AMD Radeon™ GPU Profiler
AMD RGP 让您能够前所未有地深入了解 GPU。轻松分析图形、异步计算使用情况、事件计时、管线停顿、屏障、瓶颈和其他性能低效之处。
仅仅让代码在功能上正确并不总是足够。在许多行业中,还需要应用程序及其复杂的软件堆栈尽可能高效地运行,以满足运营需求。随着硬件的不断发展,这一点尤其具有挑战性,因此代码可能需要进一步调整。实践中,许多应用程序开发者会构建精心设计的基准测试,以在类似运营的环境中衡量特定代码的性能,例如执行时间。换句话说:一个好的基准测试应该能够代表实际需要完成的工作。这些基准测试很有用,因为它们能深入了解应用程序的特性,并能发现可能导致在运营环境中性能下降的潜在瓶颈。
表面上看,基准测试听起来足够简单,通常被解释为仅仅是在各种不同机器上进行执行时间的比较。然而,为了从新兴硬件中提取最大的性能,程序必须经过多次调优,并且需要的不仅仅是衡量原始执行时间:需要知道程序大部分时间花在哪里,以及是否可以进一步改进。异构系统,即程序在 CPU 和 GPU 上运行的系统,会带来额外的复杂性。理解关键路径和内核执行变得更加重要。因此,性能调优是基准测试过程中必不可少的一部分。
通过 AMD 的性能剖析工具,开发者能够深入了解应用程序对硬件的利用效率,并有效地诊断可能导致性能下降的潜在瓶颈。针对 AMD GPU 的开发者可以根据其特定的性能剖析需求选择多种工具。本文旨在介绍 AMD 提供的各种性能剖析工具,以及开发者为何要选择其中一个。本文涵盖了从底层性能剖析工具到广泛的性能剖析套件。
在本入门博文中,我们将简要介绍以下有助于应用程序分析的工具:
本博文使用的术语如下:
术语 | 描述 |
|---|---|
AMD 的 x86-64 处理器核心架构设计。用于 AMD EPYC™、AMD Ryzen™、AMD Ryzen™ PRO 和 AMD Threadripper™ PRO 处理器系列。 | |
AMD 的传统 GPU 架构,针对游戏和可视化等图形密集型工作负载进行了优化。包括 RX 5000、6000 和 7000 系列 GPU。 | |
AMD 的计算专用 GPU 架构,针对加速 HPC、ML/AI 和数据中心类型工作负载进行了优化。包括 AMD Instinct™ MI50/60、MI100 和 MI200 系列加速器。 | |
一个 C++ 运行时 API 和内核语言,允许开发者从单一源代码为 AMD 和 NVIDIA GPU 创建可移植的计算内核/应用程序 | |
一种性能剖析方法,收集并可视化计算内核的持续时间和设备之间的数据传输 | |
一种与硬件无关的方法,用于量化工作负载在浮点计算和内存带宽方面饱和给定计算架构的能力 | |
