g4[current_pos] + g5[current_pos] + g6[current_pos] + g7[current_pos] + g8[current_pos] + g9[current_pos] + g10[current_pos] + g11[current_pos] + g12[current_pos] + g13[current_pos] + g14[current_pos] + g15[current_pos] + g16[current_pos] + g17[current_pos] + g18[current_pos];
mu_phi = alpha * current_phi * ( current_phi_2 - phi2 ) - k * laplacian_phi[m];
fx = mu_phi * grad_phi_x[m]; fy = mu_phi * grad_phi_y[m]; fz = mu_phi * grad_phi_z[m];
ux = ( g1[current_pos] - g2[current_pos] + g7[current_pos] - g8[current_pos] + g9[current_pos] - g10[current_pos] + g11[current_pos] - g12[current_pos] + g13[current_pos] - g14[current_pos] + 0.50 * fx ) * 1.0/rho; uy = ( g3[current_pos] - g4[current_pos] + g7[current_pos] - g8[current_pos] - g9[current_pos] + g10[current_pos] + g15[current_pos] - g16[current_pos] + g17[current_pos] - g18[current_pos] + 0.50 * fy ) * 1.0/rho; uz = ( g5[current_pos] - g6[current_pos] + g11[current_pos] - g12[current_pos] - g13[current_pos] + g14[current_pos] + g15[current_pos] - g16[current_pos] - g17[current_pos] + g18[current_pos] + 0.50 * fz ) * 1.0/rho;
af = 0.50 * gamma * mu_phi * itauphi; cf = itauphi * ieta * current_phi;
f0[m] = itauphi1 * f0[m] + -3.0 * gamma * mu_phi * itauphi + itauphi * current_phi;
f1[current_pos] = itauphi1 * f1[current_pos] + af + cf * ux; f2[current_pos] = itauphi1 * f2[current_pos] + af - cf * ux; f3[current_pos] = itauphi1 * f3[current_pos] + af + cf * uy; f4[current_pos] = itauphi1 * f4[current_pos] + af - cf * uy; f5[current_pos] = itauphi1 * f5[current_pos] + af + cf * uz; f6[current_pos] = itauphi1 * f6[current_pos] + af - cf * uz;
ag = 3.0 * current_phi * mu_phi + rho; eg1ag = eg1 * ag; eg2ag = eg2 * ag; eg1rho = eg1 * rho; eg2rho = eg2 * rho; v = 1.50 * ( ux*ux + uy*uy + uz*uz ); uf = ux * fx + uy * fy + uz * fz;
g0[m] = itaurho * g0[m] + eg0 * ( (rho - 6.0 * current_phi * mu_phi) - rho*v ) - egc0*uf;
tmp1 = eg1ag + eg1rho*( 0.50*ux*ux - v ) + egc1*( ux*fx - uf ); tmp2 = eg1rho*ux + egc1*fx;
g1[m+next + 1] = itaurho * g1[current_pos] + tmp1 + tmp2; g2[m+next - 1] = itaurho * g2[current_pos] + tmp1 - tmp2;
tmp1 = eg1ag + eg1rho*( 0.50 * uy * uy - v ) + egc1 * ( uy * fy - uf ); tmp2 = eg1rho * uy + egc1 * fy;
g3[m+next + ldx] = itaurho * g3[current_pos] + tmp1 + tmp2; g4[m+next - ldx] = itaurho * g4[current_pos] + tmp1 - tmp2;
tmp1 = eg1ag + eg1rho*( 0.50 * uz * uz - v ) + egc1 * ( uz * fz - uf ); tmp2 = eg1rho * uz + egc1 * fz;
g5[m+next + ldx*ldy] = itaurho * g5[current_pos] + tmp1 + tmp2; g6[m+next - ldx*ldy] = itaurho * g6[current_pos] + tmp1 - tmp2;
tmp1 = eg2ag + eg2rho * ( 0.50 * ( ux + uy ) * ( ux + uy ) - v ) + egc2 * ( ( ux + uy ) * ( fx + fy ) - uf );