硬件计数器 | 单个指标,用于跟踪硬件中特定事件发生的次数,例如从 L2 缓存移动的字节数或执行的 32 位浮点加法 |
性能剖析的第一步是确定适合任务的工具。无论用户是想在 CPU、GPU 还是两者上收集跟踪信息,还是想了解内核行为,或者评估内存访问模式,对于 AMD 硬件的新用户来说,执行这种分析似乎都很令人生畏。我们首先识别 AMD 提供的每种性能剖析工具所支持的架构和操作系统。几乎表 1 中的所有工具都支持 Linux® 发行版,并且随着 Instinct™ GPU 的流行,每种工具都具备一定能力来剖析在 CDNA™ 架构上运行的代码。但是,那些偏爱 Windows 的用户将仅限于使用 AMD uProf 来剖析针对 AMD “Zen” 系列处理器和 AMD Instinct™ GPU 的 CPU 和 GPU 代码,以及 Radeon™ GPU Profiler,后者可以提供宝贵的见解来优化应用程序在 RDNA™ 系列 GPU 上对图形管道(光栅化、着色器等)的使用。
AMD 性能剖析工具 | AMD “Zen” 核心 | RDNA™ | CDNA™ | Windows | Linux® |
|---|---|---|---|---|---|
ROC-profiler | 不支持 | ☆ | ★ | 不支持 | ★ |
Omniperf | 不支持 | 不支持 | ★ | 不支持 | ★ |
Omnitrace | ★ | ☆ | ★ | 不支持 | ★ |
Radeon™ GPU Profiler | 不支持 | ★ | ☆ | ★ | ☆ |
AMD | ★ | 不支持 | ☆ | ★ | ☆ |
★ 完全支持 | ☆ 部分支持
表 1:性能剖析器/架构支持和操作系统需求。
在任何平台上最终选择哪种工具取决于性能剖析的目标和所需的分析类型。为了简化,我们鼓励用户根据图 1 中的流程图所示的三个问题来思考他们的目标:
我应该把时间花在哪里?:无论是对新应用程序进行基准测试,还是开始使用尚未进行性能剖析的新软件包,建议首先识别应用程序中可能受益于快速优化的热点。在这种情况下,最好用户通过收集应用程序的时间线和跟踪信息来开始。在 Linux® 平台上,Omnitrace 可以收集 CPU 和 GPU 跟踪以及调用堆栈样本,以帮助识别主要热点。然而,在 Windows 上,用户可能需要在 AMD uProf 和 Radeon™ GPU Profiler 之间进行选择,具体取决于目标架构。
我如何有效地利用硬件?:第一步是获得工作负载的特征分析,以一窥硬件的利用情况。例如,识别应用程序中哪些部分受内存或计算限制。这可以通过 Roofline 分析来完成。通常,热点是容易理解的,并且人们通常感兴趣的是识别少数关键内核或子例程的性能。目前,Roofline 分析仅通过 AMD Instinct™ GPU 上的 Omniperf 和 AMD “Zen” 系列处理器上的 AMD uProf 提供。
为什么我会看到这样的性能?:一旦确定了热点并完成了对特定硬件上性能的初步评估,下一阶段可能涉及性能剖析并收集硬件指标,以了解观察到的性能来自何处。在 AMD GPU 上,像 Omnitrace、Omniperf 和 AMD uProf 这样的工具会与低级 ROC-profiler API 进行交互,并且/或者在后台使用 rocprof 来收集 GPU 指标。我们不建议直接使用 rocprof,因为处理文本/CSV 文件和硬件特定指标会带来额外的开销,除非有特定需求。在 Windows 系统上,用户将不得不依赖于使用 AMD uProf 或 Radeon™ GPU Profiler。
快速提示:Omni* 工具套件(Omniperf 和 Omnitrace),在 Linux® 平台上可用,提供了一个易于使用的界面来研究代码在 AMD 硬件上的性能,并应被视为性能调优和基准测试的“首选”性能剖析工具。
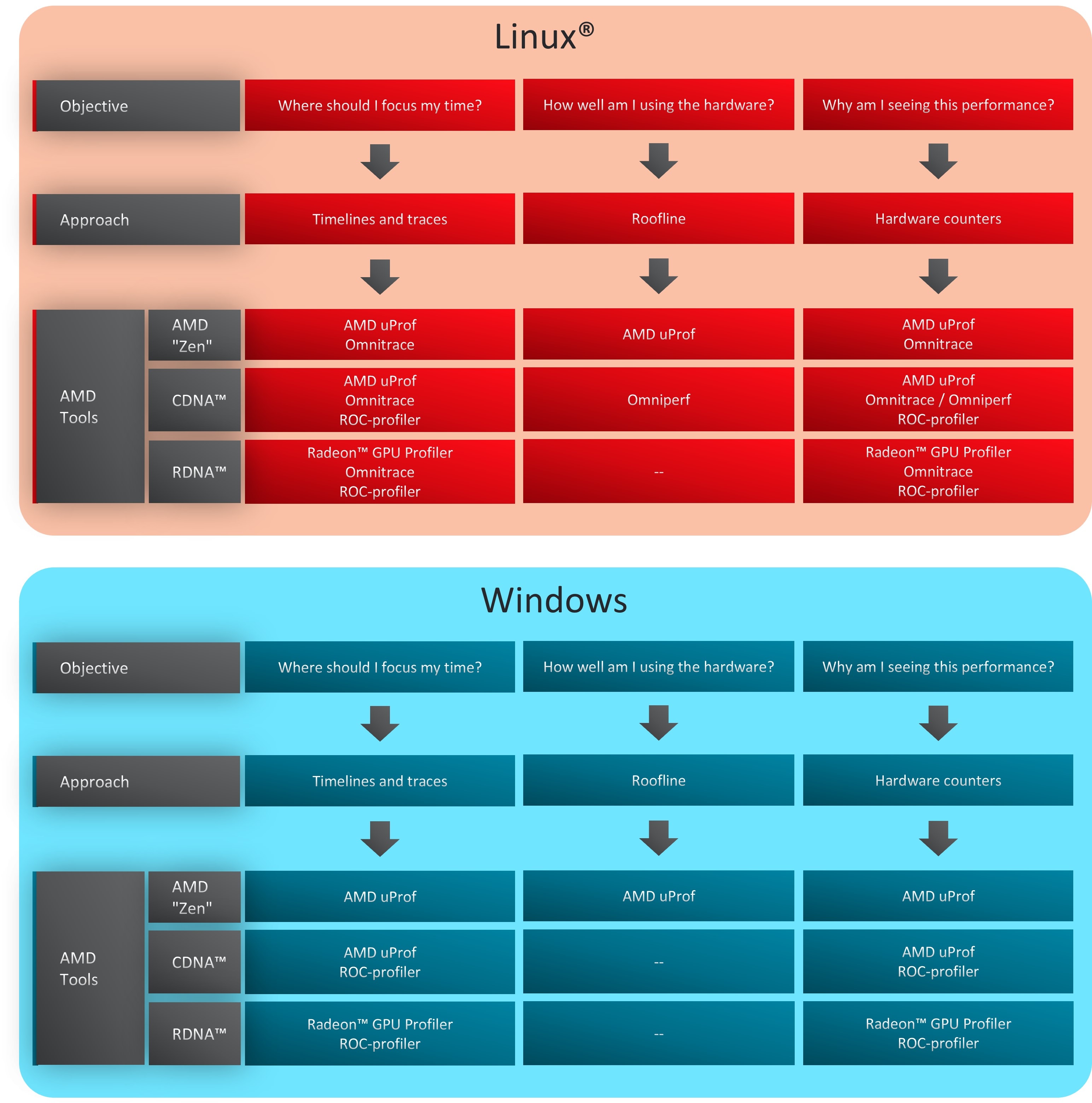
图 1:各种 AMD 性能剖析工具的用例。
在本节中,我们将简要介绍上述 AMD 工具和一些第三方工具包。
Omnitrace 是一个全面的性能剖析和跟踪工具,适用于并行应用程序,包括用 C、C++、Fortran、HIP、OpenCL™ 和 Python™ 编写的、在 CPU 或 CPU+GPU 上执行的 HPC 和 ML 包。它能够通过二进制插桩、调用堆栈采样、用户定义区域和 Python™ 解释器钩子等任意组合来收集函数的性能信息。Omnitrace 支持在 Web 浏览器中对全面的跟踪进行交互式可视化,以及提供带有平均/最小/最大/标准差统计信息的高级摘要配置文件。除了运行时信息,Omnitrace 还支持收集系统级指标,例如 CPU 频率、GPU 温度和 GPU 利用率。进程和线程级指标,如内存使用情况、页面错误、上下文切换以及众多其他硬件计数器也包含在内。
在分析应用程序性能时,最好不要假设您知道性能瓶颈在哪里以及它们为什么会发生。Omnitrace 是表征优化对应用程序端到端执行影响最大的地方,以及/或查看性能瓶颈期间系统中发生的其他事情的理想工具。
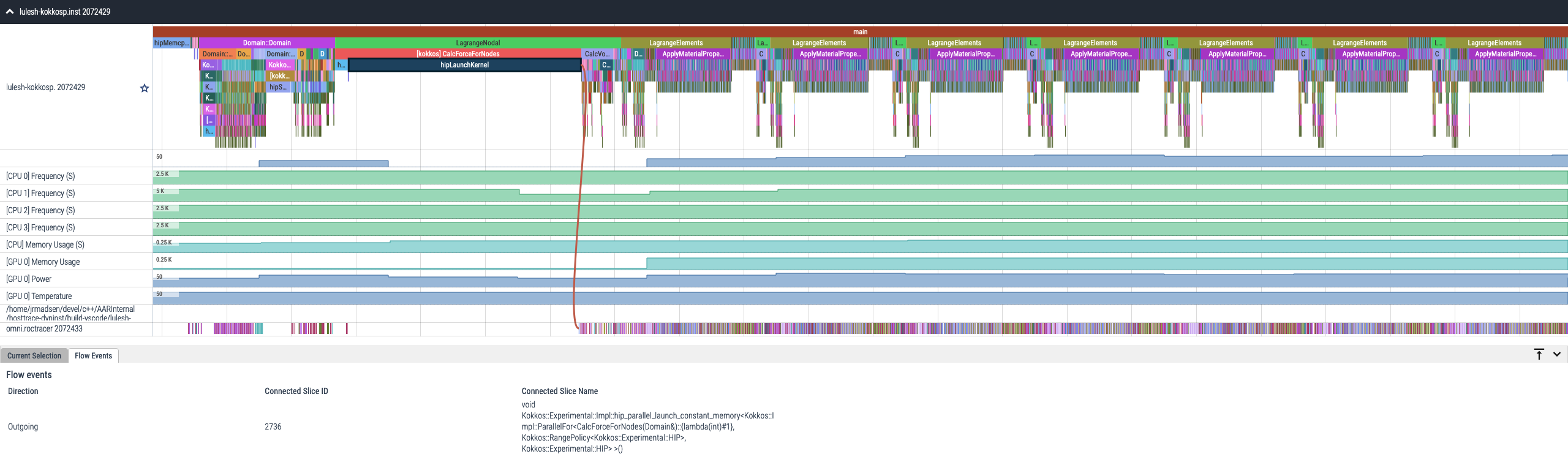
图 2:Omnitrace 时间线跟踪示例。
有关最新信息,请参阅 官方 Omnitrace 文档。鼓励用户提交 问题、功能请求,并提供任何其他反馈。