tmp2 = eg2rho * ( ux + uy ) + egc2 * ( fx + fy );
g7[m+next + 1 + ldx] = itaurho * g7[current_pos] + tmp1 + tmp2; g8[m+next - 1 - ldx] = itaurho * g8[current_pos] + tmp1 - tmp2;
tmp1 = eg2ag + eg2rho * ( 0.50 * ( ux - uy ) * ( ux - uy ) - v ) + egc2 * ( ( ux - uy )*( fx - fy ) - uf ); tmp2 = eg2rho * ( ux - uy ) + egc2 * ( fx - fy );
g9[m+next + 1 - ldx] = itaurho * g9[current_pos] + tmp1 + tmp2; g10[m+next - 1 + ldx] = itaurho * g10[current_pos] + tmp1 - tmp2;
tmp1 = eg2ag + eg2rho * ( 0.50 * ( ux + uz ) * ( ux + uz ) - v ) + egc2 * ( ( ux + uz ) * ( fx + fz ) - uf ); tmp2 = eg2rho * ( ux + uz ) + egc2 * ( fx + fz );
g11[m+next + 1 + ldx*ldy] = itaurho * g11[current_pos] + tmp1 + tmp2; g12[m+next - 1 - ldx*ldy] = itaurho * g12[current_pos] + tmp1 - tmp2;
tmp1 = eg2ag + eg2rho * ( 0.50 * ( ux - uz ) * ( ux - uz ) - v ) + egc2 * ( ( ux - uz ) * ( fx - fz ) - uf ); tmp2 = eg2rho * ( ux - uz ) + egc2 * ( fx - fz );
g13[m+next + 1 - ldx*ldy] = itaurho * g13[current_pos] + tmp1 + tmp2; g14[m+next - 1 + ldx*ldy] = itaurho * g14[current_pos] + tmp1 - tmp2;
tmp1 = eg2ag + eg2rho * ( 0.50 * ( uy + uz ) * ( uy + uz ) - v ) + egc2 * ( ( uy + uz ) * ( fy + fz ) - uf ); tmp2 = eg2rho * ( uy + uz ) + egc2 * ( fy + fz );
g15[m+next + ldx + ldx*ldy] = itaurho * g15[current_pos] + tmp1 + tmp2; g16[m+next - ldx - ldx*ldy] = itaurho * g16[current_pos] + tmp1 - tmp2;
tmp1 = eg2ag + eg2rho * ( 0.50 * ( uy - uz ) * ( uy - uz ) - v ) + egc2 * ( ( uy - uz ) * ( fy - fz ) - uf ); tmp2 = eg2rho * ( uy - uz ) + egc2 * ( fy - fz );
g17[m+next + ldx - ldx*ldy] = itaurho * g17[current_pos] + tmp1 + tmp2; g18[m+next - ldx + ldx*ldy] = itaurho * g18[current_pos] + tmp1 - tmp2;
}}使用许多双精度变量来存储数学运算的临时结果和有意义的物理量,这表明此内核的性能可能会受到寄存器压力的影响。为了评估此假设,我们可以使用以下方法编译内核以获取内核资源使用情况
hipcc --offload-arch=gfx90a lbm.cpp -Rpass-analysis=kernel-resource-usage -clbm.cpp:16:1: remark: Function Name: _Z6kernelPdS_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_iiiiiiiddddddddddddddd [-Rpass-analysis=kernel-resource-usage]{^lbm.cpp:16:1: remark: SGPRs: 98 [-Rpass-analysis=kernel-resource-usage]lbm.cpp:16:1: remark: VGPRs: 102 [-Rpass-analysis=kernel-resource-usage]lbm.cpp:16:1: remark: AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]lbm.cpp:16:1: remark: ScratchSize [bytes/lane]: 0 [-Rpass-analysis=kernel-resource-usage]lbm.cpp:16:1: remark: Occupancy [waves/SIMD]: 4 [-Rpass-analysis=kernel-resource-usage]lbm.cpp:16:1: remark: SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]lbm.cpp:16:1: remark: VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]lbm.cpp:16:1: remark: LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]尽管没有寄存器溢出,但我们注意到每个 SIMD 单元的占用率仅为四个波前;这是最佳可实现情况的一半左右。查看前面显示的表 1 中的占用率表,我们可以看到,为了达到 5 个波前/SIMD 的占用率,我们需要将使用的 VGPRS 数量从 102 减少到 96 或更少。