Omniperf 是一个系统性能剖析器,用于使用 AMD Instinct™ GPU 的高性能计算 (HPC) 和机器学习 (ML) 工作负载。Omniperf 使用 AMD ROC-profiler 来收集硬件性能计数器。Omniperf 工具基于 AMD Instinct™ MI200 和 MI100 架构的所有批准的硬件计数器执行系统剖析。它提供高级性能分析功能,包括系统光速、IP 块光速、内存图表分析、Roofline 分析、基线比较等。
Omniperf 通过消除提供包含计数器列表的文本输入文件以及分析原始 CSV 输出文件(ROC-profiler 的情况)的需要,消除了性能剖析中的猜测。相反,Omniperf 在一个命令中自动化了所有可用硬件计数器的收集,并提供图形界面,帮助用户理解和分析其在 AMD Instinct™ GPU 上的计算工作负载的瓶颈和压力源。请注意,Omniperf 会在多个通道中收集硬件计数器,因此在每个通道中会重新运行应用程序以收集不同的指标集。
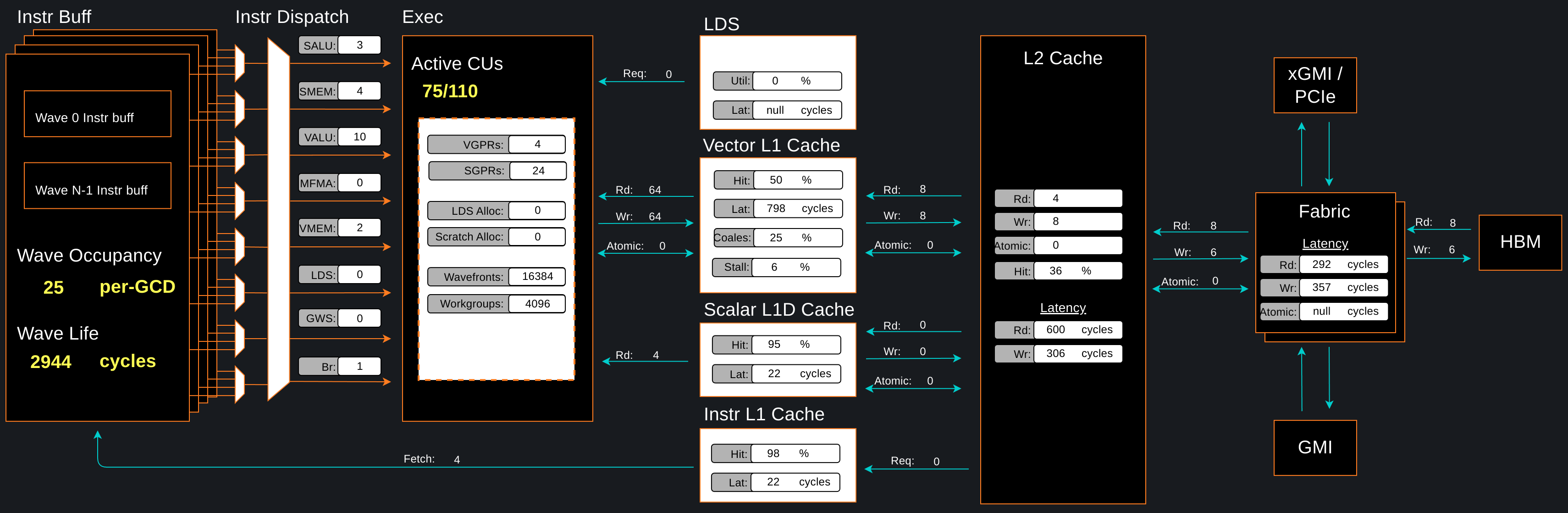
图 3:Omniperf 内存图表分析面板。
总而言之,Omniperf 提供了关于特定 GPU 内核硬件活动的详细信息。它还支持基于 Web 的 GUI 或命令行分析器,具体取决于用户的偏好。有关可用 Omniperf 功能的最新信息,我们强烈建议读者查阅 官方 Omniperf 文档。鼓励用户提交 问题、功能请求,我们欢迎社区的贡献和反馈。
ROC-profiler 主要作为访问和提取 GPU 硬件性能指标(也通常称为性能计数器)的低级 API。这些计数器量化了底层架构的性能,展示了计算管道和内存层次结构中的哪些部分正在被利用。一个名为 rocprof 的脚本/可执行命令随 ROCm™ 安装包一起提供,它提供了列出特定 GPU 可用的所有硬件计数器的功能,以及运行应用程序并在执行期间收集计数器。
rocprof 工具还依赖于 ROC-tracer 和 ROC-TX 库,使其能够收集 GPU 软件堆栈的时间线跟踪以及用户注释的代码区域。请注意,rocprof 是一个纯命令行实用程序,因此输入和输出采用 txt 和 CSV 文件格式。这些格式提供了数据的原始视图,并将解析和分析数据的负担转嫁给用户。因此,rocprof 为用户提供了对原始性能剖析数据的完全访问和控制,但分析收集到的数据需要额外的努力。
Radeon™ GPU Profiler 是一个性能工具,传统游戏和可视化开发者可以使用它来优化 DirectX 12 (DX12) 和 Vulkan™ 在 AMD RDNA™ 硬件上的性能。Radeon™ GPU Profiler (RGP) 是 AMD 的一项开创性低级优化工具。它使用自定义的、内置的硬件线程跟踪功能,提供 Radeon™ 图形的详细计时信息,使开发者能够深入检查 GPU 工作负载。这个独特的工具可以生成易于理解的可视化,展示您的 DX12 和 Vulkan™ 游戏在硬件层面如何与 GPU 交互。使用 Radeon™ Developer Panel 和公共显示驱动程序,对游戏进行性能剖析是一个快速而简单的过程。