查看以下代码,我们注意到使用了 `pow` 函数来计算 `current_phi` 变量的平方。
if(i <= nx && j <= ny && z <= nz) { m = i + ldx * (j + ldy * z); current_pos = m + current;
current_phi = phi[m]; current_phi_2 = pow(current_phi,2.0);正如我们之前提到的,编译器目前会内联所有设备函数调用,包括数学函数。一个可能的优化是将通用函数 `pow` 替换为特定于平方变量的代码,如下所示
if(i <= nx && j <= ny && z <= nz) { m = i + ldx * (j + ldy * z); current_pos = m + current;
current_phi = phi[m]; current_phi_2 = current_phi * current_phi;重新编译新代码,我们观察到我们的更改将 VGPRs 使用量从 102 减少到 100
hipcc --offload-arch=gfx90a lbm_nopow_1.cpp -Rpass-analysis=kernel-resource-usage -clbm_nopow_1.cpp:16:1: remark: Function Name: _Z6kernelPdS_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_iiiiiiiddddddddddddddd [-Rpass-analysis=kernel-resource-usage]{^lbm_nopow_1.cpp:16:1: remark: SGPRs: 98 [-Rpass-analysis=kernel-resource-usage]lbm_nopow_1.cpp:16:1: remark: VGPRs: 100 [-Rpass-analysis=kernel-resource-usage]lbm_nopow_1.cpp:16:1: remark: AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]lbm_nopow_1.cpp:16:1: remark: ScratchSize [bytes/lane]: 0 [-Rpass-analysis=kernel-resource-usage]lbm_nopow_1.cpp:16:1: remark: Occupancy [waves/SIMD]: 4 [-Rpass-analysis=kernel-resource-usage]lbm_nopow_1.cpp:16:1: remark: SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]lbm_nopow_1.cpp:16:1: remark: VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]lbm_nopow_1.cpp:16:1: remark: LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]虽然减少量可能看起来不显著,但这将为后续优化提供更大的改进空间。
一旦定义了变量,它的值就会存储在寄存器中以供将来使用。在内核开始时定义变量并在结束时使用它们会急剧增加寄存器使用量。第二个可能提供显著好处的优化是查找变量定义“远离”其首次使用的情况,并手动重新排列代码。
经过快速目视检查,我们可以看到数组位置 `f[m]` 的定义不依赖于 `ux`、`uy` 或 `uz`,与其他数组 `f1` 到 `f6` 不同。
mu_phi = alpha * current_phi * ( current_phi_2 - phi2 ) - k * laplacian_phi[m];
fx = mu_phi * grad_phi_x[m]; fy = mu_phi * grad_phi_y[m]; fz = mu_phi * grad_phi_z[m];
ux = ( g1[current_pos] - g2[current_pos] + g7[current_pos] - g8[current_pos] + g9[current_pos] - g10[current_pos] + g11[current_pos] - g12[current_pos] + g13[current_pos] - g14[current_pos] + 0.50 * fx ) * 1.0/rho; uy = ( g3[current_pos] - g4[current_pos] + g7[current_pos] - g8[current_pos] - g9[current_pos] + g10[current_pos] + g15[current_pos] - g16[current_pos] + g17[current_pos] - g18[current_pos] + 0.50 * fy ) * 1.0/rho; uz = ( g5[current_pos] - g6[current_pos] + g11[current_pos] - g12[current_pos] - g13[current_pos] + g14[current_pos] + g15[current_pos] - g16[current_pos] - g17[current_pos] + g18[current_pos] + 0.50 * fz ) * 1.0/rho;
af = 0.50 * gamma * mu_phi * itauphi; cf = itauphi * ieta * current_phi;
f0[m] = itauphi1 * f0[m] + -3.0 * gamma * mu_phi * itauphi + itauphi * current_phi;
f1[current_pos] = itauphi1 * f1[current_pos] + af + cf * ux; f2[current_pos] = itauphi1 * f2[current_pos] + af - cf * ux; f3[current_pos] = itauphi1 * f3[current_pos] + af + cf * uy; f4[current_pos] = itauphi1 * f4[current_pos] + af - cf * uy; f5[current_pos] = itauphi1 * f5[current_pos] + af + cf * uz; f6[current_pos] = itauphi1 * f6[current_pos] + af - cf * uz;将 `f[m]` 的定义移至 `ux` 定义之前
mu_phi = alpha * current_phi * ( current_phi_2 - phi2 ) - k * laplacian_phi[m];
f0[m] = itauphi1 * f0[m] + -3.0 * gamma * mu_phi * itauphi + itauphi * current_phi;
fx = mu_phi * grad_phi_x[m]; fy = mu_phi * grad_phi_y[m]; fz = mu_phi * grad_phi_z[m];
ux = ( g1[current_pos] - g2[current_pos] + g7[current_pos] - g8[current_pos] + g9[current_pos] - g10[current_pos] + g11[current_pos] - g12[current_pos] + g13[current_pos] - g14[current_pos] + 0.50 * fx ) * 1.0/rho; uy = ( g3[current_pos] - g4[current_pos] + g7[current_pos] - g8[current_pos] - g9[current_pos] + g10[current_pos] + g15[current_pos] - g16[current_pos] + g17[current_pos] - g18[current_pos] + 0.50 * fy ) * 1.0/rho; uz = ( g5[current_pos] - g6[current_pos] + g11[current_pos] - g12[current_pos] - g13[current_pos] + g14[current_pos] + g15[current_pos] - g16[current_pos] - g17[current_pos] + g18[current_pos] + 0.50 * fz ) * 1.0/rho;
af = 0.50 * gamma * mu_phi * itauphi; cf = itauphi * ieta * current_phi;
f1[current_pos] = itauphi1 * f1[current_pos] + af + cf * ux; f2[current_pos] = itauphi1 * f2[current_pos] + af - cf * ux; f3[current_pos] = itauphi1 * f3[current_pos] + af + cf * uy; f4[current_pos] = itauphi1 * f4[current_pos] + af - cf * uy; f5[current_pos] = itauphi1 * f5[current_pos] + af + cf * uz; f6[current_pos] = itauphi1 * f6[current_pos] + af - cf * uz;我们注意到新的 VGPRs 使用量为 96,这使我们达到了更好的占用率水平:五个波前/SIMD
hipcc --offload-arch=gfx90a lbm_rearrage_2.cpp -Rpass-analysis=kernel-resource-usage -clbm_rearrage_2.cpp:16:1: remark: Function Name: _Z6kernelPdS_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_iiiiiiiddddddddddddddd [-Rpass-analysis=kernel-resource-usage]{^lbm_rearrage_2.cpp:16:1: remark: SGPRs: 94 [-Rpass-analysis=kernel-resource-usage]lbm_rearrage_2.cpp:16:1: remark: VGPRs: 96 [-Rpass-analysis=kernel-resource-usage]lbm_rearrage_2.cpp:16:1: remark: AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]lbm_rearrage_2.cpp:16:1: remark: ScratchSize [bytes/lane]: 0 [-Rpass-analysis=kernel-resource-usage]lbm_rearrage_2.cpp:16:1: remark: Occupancy [waves/SIMD]: 5 [-Rpass-analysis=kernel-resource-usage]lbm_rearrage_2.cpp:16:1: remark: SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]lbm_rearrage_2.cpp:16:1: remark: VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]lbm_rearrage_2.cpp:16:1: remark: LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]在 C++ 等 C 类语言中,别名是实现高性能的主要限制之一。为了避免这个问题,C99 标准引入了“受限指针”:一种用户告诉编译器不同对象指针类型和函数参数数组不指向重叠内存区域的方式。这允许编译器执行积极的优化,否则这些优化可能因别名而受阻。受限指针的使用 *可能* 会增加寄存器压力,因为编译器会尝试通过将数据存储在寄存器中来重用更多数据。在 AMD 硬件上,情况并非总是如此,有时使用 `restrict` 有助于减少 SGPRs 和 VGPRs 的压力。经验法则是,在函数参数上使用 `restrict` 倾向于减少 SGPRs 使用量,并有可能增加 VGPRs 使用量。