请注意,Radeon™ GPU Profiler 也支持 OpenCL™ 和 HIP 应用程序,但它需要在 Windows 环境下的 AMD RDNA™ GPU 上运行。在 Windows 环境下运行 HIP 和 OpenCL™ 本身就是一个系列博文的主题,并且超出了当前对 HPC 应用程序的建议范围。对于 HPC 工作负载,我们建议在 Linux® 环境下的 AMD Instinct™ GPU 上使用 HIP 进行编程,并在这些 GPU 上使用 Omniperf、Omnitrace 或 ROC-profiler 性能剖析工具。
AMD uProf (AMD MICRO-prof) 是一个用于在 Windows、Linux® 和 FreeBSD 操作系统上运行的 x86 应用程序的软件性能剖析分析工具,并提供 AMD “Zen” 系列处理器和 AMD Instinct™ MI 系列加速器特有的事件信息。AMD uProf 使开发者能够更好地理解应用程序性能的限制因素并评估改进。
AMD uProf 提供:
性能分析,用于识别应用程序的运行时性能瓶颈
系统分析,用于监控系统性能指标
Roofline 分析
功耗剖析,用于监控系统的热和功耗特性
能耗分析,用于识别应用程序中的能耗热点(仅限 Windows)
远程剖析,用于从 Windows 主机连接到远程 Linux® 系统(在 Windows 主机系统上),触发远程系统上的数据收集/转换并将在本地 GUI 中报告
AMD uProf 3.6 为 AMD Instinct™ MI100 和 MI200 系列设备提供了对 AMD CDNA™ 加速器的初步支持,并且新功能正在开发中。
在高性能计算领域,许多第三方性能剖析工具已经启用了对 ROCm™ 和 AMD Instinct™ GPU 的支持。这为用户提供了一个平台,可以采用独立于供应商的方法进行性能剖析,提供易于使用的高级功能套件,这些套件可能为多种架构提供统一的性能剖析体验。对于已经熟悉这些工具的用户来说,这是了解他们在 AMD 硬件上工作负载性能的另一个便捷切入点。
目前可用的第三方性能剖析工具包括:
CrayPat(*仅适用于 CrayOS 平台*)
敬请关注,我们将发布一系列后续博文,深入介绍设置和使用这些可用工具的细节。并附带示例!
如果您有任何问题或评论,请在 GitHub 讨论区 与我们联系