例如,让我们向 `g14` 数组添加 `restrict` 关键字,因为它在代码的其余部分被重复使用,并且我们可能从重用中获得更高的性能。
__global__ void kernel (double * phi, double * laplacian_phi, double * grad_phi_x, double * grad_phi_y, double * grad_phi_z, double * f0, double * f1, double * f2, double * f3, double * f4, double * f5, double * f6, double * g0, double * g1, double * g2, double * g3, double * g4, double * g5, double * g6, double* g7, double * g8, double * g9, double * g10, double * g11, double * g12, double * g13, double * __restrict__ g14, double * g15, double * g16, double * g17, double * g18, int nx, int ny, int nz, int ldx, int ldy, int current, int next, double k, double alpha, double phi2, double gamma, double itauphi, double itauphi1, double ieta, double itaurho, double grav, double eg1, double eg2, double eg0, double egc0, double egc1, double egc2)结果是 SGPRs 和 VGPRs 的寄存器压力降低
lbm_2_restrict.cpp:16:1: remark: Function Name: _Z6kernelPdS_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_iiiiiiiddddddddddddddd [-Rpass-analysis=kernel-resource-usage]{^lbm_2_restrict.cpp:16:1: remark: SGPRs: 86 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: VGPRs: 94 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: ScratchSize [bytes/lane]: 0 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: Occupancy [waves/SIMD]: 5 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]通过向变量 `g7` 添加 `restrict`,我们观察到 SGPRs 使用量进一步减少,VGPRs 使用量略有增加,但占用率仍保持在 5 个波前/SIMD
lbm_2_restrict.cpp:16:1: remark: Function Name: _Z6kernelPdS_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_S_iiiiiiiddddddddddddddd [-Rpass-analysis=kernel-resource-usage]{^lbm_2_restrict.cpp:16:1: remark: SGPRs: 78 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: VGPRs: 96 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: ScratchSize [bytes/lane]: 0 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: Occupancy [waves/SIMD]: 5 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]lbm_2_restrict.cpp:16:1: remark: LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]在本博文中,我们从高层次上描述了寄存器压力对于在 AMD CDNA2 架构上运行的 HPC 应用程序和算法的性质和后果。我们还提供了一组被发现能有效减少寄存器压力并提高占用率的规则。需要强调的是,本博文中展示的结果只能在 AMD CDNA2 基于 GPU 和 ROCm 5.4 的情况下完全复制。编译器及其启发式算法的不断变化可能在不同 ROCm 版本下改变此博文中代码示例的结果。我们鼓励读者尝试使用代码示例,并针对不同的 ROCm 版本评估每次更改后的性能。
如果您有任何问题或评论,请在 GitHub 讨论区 与我们联系